






 本文介绍了计算机视觉中彩色图像的转换,包括将图像从RGB转换为HSV和HSI格式,并详细展示了如何将图像转换为灰度文件。接着,文章探讨了车牌数字分割的过程,包括二值化、开闭运算等步骤,以实现数字的精确分离。文章提供了实例和参考链接,便于深入理解。
本文介绍了计算机视觉中彩色图像的转换,包括将图像从RGB转换为HSV和HSI格式,并详细展示了如何将图像转换为灰度文件。接着,文章探讨了车牌数字分割的过程,包括二值化、开闭运算等步骤,以实现数字的精确分离。文章提供了实例和参考链接,便于深入理解。
一、彩色图像文件转换
1.转为HSV格式
(1)HSV颜色模型

(2)实例
#使用opencv
#直接读取图片
cv_read=cv2.imread(source_path)
#转化为hsv格式
lena_hsv=cv2.cvtColor(cv_read,cv2.COLOR_BGR2HSV)
cv2.imshow('lena',lena_hsv)
cv2.waitKey(0)

2.转为HSI 格式
(1)颜色模型

(2)实例
def RBG_to_HSI(rgb_img):
"""
: param rgb_img: RGB彩色图像
: return : HSI图像
"""
#保存原始图像的行列数
row=np.shape(rgb_img)[0]
col=np.shape(rgb_img)[1]
#对原始图像进行复制
hsi_img=rgb_img.copy()
#对图像进行通道拆分
B,G,R=cv2.split(rgb_img)
#把通道归一化到[0,1]
[B,G,R]=[i/255.0 for i in ([B,G,R])]
H=np.zeros((row,col))#定义H通道
I=(R+G+B)/3.0 #计算I通道
S=np.zeros((row,col))#定义S通道
for i in range(row):
den = np.sqrt((R[i]-G[i])**2+(R[i]-B[i])*(G[i]-B[i]))
thetha=np.arccos(0.5*(R[i]-B[i]+R[i]-G[i])/den)#计算夹角
h=np.zeros(col) #定义临时数组
#den>0且G>=B的元素h赋值为thetha
h[B[i]<=G[i]]=thetha[B[i]<=G[i]]
#den>0且G<=B的元素h赋值为thetha
h[G[i]<=B[i]]=2*np.pi-thetha[G[i]<=B[i]]
#den<0的元素h赋值为0
h[den==0]=0
H[i]=h/(2*np.pi) #弧度化之后赋值给H通道
for i in range(row):
min_=[]
#找出每组RGB的最小值
for j in range(col):
arr=[B[i][j],G[i][j],R[i][j]]
min_.append(np.min(arr))
min_=np.array(min_)
#计算S通道
S[i]=1-min_*3/(R[i]+B[i]+G[i])
#I为0的值直接赋值0
S[i][R[i]+B[i]+G[i]==0]=0
#扩充到255以方便显示,一般H分量在[0,2pi]之间,S和I在[0,1]之间
hsi_img[:,:,0]=H*255
hsi_img[:,:,1]=S*255
hsi_img[:,:,2]=I*255
return hsi_img
#使用opencv
#读取图片
cv_read=cv2.imread(source_path)
lena_hsi=RBG_to_HSI(cv_read)
cv2.imshow('lena',lena_hsi)
cv2.waitKey(0)

3.转换为灰度文件
导入包
#文件路径
#导入相关包
import cv2
import numpy as np
source_path="D:\\rgzn\\jupyter\\lena.jpg"
使用opencv
#使用opencv
#直接读取灰度图片
cv_read=cv2.imread(source_path,0)
cv2.imshow('lena',cv_read)
cv2.waitKey(0)
运行结果

不使用opencv
#不使用opencv
row,col,channel=cv_read.shape
lena_gray=np.zeros((row,col))
for r in range(row):
for l in range(col):
lena_gray[r,l]=1/3*cv_read[r,l,0]+1/3*cv_read[r,l,1]+1/3*cv_read[r,l,2]
cv2.imshow("lena",lena_gray.astype("uint8"))
cv2.waitKey(0)
运行结果

