






文章目录
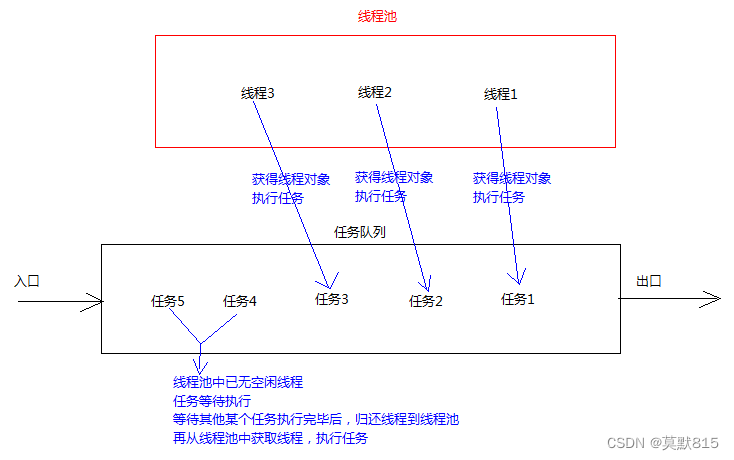
线程池
创建和销毁一个进程很耗费资源,所以就有了线程池的存在
数据库连接池(原理和线程池是一样的):C3P0
传统JDBC的操作,每次创建和销毁连接都是非常消耗系统资源的两个过程,影响程序的运行效率!
连接管理: 为了解决性能问题,可以使用连接池优化的程序,来共享链接Connection
预先创建一组连接,放入到连接池中,用的时候每次取出一个; 用完后,放回;
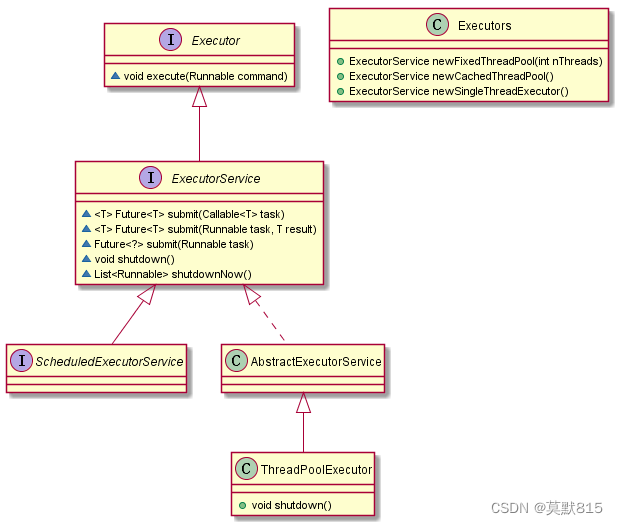

Executors 提供四种线程池:
1)newCachedThreadPool 线程池根据需求创建线程,可扩容,遇强则强(银行一共7个窗口,只开放了3个窗口,其他4个窗口没有开放,如果人很多就要开放其余的窗口,高峰结束再恢复到3个窗口状态)
创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程.
特点:
1、线程池中数量没有固定,可达到最大值(Interger. MAX_VALUE)
2、线程池中的线程可进行缓存重复利用和回收(回收默认时间为 1 分钟)
3、当线程池中,没有可用线程,会重新创建一个线程
场景: 适用于创建一个可无限扩大的线程池,服务器负载压力较轻,执行时间较短,任务多的场景
2)newSingleThreadExecutor 一个任务一个任务执行,一池一线程(例如窗口只能服务一个人,后面来的只能等待)
创建是一个单线程池,也就是该线程池只有一个线程在工作,所有的任务是串行执行的,如果这个唯一的线程因为异常结束,那么会有一个新的线程来替代它,
此线程池保证所有任务的执行顺序按照任务的提交顺序执行。
特点: 线程池中最多执行 1 个线程,之后提交的线程活动将会排在队列中以此执行
场景: 适用于需要保证顺序执行各个任务,并且在任意时间点,不会同时有多个线程的场景
3)newFixedThreadPool (int) 一池N线程
创建固定大小的线程池,每次提交一个任务就创建一个线程,直到线程达到线程池的最大大小,线程池的大小一旦达到最大值就会保持不变。
特征:
1、线程池中的线程处于一定的量,可以很好的控制线程的并发量
2、线程可以重复被使用,在显示关闭之前,都将一直存在
3、超出一定量的线程被提交时候需在队列中等待
场景: 适用于可以预测线程数量的业务中,或者服务器负载较重,对线程数有严格限制的场景
4)newScheduledThreadPool (了解)
创建一个大小无限的线程池,此线程池支持定时以及周期性执行任务的需求。
场景: 适用于需要多个后台线程执行周期任务的场景
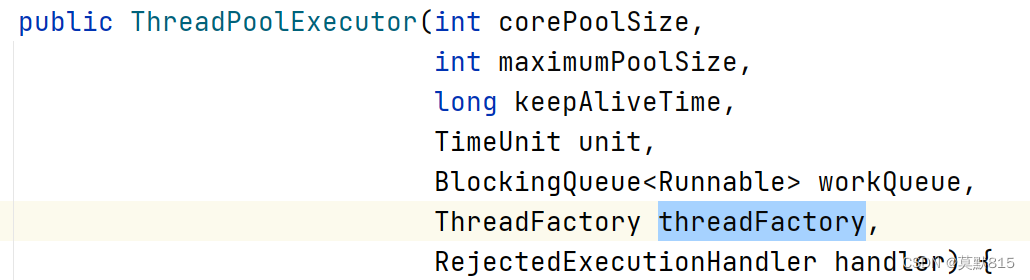
参数介绍
1)int corePoolSize:3 线程池的核心线程数(常驻线程数)
线程池的核心线程数(常驻线程数),一般情况下不管有没有任务都会一直在线程池中一直存活
2)int maximumPoolSize: 7 线程池所能容纳的最大线程数
线程池所能容纳的最大线程数,当活动的线程数达到这个值后,后续的新任务将会被阻塞。
3)long keepAliveTime:4 线程闲置时的超时时长
控制线程闲置时的超时时长,超过则终止该线程。一般情况下用于非核心线程
4)TimeUnit unit: 时间单位
用于指定 keepAliveTime 参数的时间单位,TimeUnit 是个 enum 枚举类型,常用的有:TimeUnit.HOURS(小时)、TimeUnit.MINUTES(分钟)、TimeUnit.SECONDS(秒) 和 TimeUnit.MILLISECONDS(毫秒)等。
5)BlockingQueue workQueue:任务队列(阻塞队列)
当核心线程数达到最大时,新任务会放在任务队列中排队等待执行。
6)threadFactory:线程工厂
线程工厂,它是一个接口,用来为线程池创建新线程的。
7)RejectedExecutionHandler RejectedExecutionHandler handler: 拒绝策略(银行有7个窗口,核心是3个窗口,所有窗口都开放,等待的座位也坐满了,银行再来新的顾客,银行没有能力接受新的顾客,银行就要做一个拒绝策略,建议去别的银行)
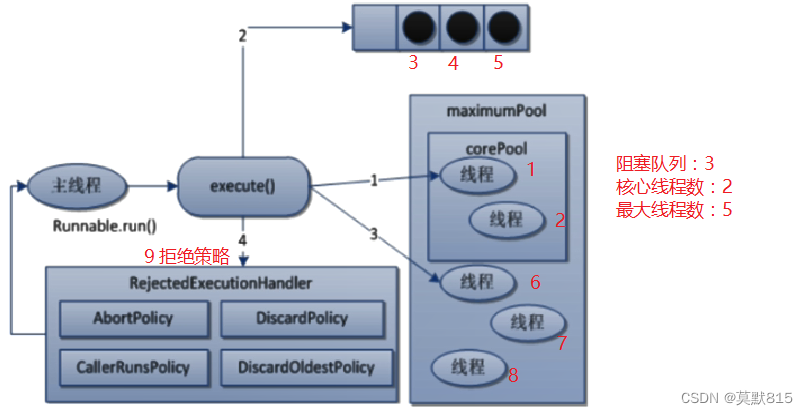
数字表示顺序
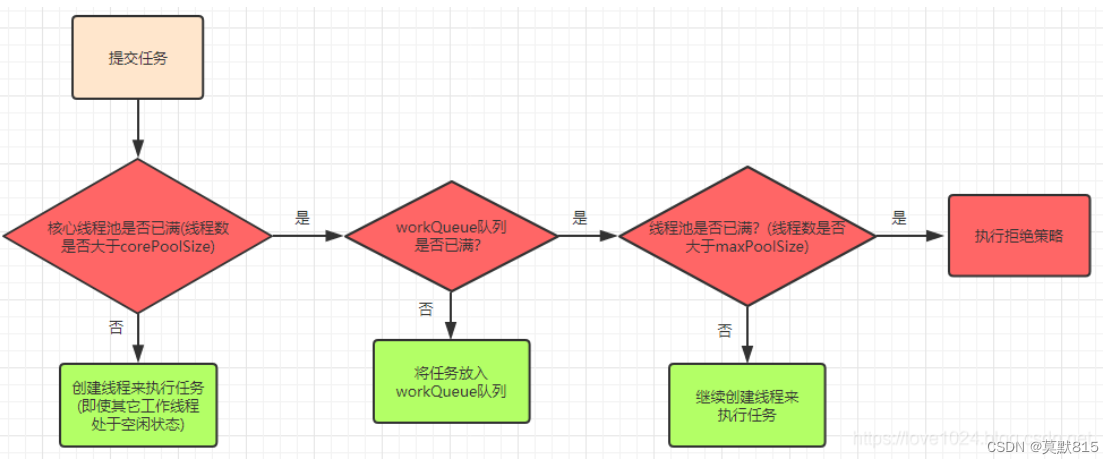
说明
1、在创建了线程池后,线程池中的线程数为零
