







 该博客探讨了自然语言处理技术在文本分类、翻译和情感分析中的应用。通过清理和预处理用户商品评价,构建词典和词根化处理,利用简单词袋模型和朴素贝叶斯算法建立预测模型,实现对新用户是否喜欢商品的判断。尽管词袋模型存在局限性,但准确率达到了0.73,展示了其在文本分析中的有效性。此外,还提及了TF-IDF模型在评估词语重要性方面的优势。
该博客探讨了自然语言处理技术在文本分类、翻译和情感分析中的应用。通过清理和预处理用户商品评价,构建词典和词根化处理,利用简单词袋模型和朴素贝叶斯算法建立预测模型,实现对新用户是否喜欢商品的判断。尽管词袋模型存在局限性,但准确率达到了0.73,展示了其在文本分析中的有效性。此外,还提及了TF-IDF模型在评估词语重要性方面的优势。
自然语言处理的应用
文本的分类,文本的翻译
文本情感分析
基于词典
- 定义词典
- 分词
- 计算句子的总得分
基于机器学习
- 数据预处理
- 分词
- 提取特征
- 训练
- 测试
- 分析数据
实例
根据用户的评价和是否喜欢某商品训练模型,根据新用户的评价判断是否喜欢某商品——运用简单一维磁带模型
- 文本的清理:将所有评论看成一个稀疏矩阵,行数代表评论的个数,列数代表不同单词的个数,矩阵某行某列的元素代表在当前这条评论中当前列单词的个数
- 清楚所有的标点符号和数字:标点符号对用户对某商品的好恶相关性很低,对于模型是噪声
- 大小写转换
- 清理虚词:实际
在清理虚词中无法下载nltk语料库的问题
解决方法:手动下载数据https://files-cdn.cnblogs.com/files/douzujun/stopwords.zip
根据控制台输出的提示信息将其放在指定的文件夹中
比如我的控制台输出

将最后的解压文件夹放在F:\anaconda\nltk_data\corpora\stopwords,再导入from nltk.corpus import stopwords经验证可以运行 - 词根化
- 将清理后的单词重新串成字符串
简单词袋模型的局限性:可能会忽略掉关键信息,如not good,在清理虚词时去掉了not,将负面评价转化成了正面评价,会极大地影响最后模型的效果
解决办法:运用更高维的磁带模型,如将not good看成一个向量判断
# -*- coding: utf-8 -*-
"""
Created on Fri Jan 28 15:47:28 2022
@author: ASUS-PC
"""
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
dataset = pd.read_csv("Restaurant_Reviews.tsv",delimiter='\t',quoting=3)
row=dataset.iloc[:,0].size
import re
import nltk
from nltk.corpus import stopwords
from nltk.stem.porter import PorterStemmer
corpus=[]
for i in range(0,row):
#清理标点和数组
review=re.sub('[^a-zA-Z]',' ',dataset['Review'][i])
#全部转化为小写
review=review.lower()
#将字符串转化为单词序列
review=review.split()
#清理虚词,取词根
ps=PorterStemmer()
review=[ps.stem(word) for word in review if not word in set(stopwords.words('english'))]
#将单词重新串成字符串
review=' '.join(review)
#corpus为清理后的评价序列
corpus.append(review)
#创建稀疏矩阵
from sklearn.feature_extraction.text import CountVectorizer
#可以通过类的参数直接完成清理的过程,但上述手动清理的自由度更高
#max_features规定最大的列的总数,忽略掉出现次数不多的词语
cv=CountVectorizer(max_features=1500)
X=cv.fit_transform(corpus).toarray()
y=dataset.iloc[:,1].values
#运用朴素贝叶斯算法进行预测
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20, random_state = 0)
# Fitting Naive Bayes to the Training set
from sklearn.naive_bayes import GaussianNB
classifier = GaussianNB()
classifier.fit(X_train, y_train)
# Predicting the Test set results
y_pred = classifier.predict(X_test)
# Making the Confusion Matrix
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y_test, y_pred)
混淆矩阵
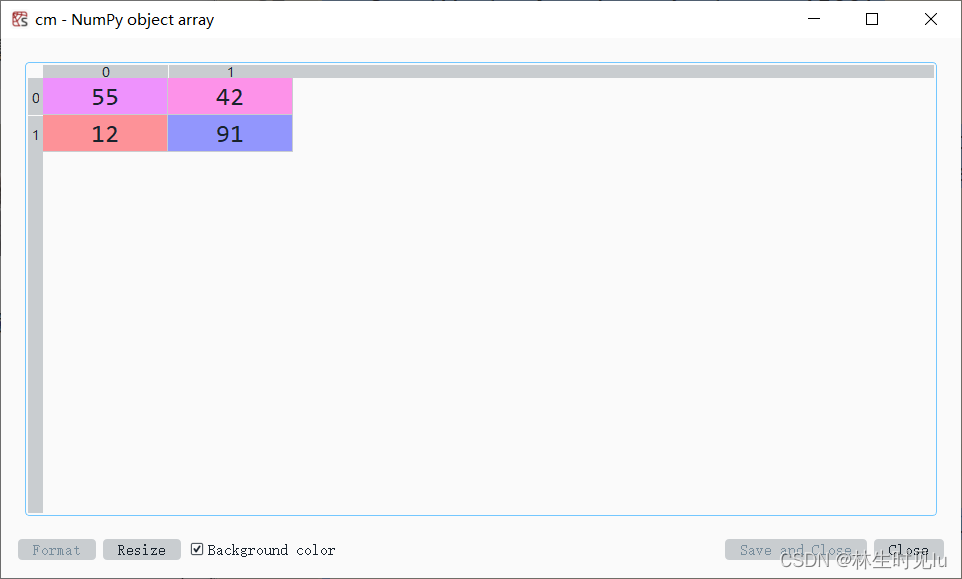
预测的准确率为0.73,对于简单的词袋模型已经较为满意
TF-IDF模型
TF-IDF模型用于在文档集中评估某个词对某份文档的重要程度,一个词语在某篇文章中出现得越多,在所有文章中出现得越少,则这个词越能代表这篇文章
TF是什么

IDF是什么



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









