






 本文详细介绍了如何构造双向带头循环链表,包括单个结点结构、哨兵头、双向连接和循环结构。此外,涵盖了创建哨兵、尾插、尾删、头增、头删等关键链表操作的函数实现。
本文详细介绍了如何构造双向带头循环链表,包括单个结点结构、哨兵头、双向连接和循环结构。此外,涵盖了创建哨兵、尾插、尾删、头增、头删等关键链表操作的函数实现。
目录:
一:如何实现双向带头循环链表
(1)链表单个结点的结构
(2)带头??头是什么
(3)双向??互相指向。
(4)循环??尾结点与哨兵位互相指向。
二:各种链表接口函数的实现
(1)创建哨兵位结点的函数
(2)尾插函数实现
(3)尾删函数实现
(4)头增函数实现
(5)头删函数实现
(6)查询函数的实现
(7)任意位置插入函数
(8)删除任意结点
一:如何实现双向带头循环链表
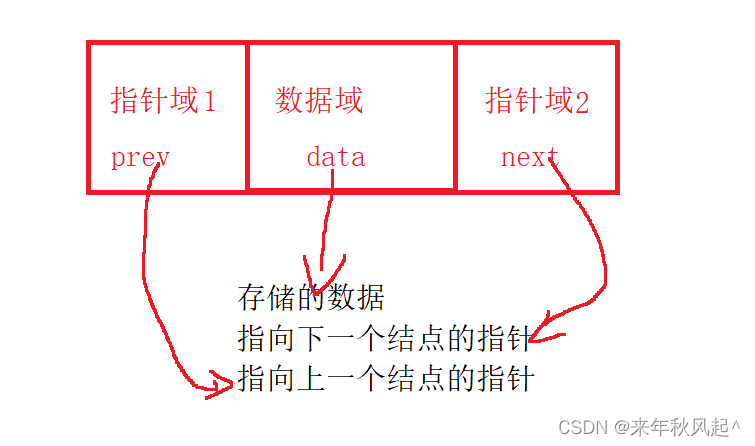
(1)链表单个结点的结构

单个结点的结构图解如下
(2)带头??头是什么
头:在这种数据结构中又被称为该链表的哨兵位,它与其他结点结构相同,只是在它的数据域不存储任何数据。
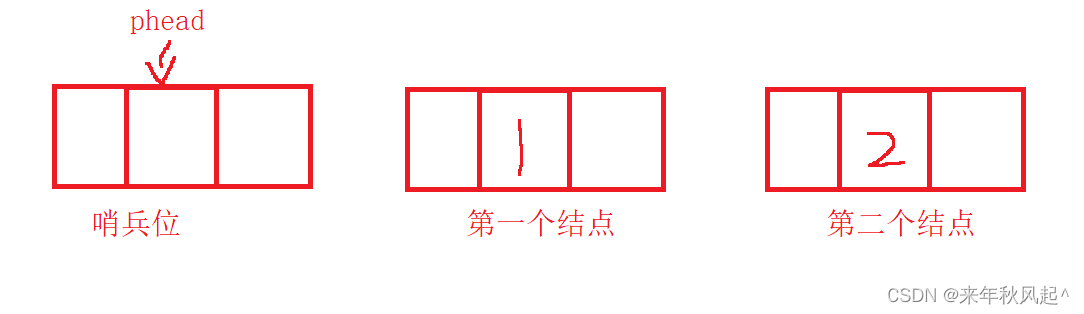
例如:我们现在使用phead指针,去维护这个哨兵位的结点,哨兵位之后的那个结点,才是该链表的第一个结点。
(3)双向??互相指向。
在之前的单链表中,每个结点存储下一个结点的地址。但是在现在这种结构里,每一个结点有两个指针,一个指向该结点的下一个结点(一般命名为next),一个指向该结点的上一个节点(一般命名为prev)。
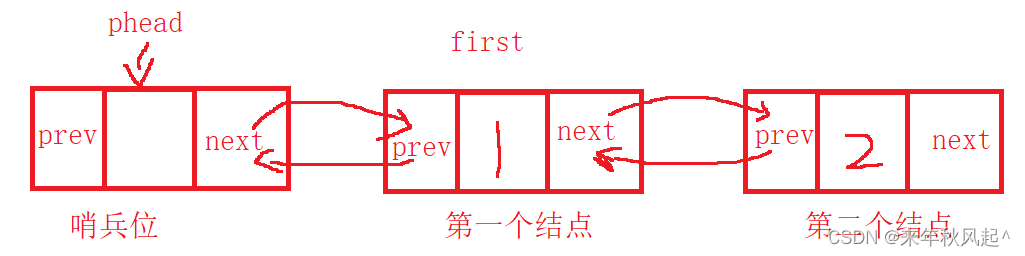
可以看到,哨兵位结点的next指向第一个结点,第一个结点的prev指向哨兵位结点
通俗来说就是:phead->next存储的是first的地址,first->prev存储的是phead的地址,后面的以此类推。
(4)循环??尾结点与哨兵位互相指向。
在这种链表的结构中,循环就代表着phead->prev指向最后一个结点,最后一个结点的next指向哨兵位。
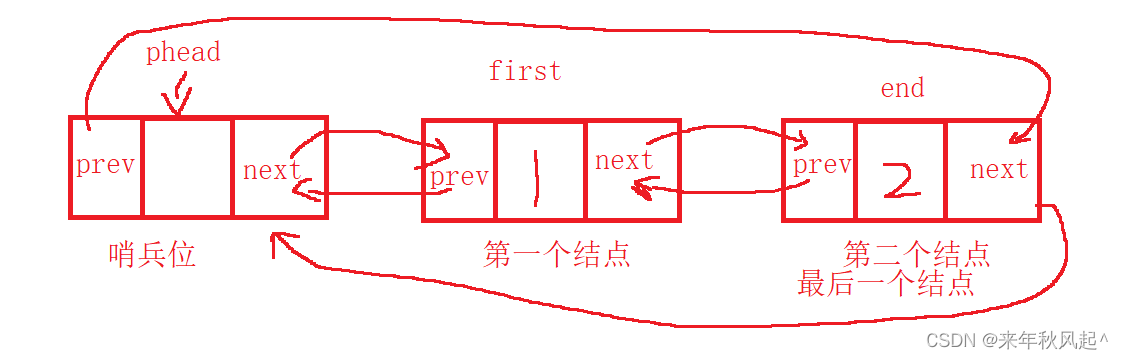
按照图解来说就是:
phead->prev=end; //哨兵位结点的上一个结点是尾结点
end->next=phead ; //尾结点的下一个结点是哨兵位结点
二:各种链表接口函数的实现
(1)创建哨兵位结点的函数
//初始化链表