2、当调用 execute()方法添加一个请求任务时,线程池会做出如下判断:
2.1 如果正在运行的线程数量小于 corePoolSize,那么马上创建线程运行这个任务;
2.2 如果正在运行的线程数量大于或等于 corePoolSize,那么将这个任务放入队列;
2.3 如果这个时候队列满了且正在运行的线程数量还小于maximumPoolSize,那么还是要创建非核心线程立刻运行这个任务;
2.4 如果队列满了且正在运行的线程数量大于或等于 maximumPoolSize,那么线程池会启动饱和拒绝策略来执行。
当提交的任务数大于(workQueue.size() +maximumPoolSize ),就会触发线程池的拒绝策略。
3、当一个线程完成任务时,它会从队列中取下一个任务来执行
4、当一个线程无事可做超过一定的时间(keepAliveTime)时,线程会判断:
4.1 如果当前运行的线程数大于 corePoolSize,那么这个线程就被停掉。
4.2 所以线程池的所有任务完成后,它最终会收缩到 corePoolSize 的大小。
线程池代码
public class ThreadPoolDemo1 {
public static void main(String[] args) {
//一池五线程
ExecutorService threadPool = Executors.newFixedThreadPool(5); //5个窗口
//一池一线程
//ExecutorService threadPool = Executors.newSingleThreadExecutor(); //一个窗口
//一池可扩容线程
//ExecutorService threadPool = Executors.newCachedThreadPool();
//10个顾客请求
try {
for (int i = 1; i <=10; i++) {
final int index = i;
//线程池执行调用execute方法
threadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+" 为第"+index+"个客户办理业务");
}
});
}
}catch (Exception e) {
e.printStackTrace();
}finally {
//线程池的关闭调用shutdown方法
threadPool.shutdown();
}
}
}
自定义线程池:
//自定义线程池创建
public class ThreadPoolDemo2 {
public static void main(String[] args) {
ExecutorService threadPool = new ThreadPoolExecutor(
2,
5,
2L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<>(3),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.AbortPolicy()
);
//10个顾客请求
try {
for (int i = 1; i <=10; i++) {
final int index = i;
//执行
threadPool.execute(new Runnable() {
@Override
public void run() {
System.out.println(Thread.currentThread().getName()+" 为第"+index+"个客户办理业务");
}
});
}
}catch (Exception e) {
e.printStackTrace();
}finally {
//关闭
threadPool.shutdown();
}
}
JUC
并发:高并发像秒杀一样,多个线程去访问同一个资源
并行:多个事情一路并行去做,比如说我正在泡方便面,一边用热水器去烧热水,一边并行的动作拆方便面的调料包。
Callable
Callable与Runnable区别:
1、可以有返回值
2、可以抛出异常
3、方法不同,分别是call()和run()
接口为 public interface Callable<泛型>
public class CallableDemo {
public static void main(String[] args) throws ExecutionException, InterruptedException {