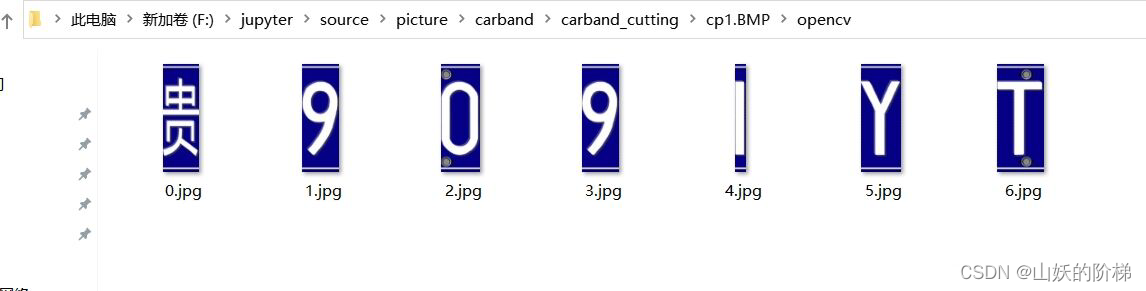
二、车牌数字分割
1.步骤
①转化为二值化图片
②利用开闭运算等操作使一个字成为一个整体
③利用函数定为或者手工定位
2.实例
#导入相关包
import cv2
import numpy as np
import os
pic_folder='D:\\rgzn\\jupyter\\carband\\'
pic_one="cp1.BMP"
save_path='D:/rgzn/jupyter/carband/carband_cutting/'
#创建文件夹
def mkdir(path):
folder=os.path.exists(path)
if not folder:#判断是否存在
os.makedirs(path)
#图片路径构建及创建文件夹
plate_numbers=pic_folder+pic_one
s_path=save_path+pic_one
mkdir(s_path)
plate=cv2.imdecode(np.fromfile(plate_numbers,dtype=np.uint8),-1)
cv2.imshow("carband",plate)
cv2.waitKey(0)
#对图片进行处理,进行二值化
plate_gauss=cv2.GaussianBlur(plate,(5,5),0)#高斯降噪
plate_gray=cv2.cvtColor(plate_gauss,cv2.COLOR_BGR2GRAY)#灰度化
thre,plate_bw=cv2.threshold(plate_gray,170,255,cv2.THRESH_BINARY)#二值化
cv2.imshow("cell",plate_bw)
cv2.waitKey(0)
闭运算,使字这些连在一起,变成一个整体
#腐蚀运算,消除掉中间那颗螺丝的影响
#构造一个全1的5*5的矩阵
kernel=np.ones((3,3),int)#设置形态学操作卷积的大小
plate_corr=cv2.erode(plate_close,kernel,iterations=1)
cv2.imshow("cell",plate_corr)
cv2.waitKey(0)
```
进行切割
```bash
#切割图片并保存
def cutting(start,end,order,src,path):
dst=src[:,start-3:end+3]
file_name=path+str(order)+'.jpg'
cv2.imencode(".jpg",dst)[1].tofile(file_name)
plate_count,hir=cv2.findContours(plate_corr,cv2.RETR_EXTERNAL ,cv2.CHAIN_APPROX_NONE)
#检测所有轮廓,所有轮廓建立一个等级树结构。
plate_read=cv2.imdecode(np.fromfile(plate_numbers,dtype=np.uint8),-1)
result=plate_read
for i in range(len(plate_count)):
cnt=plate_count[i]
x,y,w,h=cv2.boundingRect(cnt)
save_path_o=s_path+'/opencv/'
mkdir(save_path_o)
cutting(x,x+w,i,plate_read,save_path_o)
#flag是用来判断字符个数的,当flag为7时,就代表已经全部识别完了
#word是用来判断一个字的开始和结束,开始时word会加1,结束时word也会加一,所以为2就检测完了一个字
flag=0
word=0
word_start=0
word_end=0
word_color=False#判断某一列中是否有字体的颜色
save_path_a=s_path+'/artificial/'
plate_read=cv2.imdecode(np.fromfile(plate_numbers,dtype=np.uint8),-1)
for i in range(len(plate_corr[0])):#遍历每一列
word_color=False
if 255 in plate_corr[:,i]:
word_color=True
if word_color==True and word==0:#如果检测到字体的颜色,word+1
word+=1
word_start=i
elif word_color==False and word==1:#判断字结束
word+=1
word_end=i+3
flag+=1
mkdir(save_path_a)
cutting(word_start,word_end,flag,plate_read,save_path_a)
if word==2:
word=0
word_start=0
word_end=0
if flag==7:
break 
三、总结
参考链接
https://blog.youkuaiyun.com/junseven164/article/details/121714300
https://blog.youkuaiyun.com/qq_45659777/article/details/121716220


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