Dlist* Dlistinit()
{
Dlist* phead = (Dlist*)malloc(sizeof(Dlist));
phead->next = phead;
phead->prev = phead;
return phead;
}malloc一个结点,初始化时该节点的next和prev都指向自己。初始化完成后返回该结点的地址,交给同类型指针phead维护。(这里唯一注意的就是哨兵位结点的数据域不能存放任何数据)有点地方将这个数据域存储该链表的长度,这种操作方式是不可取的,因为链表可以无限往后添加(只要空间足够),但是一块空间存储的数据总有存满的时候。
(2)尾插函数实现
//尾增
void Dlist_push_tail(Dlist* ps, Dlistdatatype tmp)
{
Dlist* newnode = buy_newnode(tmp);
//找到尾,尾结点的next指向哨兵位的
Dlist* cur = ps->next;
while (cur->next != ps)
{
cur = cur->next;
}//出循环时 cur->next == ps
cur->next = newnode;
newnode->prev = cur;
newnode->next = ps;
ps->prev = newnode;
}
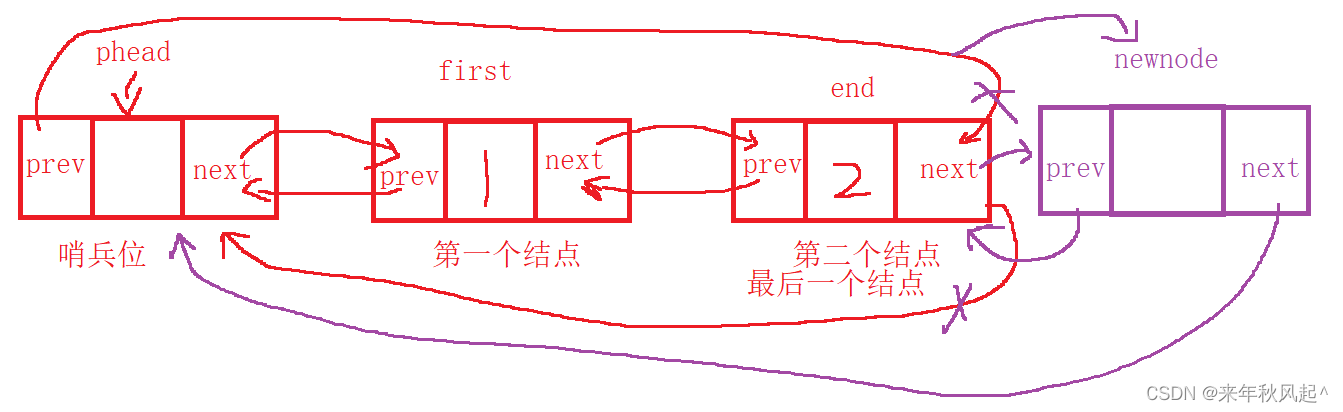
尾插时,要先找尾,因为该结构的原因,尾结点的next指向的是哨兵位,以此作为判断尾的条件。找到尾后,
将尾的next指向新增的结点,
将新增的结点的prev指向原来的尾,
将哨兵位的prev指向新尾
将新增节点的next指向哨兵位就可以完成尾插。
基本图解如下
(3)尾删函数实现
//尾删
void Dlist_pop_tail(Dlist* ps)
{
Dlist* cur = ps->prev;//拿到尾
if (cur == ps)
{
printf("链表已经清空\n");
}
else
{
Dlist* newtail = cur->prev;
newtail->next = ps;
ps->prev = newtail;
free(cur);
}
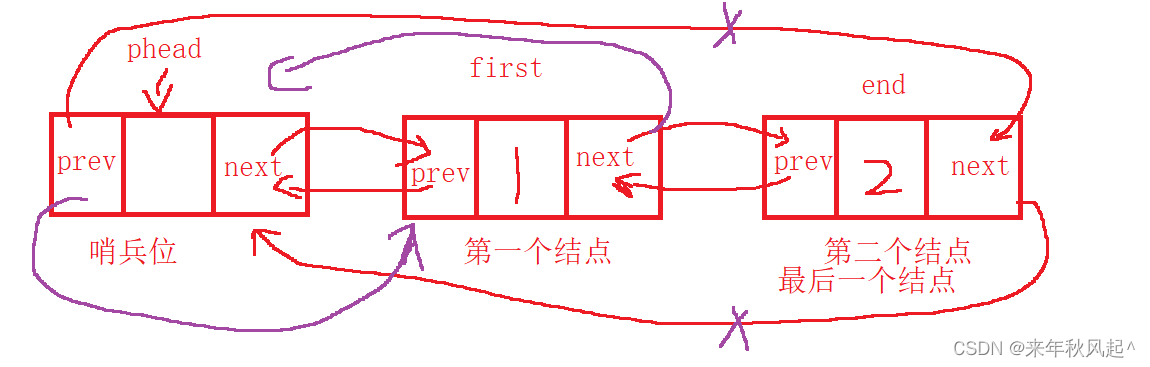
}因为是循环结构的原因,所以phead->prev一直都是指向尾的,我们通过哨兵位拿到尾结点的地址,再通过尾结点拿到尾结点前一个结点的地址(这里将它交给newtail维护)。