MyCallable myCallable = new MyCallable();
// 需要适配类和Thread建立关联
FutureTask<String> futureTask = new FutureTask<String>(myCallable);
Thread thread = new Thread(futureTask, "CallableDemo");
thread.start();
String str = futureTask.get();
System.out.println(str);
}
}
class MyCallable implements Callable<String>{
@Override
public String call() throws Exception {
System.out.println("MyCallable.call");
return "abc";
}
}
Lock锁
卖票案例:
public class SyncSaleTicket {
public static void main(String[] args) {
Ticket ticket = new Ticket();
// 多个线程同时访问同一个资源,把资源放入线程
new Thread(new Runnable() {
@Override
public void run() {
for(int i = 0; i < 40; i++) {
ticket.sale();
}
}
}, "a").start();
new Thread(new Runnable() {
@Override
public void run() {
for(int i = 0; i < 40; i++) {
ticket.sale();
}
}
}, "b").start();
new Thread(new Runnable() {
@Override
public void run() {
for(int i = 0; i < 40; i++) {
ticket.sale();
}
}
}, "c").start();
}
}
// 资源类
class Ticket {
private int ticketNum = 30;
// 卖票
public void sale() {
if (this.ticketNum > 0) {
System.out.println(Thread.currentThread().getName() + "购得第" + ticketNum-- + "张票, 剩余" + ticketNum + "张票");
//增加错误的发生几率
try {
Thread.sleep(10);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
}
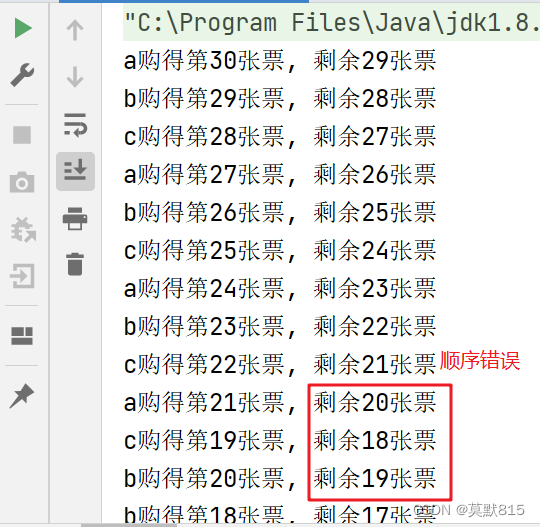
多进程同时访问资源会出错,需要加锁但是传统的synchronized缺少灵活性,所以用了Lock锁
Lock l…
l.lock();
try{
//access the resource protected by yhis lock
}finally{
l.unlock();
}
公平锁和非公平锁
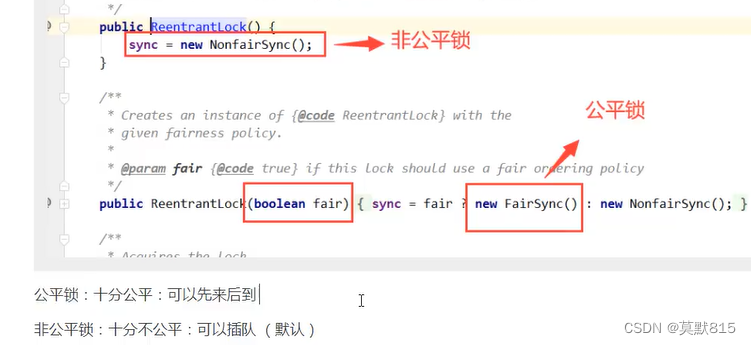 true是公平锁,false是非公平锁
true是公平锁,false是非公平锁
为什么默认是非公平锁,如果有两个线程一个3s一个3h,3s在3h后面,那样3s的虽然执行时间很短也要等3h才能执行。
// 资源类
class Ticket {
private int ticketNum = 30;
// 1、创建锁
private Lock lock = new ReentrantLock();
public void sale() {
// 2、加锁
lock.lock();
try {
// 3、access the resource protected by the lock
// 业务代码
if (this.ticketNum > 0) {
System.out.println(Thread.currentThread().getName() + "购得第" + ticketNum-- + "张票, 剩余" + ticketNum + "张票");
// 增大出错的概率
Thread.sleep(10);
}
} catch (InterruptedException e) {
