







 本文介绍了数据库中的索引扫描,如B树索引、哈希索引和GiST索引,以及顺序扫描的原理和应用。重点讲解了多表连接中的哈希连接(hashjoin),包括其在不同情况下的优势和适用性。还提到了SQL执行计划分析,展示了如何通过`USE_HASH`优化查询性能。
本文介绍了数据库中的索引扫描,如B树索引、哈希索引和GiST索引,以及顺序扫描的原理和应用。重点讲解了多表连接中的哈希连接(hashjoin),包括其在不同情况下的优势和适用性。还提到了SQL执行计划分析,展示了如何通过`USE_HASH`优化查询性能。
1.知识储备
1.索引扫描
索引扫描是通过使用索引来定位和访问数据库中特定数据的方式。当需要通过查询条件获取特定数据时,使用索引扫描可以快速定位到所需的数据,提高查询效率。
索引可以是 B 树索引、哈希索引或 GiST 索引等不同类型。其中,B 树索引是最常用的索引类型。当执行查询时,Postgres 会使用 B 树索引来优化查询。具体的优化过程如下:
- 根据查询条件解析查询语句,确定需要使用的索引。
- 使用索引树进行二叉搜索,找到满足查询条件的叶子节点。
- 通过叶子节点获取所需的数据行。
索引扫描适用于需要获取特定数据子集的查询,例如根据主键或唯一键查询、范围查询等。下面是一个使用索引扫描的示例:
SELECT * FROM employees WHERE employee_id = 1001;
在这个例子中,如果 employee_id 字段有索引,Postgres 将使用索引扫描来快速定位到 employee_id 为 1001 的数据行。
2.顺序扫描
顺序扫描是按照数据在磁盘上存储的物理顺序进行数据访问的方式。当查询无法利用索引进行优化或需要遍历整个表的数据时,使用顺序扫描是一种常见的选择。
顺序扫描会按照数据在磁盘上存储的物理顺序进行逐行读取,可能需要扫描整张表的数据。这种方式的查询效率较低,但在某些情况下是必要的,例如需要对整张表进行聚合操作或需要全表扫描进行数据分析的场景。
下面是一个使用顺序扫描的示例:
SELECT * FROM employees;
在这个例子中,如果没有适用的索引,Postgres 将使用顺序扫描来逐行读取整张表的数据。
3.多表连接
多表连接三种常用方式:sort merge-join、nested loop、hash join。
nested loop join
嵌套循环连接,是比较通用的连接方式,分为内外表,每扫描外表的一行数据都要在内表中查找与之相匹配的行,没有索引的复杂度是O(N*M),这样的复杂度对于大数据集是非常劣势的,一般来讲会通过索引来提升性能。
sort merge-join
merge join需要首先对两个表按照关联的字段进行排序,分别从两个表中取出一行数据进行匹配,如果合适放入结果集;不匹配将较小的那行丢掉继续匹配另一个表的下一行,依次处理直到将两表的数据取完。merge join的很大一部分开销花在排序上,也是同等条件下差于hash join的一个主要原因。
Hash Join
借助Hash算法,连带小规模的Nest Loop Join,同时利用内存空间进行高速数据缓存检索的一种算法。
Hash Join介绍
简单的对于两个表来讲,hash-join就算讲两表中的小表(称S)作为hash表,然后去扫描另一个表(称M)的每一行数据,用得出来的行数据根据连接条件去映射建立的hash表,hash表是放在内存中的,这样可以很快的得到对应的S表与M表相匹配的行。
对于结果集很大的情况,merge-join需要对其排序效率并不会很高,而nested loop join是一种嵌套循环的查询方式无疑更不适合大数据集的连接,而hash-join正是为处理这种棘手的查询方式而生,尤其是对于一个大表和一个小表的情况,基本上只需要将大小表扫描一遍就可以得出最终的结果集。
不过hash-join只适用于等值连接,对于>, <, <=, >=这样的查询连接还是需要nested loop这种通用的连接算法来处理。如果连接key本来就是有序的或者需要排序,那么可能用merge-join的代价会比hash-join更小,此时merge-join会更有优势。
hash-join其实还有很多需要考虑和实现的地方,比如数据倾斜严重如何处理、内存放不下怎木办,hash如何处理冲突等(常用解决哈希冲突的方法有两种「开放地址法」和「链表法」)。
Hash Join举例
1.Hash表的建立
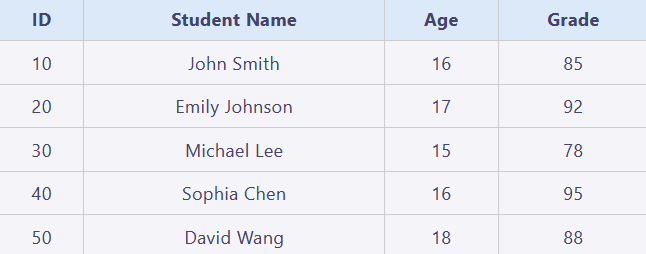
假设在一次students表和score表的连接中,哈希表是hr.students,连接列是ID。
数据库会使用哈希函数,对每一个ID进行哈希运算,生成一个哈希值,设散列函数为:
H[key] = key % 4;
在这次描述里,hash表有5个插槽(可以更多或者少),也就是n=5,hash值得范围是0到3。
所以哈希函数生成得哈希值如下:
H(10) = 2
H(20) = 0
H(30) = 2
H(40) = 0
H(50) = 2
你可能会注意到,10跟30的哈希值是一样的,这个叫做哈希冲突。在这种情况下,数据库会把10和30的记录给放到同一个插槽(4)里面,用一个链接列表把他们放在一起。
理论上来说,hash表看起来会是:
1 20,Marketing,201,1800
2 40,Human Resources,203,2400
3
4 10,Administration,200,1700 -> 30,Purchasing,114,1700
5 50,Shipping,121,1500
SQL调优之五:哈希连接(Hash Joins) - Ryan_Wo - 博客园
2.sql与执行计划分析
1.示例1:
SQL
create table subql (valuel smallint, wordl char(7), inti int);
load from "subq1.unl" insert into subql;
create table subq2 (value2 smallint, word2 char(7), int2 int);
load from "subq2.unl" insert into subq2;
create index subql_valuel on subq1(valuel);
create index subq2_value2 on subq2(value2);
update statistics high;
set explain on;
select /*+ USE_HASH(t1) */ valuel, int1, value2, int2
from subq1 t1, subq2 t2where word2 = wordi and int2 = 30 and valuel >=
ALL (select t1.valuel from subq1 t3 where t2.int2 = t3.int1 and t1.valuel=t3.valuel);
Explain Plan
QUERY:(查询)
---------
select /*+ USE_HASH(t1) */ value1, int1, value2, int2
from subql t1, subq2 t2
where word2=wordl and int2 =30 and valuel >=ALL (select t1.valuel from subql t3 where t2.int2= t3.int1 and t1.valuel=t3.valuel)
DIRECTIVES FOLLOWED:(遵循的指令)
USE_HASH ( t1 )
DIRECTIVES NOT FOLLOWED:
Estimated Cost: 21(预估开销值)
Estimated # of Rows Returned: 1 (预估数据返回行数)1) sqlqa.t1: SEQUENTIAL SCAN (表的访问顺序与访问方法)
2) sqlqa.t2: SEQUENTIAL SCAN
Filters:
Table Scan Filters : sqlqa.t2.int2=30 (过滤条件)DYNAMIC HASH JOIN
Dynamic Hash Filters: sqlqa.t2.word2=sqlqa.t1.word1Other Join Filters: sqlqa.t1.value1 >=ALL <subquery>
Subquery:(子查询)
---------
Estimated Cost:1
Estimated # of Rows Returned: 11) sqlqa.t3: INDEX PATH
Filters: sqlqa.t3.int1=30(1) Index Keys: value1(Serial, fragments:ALL)
Lower Index Filter: sqlqa.t3.value1 = sqlqa.t1.valuel
-----------------------------------------------------------------
gbase 8s sql执行计划分析_gbase执行计划解析_kaixin.1的博客-优快云博客


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