然后链接newtail和phead即可。
当然要注意的是如果没有结点了,我们就不要进行上面的操作了。
基本图解如下
(4)头增函数实现
//头增
void Dlist_push_head(Dlist* ps, Dlistdatatype tmp)
{
Dlist* newnode = buy_newnode(tmp);//新创建一个结点
Dlist* first = ps->next;//拿到第一个结点
ps->next = newnode;
newnode->next = first;
newnode->prev = ps;
first->prev = newnode;
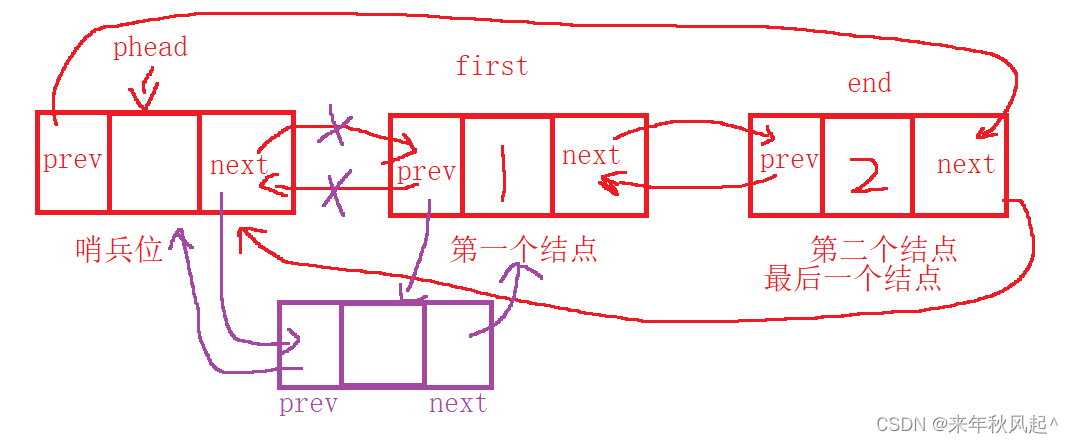
}头增时,哨兵位结点的next指向第一个结点,使用first维护,
将firsr->prev指向newnode,
newnode->next指向first,
将phead->next指向newnode。
将newnode->prev指向phead
基本图解如下:
(5)头删函数实现
//头删
void Dlist_pop_head(Dlist* ps)
{
if (ps == ps->next)
{
printf("链表已经清空\n");
}
else
{
Dlist* first = ps->next;
Dlist* new_first = first->next;
ps->next = new_first;
new_first->prev = ps;
free(first);
}
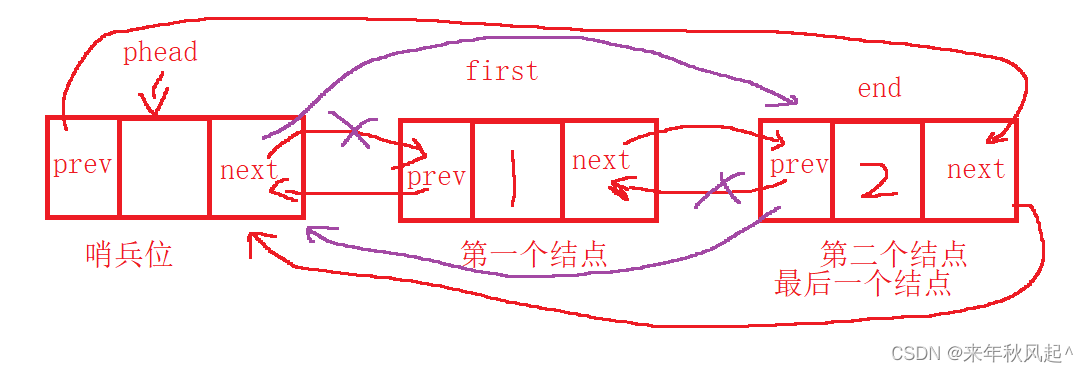
}通过哨兵位结点获得第一个结点的地址,再通过第一个结点获得第二个结点的地址(用new_first维护)。
链接哨兵位结点和new_first结点
将ps->next指向new_first;
将new_first->prev指向ps即可
释放原来第一个结点空间。
当然,如果该链表只有一个哨兵位结点,那就不要进行上面的操作了
基本图解如下:
(6)查询函数的实现
//查询函数,遍历链表查询数据
Dlist* Dlist_chage(Dlist* ps, Dlistdatatype tmp)
{
Dlist* cur = ps->next;
while (cur != ps)
{
if (cur->data == tmp)
{
return cur;
}
cur = cur->next;