e.printStackTrace();
} finally {
//4、解锁
lock.unlock();
}
synchronized和lock(ReentrantLock)锁的区别
1、synchronized内置的java关键字,Lock是一个java类
2、synchronized无法判断获取锁的状态, Lock可以判断是否获取到了锁 boolean isLocked()
3、synchronized会自动释放锁,Lock必须要手动释放锁!如果不是释放锁,会产生死锁
4、synchronized 线程1(获得锁),线程2(等待); Lock锁就不一定会等待下去,lock.tryLock()可以尝试去获取锁,不会一直等待,等不到就结束。
5、synchronized 和Lock锁都是 可重入锁,非公平的; Lock默认是非公平锁,可以设置为公平锁, synchronized不可以中断(interrupt和stop都不可中断)。
6、synchronized 适合锁少量的代码同步问题,Lock 适合锁大量的同步代码。
读写锁
public class ReadWriteLockDemo {
public static void main(String[] args) {
//未上锁:
MyCache myCache = new MyCache();
//上了读写锁:
// MyCacheWithLock myCache = new MyCacheWithLock();
//写入:
for (int i = 1; i <= 5; i++) {
final int temp = i;
new Thread(() -> {
myCache.write(temp + "", temp + "");
}, String.valueOf(i)).start();
}
for (int i = 1; i <= 5; i++) {
final int temp = i;
new Thread(() -> {
myCache.read(temp + "");
}, String.valueOf(i)).start();
}
}
}
class MyCacheWithLock {
private volatile Map<String, Object> map = new HashMap<>();
//读写锁:对数据更精准控制
private ReadWriteLock readWriteLock = new ReentrantReadWriteLock();
//写数据:只希望有一个线程在执行
public void write(String key, Object value) {
readWriteLock.writeLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "写入" + key);
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "写入完成!");
} catch (Exception e) {
e.printStackTrace();
} finally {
readWriteLock.writeLock().unlock();
}
}
//读数据:可一条或者多条同时执行
public void read(String key) {
readWriteLock.readLock().lock();
try {
System.out.println(Thread.currentThread().getName() + "读取数据:" + key);
Object o = map.get(key);
System.out.println(Thread.currentThread().getName() + "读取数据完成-->" + o);
} catch (Exception e) {
e.printStackTrace();
} finally {
readWriteLock.readLock().unlock();
}
}
}
/**
* 未上锁:
* 写入线程会被 读取线程中断,造成脏读,对数据不安全
*/
class MyCache {
private volatile Map<String, Object> map = new HashMap<>();
//写数据:
public void write(String key, Object value) {
System.out.println(Thread.currentThread().getName() + "写入" + key);
