




 该博客通过聚类分析探讨《红楼梦》作者问题。实验使用章节中的虚词频率作为特征,进行了最大最小标准化处理,然后应用均值聚类和层次聚类方法,以揭示可能的作者分布。在实验中,解决了文件编码和中文显示问题。
该博客通过聚类分析探讨《红楼梦》作者问题。实验使用章节中的虚词频率作为特征,进行了最大最小标准化处理,然后应用均值聚类和层次聚类方法,以揭示可能的作者分布。在实验中,解决了文件编码和中文显示问题。
红楼梦作者分析(聚类)
实验要求
实验题目:《红楼梦》作者分析
《红楼梦》是我国著名的四大名著之一,一般的认为《红楼梦》的前八十回为曹雪芹撰写,后四十回为高鹗续写,但也有学者对此并不认可。能否利用聚类分析的方法来对《红楼梦》的作者进行分析。
提示思路:一般来说,不同的作者往往会具有不同的写作风格,这些风格可以通过在文中的虚词的频率进行衡量,因此,可以考虑统计各章中虚词出现频率,并以此作为基础数据来聚类分析,对《红楼梦》章节进行划分,从而分析章节与作者之间的关系。
实验目的
在掌握聚类算法基础原理基础上,掌握应用聚类算法解决实际问题。
实验内容
根据给定的实验数据,采用层次聚类、基于划分的聚类、密度聚类等算法对数据聚类。
实验要求:给出实际问题的解决方案,数据预处理过程、聚类算法的建立过程、结果分析。
资料下载
链接:https://pan.baidu.com/s/1GyJQ1mw0xqHnSQy6SxnT9g
提取码:0929
–来自百度网盘超级会员V2的分享
参考文献:李贤平.《红楼梦》成书新说.复旦学报(社会科学版).1987年第5期.
实验过程:
问题分析:
根据书写的习惯的特征,每个人进行书写时,会有习惯上的偏好,根据偏好可以进行虚词的方面的词频的统计,并通过对比每一个章节的比较,可以得出一篇文章的作者的有几个,并可以推理得到每个作者的每个章节的书写。
解决思路:
- 数据的读取(注意数据的编码格式),并对文本的每个章节进行划分(需要使用正则表达式)
- 数据预处理,统计每一个章节中的虚词对应出现的次数和频率
- 数据预处理,将统计得到的虚词出现的频率进行最大最小标准化处理
- 进行均值聚类的分析
- 进行层次聚类的分析
- 展示结果
代码:
代码一:
import numpy as np
from sklearn.cluster import KMeans
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import MinMaxScaler
import re#正则表达式(re模块)
def get_data():
big_xuci = ['之', '其', '或', '亦', '方', '于', '即', '皆', '因', '仍', '故', '尚', '乃',
'呀', '吗', '咧', '罢咧', '啊', '罢', '罢了', '么', '呢',
'了', '的', '着', '一', '不', '把', '让', '向', '往', '是', '在', '别', '好',
'可', '便', '就', '但', '越', '再', '更', '比', '很', '偏']
# xuci:18个常用虚词
# xuci=['而','何','乎','乃','其','且','若','所','为','焉','也','以','因','于','与','则','者','之']
f = open('./data/《红楼梦》完整版.txt', encoding='utf-8')
s = f.read()
