







目录
基本信息
📋标题:
An Industrial Framework for Personalized Serendipitous Recommendation in E-commerce
🎓作者:
Wang Zongyi,Zou Yanyan,Dai Anyu,Hou Linfang,Qiao Nan,Zou Luobao,Ma Mian,Ding Zhuoye,Xu Sulong
🗓️出版期刊和年份:RecSys-2023
📍影响因子:
作者单位:JD.com
💭引用
Wang, Z. et al. An Industrial Framework for Personalized Serendipitous Recommendation in E-commerce. in Proceedings of the 17th ACM Conference on Recommender Systems 1015–1018 (ACM, 2023). doi:10.1145/3604915.3610234.
🌟关键词
多兴趣、个性化、过滤气泡、惊喜度推荐、细粒度、已部署
🎯研究背景
1)以前研究存在的问题:
①存在过滤气泡问题,让用户感到不满意。【over-specialization、filter bubbles、user boredom】针对这个问题,需要打破反馈循环(feedback loop)
②大部分研究因其复杂性和缺乏可扩展性无法应用于现实世界;
2)研究目的:给用户推荐偏离用户先前行为但意想不到又满意(惊喜)的产品类别。(这里需要注意是类别,而不是商品)
3)研究难点:很难识别用户何时愿意接受惊喜度的商品以及期望获得多少新颖的商品,同时惊喜度感知是动态变化的。(不同用户可以接受的新颖性程度不同)
🎞️研究内容
1)在电子商务平台(即 JD.com)中引入了一个新颖的个性化惊喜推荐框架,该框架可以在兼顾准确性和新颖性的前提下,向用户推荐偏离用户先前行为的意想不到且令人满意的商品。
2)设计了一个两阶段框架。首先,部署一个基于 DNN 的类别新奇评分器,根据用户行为历史量化产品类别的新奇程度。然后,部署一个新奇意图检测器量化推荐列表的惊奇程度,我们采用潜在结果框架来决定向用户推荐惊喜物品的最佳时机以及推荐的新奇程度。
3)在 JD.com 电子商务推荐平台上进行的在线 A/B 测试表明模型在各种指标上都取得了显著的收益。
💡创新点
1)考虑到了惊喜度推荐中推荐给用户的时机和新奇的程度。
2)成功部署在现实应用中(京东)
🚩研究方法
(1)类别新奇评分器
1)某一类别novelty的定义:指用户已知的兴趣和自身在特征空间中的位置。(本文希望通过根据观察到的用户行窃来衡量用户对某个类别的兴趣程度)
2)动态路由捕获多兴趣:类似于文献(Multi-interest network with dynamic routing for recommendation at Tmall),将用户历史行为的行为归纳为几个群组,每个群组代表用户兴趣的一个特定的方面。
3)公式计算:
用户u对类别c的偏好得分:
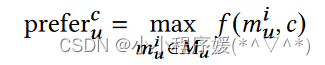
(其中miu表示第i个兴趣簇,f为余弦相似度函数)
用户u对类别c的惊喜度得分:

(2)新奇意图检测器
1)解决第一个挑战:用户何时愿意看到更多新奇商品。
将新颖性需求建模为用户对惊喜度推荐的参与度,即整个推荐列表(也就是说,既包括新奇的,也包括熟悉的物品)的点击数。更多的点击代表更好的用户满意度和体验。此外,为了捕获用户在一个会话中对新颖性偏好的变化,对于每个N个令人印象深刻的项目(例如,单个请求),我们做了一个预测,以检查用户对新颖性的偏好是否发生了变化。
2)解决第二个挑战:用户期望看到多少新奇物品
1)根据惊喜得分Scu将类别的新颖性分为4个等级。(0.5 0.7 0.9)
推荐列表的新奇度表示:𝐷 = {𝑑0, 𝑑1, 𝑑2, 𝑑3},di表示第i组项目类别数的比例. D = { 0.25,0.25,0.25,0.25 }表示一种特殊情况,其中每个新颖性组所占比例相同。
2)uplift modeling:可以直接模拟处理方法对个人行为增量影响。对应本研究中的用户在获得惊喜推荐后增加的点击次数。不同新奇度的推荐列表代表不同的处理方法。【可以了解】
3)潜在框架:为了衡量不同新奇度对用户点击量的影响,借鉴了潜在结果框架【14 15】
简化:考虑一个两臂试验,其中t = 0表示控制条件,即没有惊喜推荐的默认产品设置,t = D表示实验条件,其中意外推荐的新颖性程度为D。然后,计算实验的平均因果效应为
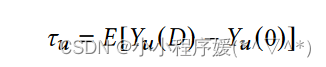
这实际上是用户u在处理条件下的点击变化。对于多臂场景,我们希望找到一个新颖度为D的处理使得τu最大化。
4)使用两层感知器和一个softmax层建立一个基于神经网络的新奇意图检测模型来预测点击率变化。
学习了一种典型的增益模型来直接预测点击变化值[ 18 ]。通过实验观察到,由于数据稀疏问题,预测分类标签更适合我们的场景。以双臂案例为例,将任务转化为二分类问题。将τu > δ的样本视为正例,其他样本视为负例。然后使用经典的交叉熵损失函数对模型进行训练。
(3)对惊喜推荐列表排序
个性化部分
一旦我们以新颖度D捕捉用户对惊喜推荐的偏好,我们根据KL散度得分对排序结果进行重新排序:
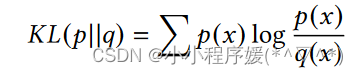
(4)部署工作
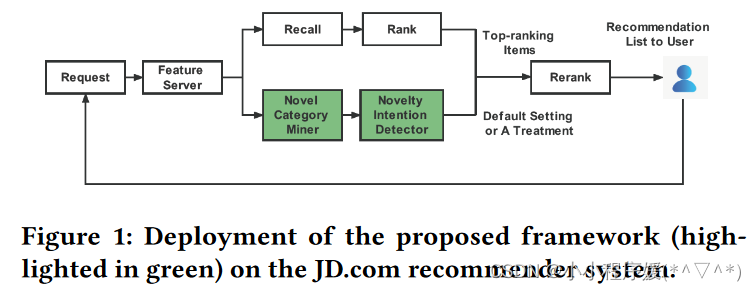
上图展示了部署的工作流的概述架构。为了节省服务延迟,所提出的框架与现有的推荐系统(即Recall和Ranking阶段)并行工作。由于用户对新颖性的偏好会随着时间的变化而变化,因此模型会定期在线更新。
(5)实验
数据集:collected from the “Recommended to You" of JD.com
1)离线测试
考虑了两种情况:默认生产设置和新奇推荐程度为𝐷 = {0.30, 0.30, 0.20, 0.20}(本质上是二分类任务)
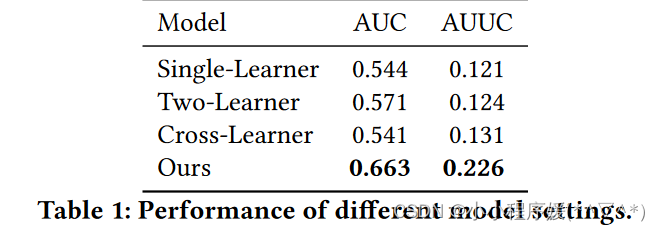
评价指标
AUC:分类预测
AUUC:所选处理方法累计收益
实验结论:在两个指标上都取得了最好的性能
2)在线A/B测试
时间:from 2023-01-06 to 2023-02-06

将方法与PURS [ 7 ]的默认生产设置进行了比较。为了评估每个模块的效果,我们还考虑了两种设置:1 )只有类别新颖性评分器,这是一种非个性化的设置,所有的流量具有相同的新颖性程度,记为" +类别新颖性评分器"。2 )同时具有类别新颖性评分器和新颖性意图检测器模块,这是一种考虑偶然性推荐的个性化需求的设置,记为" Ours "。
评价指标
-
业务指标
Impression Depth:一次会话的平均印象
UCTR:点击率变体,用户的平均点击次数(印象深刻的)
-
新奇度指标
Impression Novel Category:令人印象深刻的新奇项目
的平均数量
Clicked Novel Category:点击新奇项目的平均数量
实验结论:在两种指标上都取得了显著改善
✅研究结论
提出了一个新颖的个性化惊喜推荐框架,由两个模块组成,即类别新奇度评分器和新奇意图检测器。类别新奇度评分器的目的是对一个类别对用户的新奇程度进行排名,然后使用新奇意图检测器来识别用户在什么时候容易获得惊喜和什么样的新奇物品。在线实验证明了我们提出的框架的优越性。
✅未来研究方向
计划将多个优化目标(如转换率)纳入提升建模。
👀个人总结
优点:
在京东上部署测试,测试充分。
考虑到了惊喜推荐的时间和程度
对于惊喜度得分的计算比较简单
不足:
疑问:通过定期在线更新来解决用户偏好动态变化问题?
实现部分和实验部分描述简单,不易理解
惊喜推荐给用户的最佳时机感觉不是很明显
📚知识拓展
uplift modeling 模型:
介绍链接:[因果推断] 增益模型(Uplift Model)介绍(三)_uplift模型-优快云博客
预测用户因为广告而购买的概率,这是一个因果推断的问题,帮助我们定向营销敏感人群,预知每个用户的营销敏感程度,从而制定差异化营销策略,促成整个营销的效用最大化。uplift概念:the effect of an action on some customer outcome


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