map.put(key, value);
System.out.println(Thread.currentThread().getName() + "写入完成!");
}
//读数据:
public void read(String key) {
System.out.println(Thread.currentThread().getName() + "读取数据:" + key);
Object o = map.get(key);
System.out.println(Thread.currentThread().getName() + "读取数据完成-->" + o);
}
}
Volatile
1、保证可见性
2、不保证原子性
3、禁止指令重排
public class VolatileDemo {
private volatile static int num = 0;
public static void main(String[] args) { // main
new Thread(new Runnable() {
@Override
public void run() {
while (num==0){
}
}
}).start();
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
num = 1;
System.out.println(num);
}
}
理解CAS
CAS: 全称Compare and swap,字面意思:”比较并交换“
CAS 是现代操作系统,解决并发问题的一个重要手段
CAS操作包括了3个操作数:
1、需要读写的内存位置(V)
2、进行比较的预期值(A)
3、拟写入的新值(B)
CAS操作逻辑如下:如果内存位置V的值等于预期的A值,则将该位置更新为新值B,否则不进行任何操作。
许多CAS的操作是自旋的:如果操作不成功,会一直重试,直到操作成功为止。
这里引出一个新的问题,既然CAS包含了Compare和Swap两个操作,它又如何保证原子性呢?
答案是:CAS是由CPU支持的原子操作,其原子性是在硬件层面进行保证的。
为什么需要AtomicInteger原子操作类?
在Java中自增i++操作不是原子操作,它实际上包含三个独立的操作:(1)读取i值;(2)加1;(3)将新值写回i
因此,如果并发执行自增操作,可能导致计算结果的不准确
对于Java中的运算操作,例如自增或自减,若没有进行额外的同步操作,在多线程环境下就是线程不安全的。
明显,这个操作不具备原子性,多线程并发共享这个变量时必然会出现问题
J.U.C 并发包提供了:
1、AtomicBoolean
2、AtomicInteger
3、AtomicLong
AtomicInteger i = new AtomicInteger(0);
// 获取并自增(i = 0, 结果 i = 1, 返回 0),类似于 i++
System.out.println(i.getAndIncrement());
// 自增并获取(i = 1, 结果 i = 2, 返回 2),类似于 ++i
System.out.println(i.incrementAndGet());
public class CASDemo {
public static void main(String[] args) {
AtomicInteger atomicInteger = new AtomicInteger(2020);
//如果是2020就改成2021
System.out.println(atomicInteger.compareAndSet(2020, 2021));
System.out.println(atomicInteger.get());
//如果和期望的值相同,就更新这个值,否则就不更新
System.out.println(atomicInteger.compareAndSet(2020, 2021));
System.out.println(atomicInteger.get());
}
}
总结:CAS:比较当前工作内存(线程)中的值和主内存中的值,如果这个值是期望的,那么则执行操作,如果不是,就一直循环
优点:好处是不用切换线程状态,因为切换线程状态性能消耗比较大
缺点:
1:由于底层是自旋锁,循环会浪费时间
2:因为是底层的cpu操作,一次只能保证一个共享变量的原子性


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