}
return NULL;
}通过传递的数据,遍历链表,查到了返回该结点地址,查询不到返回空指针。
可以通过查询函数,实现修改的功能。
(7)任意位置插入函数
在任意数据位置前面,插入一个数据。在实现该函数时,当被操作的链表只有一个哨兵位结点时,那我们直接将数据插入该结点后面。
//任意位置前面插入
void Dlist_push_any(Dlist* ps, Dlistdatatype tmp, Dlistdatatype x)
{
Dlist* newnode = buy_newnode(x);//新创建一个结点
if (ps->next == ps)
{//除了哨兵位结点没有其他结点
ps->next = newnode;
ps->prev = newnode;
newnode->next = ps;
newnode->prev = ps;
}
else
{
Dlist* pos = Dlist_chage(ps, tmp);
if (pos == NULL)
{
printf("没有该元素\n");
}
else
{
Dlist* cur = pos->prev;
cur->next = newnode;
newnode->next = pos;
pos->prev = newnode;
newnode->prev = cur;
}
}
}(8)删除任意结点
删除任意结点的数据,通过查询函数,查到该结点的地址,然后将该结点前后两个结点链接起来吗,最后将该进行空间释放(删除)。
//删除任意结点
void Dlist_pop_any(Dlist* ps, Dlistdatatype tmp)
{
if (ps == ps->next)
{
printf("该链表已经清空\n");
}
else
{
Dlist* pos = Dlist_chage(ps, tmp);
if (pos == NULL)
{
printf("没有该元素\n");
}
else
{
Dlist* prev1 = pos->prev;
Dlist* next1 = pos->next;
prev1->next = next1;
next1->prev = prev1;
free(pos);
}
}
}最后通过测试,只需要最后三个函数,就可以实现前面所有函数的功能,头增,头删,尾增,尾删。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