# 章节划分
# 建立章节名的正则表达式
rule = re.compile('第[一二三四五六七八九十百]+回 ')
zj = rule.split(s)#将数据按照章节进行切分
zj = zj[1:]#跳过了第一行
print("输出一下第二章的内容:")
print(zj[1])
print('总共'+str(len(zj))+'章')
data = np.zeros([len(zj), len(big_xuci)])
for i in range(len(zj)):
for j in range(len(big_xuci)):
data[i, j] = zj[i].count(big_xuci[j])
# 这里使用的是该章中,该虚词在该章出现次数占该章统计的全部虚词出现的次数
sdata = np.zeros([len(data), len(big_xuci)])
for i in range(len(data)):
for j in range(len(big_xuci)):
sdata[i, j] = data[i, j] / sum(data[i])
# 归一化
print("每一章节中每个虚词出现的次数:")
print(sdata)
scaler = MinMaxScaler().fit(sdata)
ndata = scaler.transform(sdata)
return ndata
# 1------kmeans聚类------
def kMmeans_data(data):
kmeans = KMeans(n_clusters=2).fit(data)
jg = kmeans.labels_
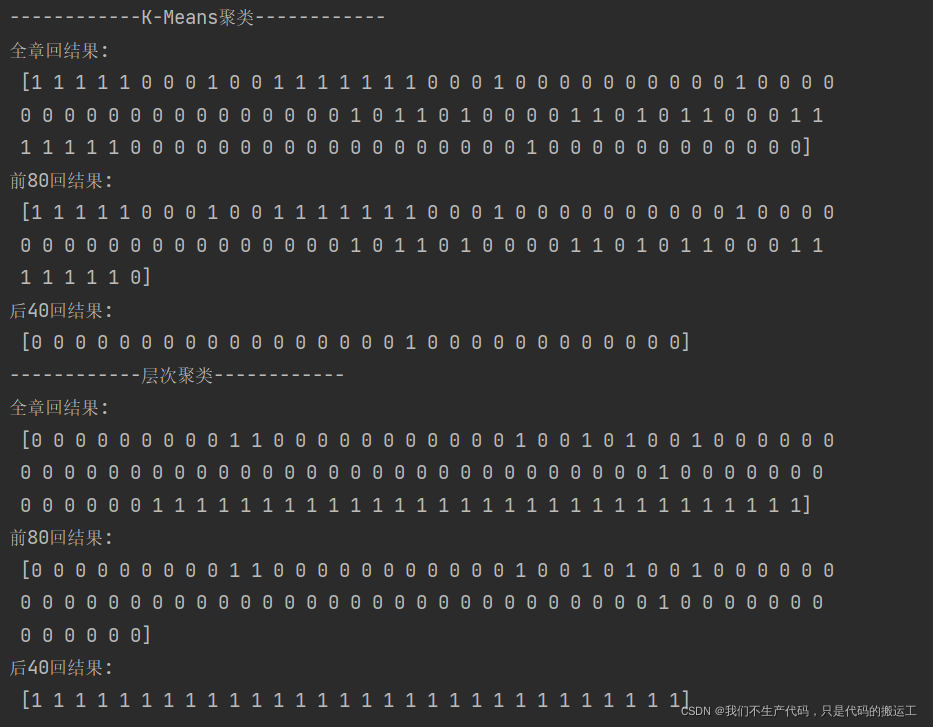
print('------------K-Means聚类------------')
print('全章回结果:\n', jg)
print('前80回结果:\n', jg[:80])
print('后40回结果:\n', jg[80:])
# 2------层次聚类------
def AgglomerativeClustering_data(data):
agg = AgglomerativeClustering(linkage='ward', n_clusters=2).fit(data)
print('------------层次聚类------------')
print('全章回结果:\n', agg.labels_)
print('前80回结果:\n', agg.labels_[:80])
print('后40回结果:\n', agg.labels_[80:])
if __name__ == '__main__':
data = get_data()
# 1------kmeans聚类------
kMmeans_data(data)
# 2------层次聚类------
AgglomerativeClustering_data(data)
出现的问题
文件编码问题
数据保存时,保存为UTF-8编码
将红楼梦数据,按照章节进行划分(使用到了正则表达式)
import re#正则表达式(re模块)
# 章节划分
# 建立章节名的正则表达式
rule = re.compile('第[一二三四五六七八九十百]+回 ')
zj = rule.split(s)#将数据按照章节进行切分
zj = zj[1:]#跳过了第一行
print("输出一下第二章的内容:")
print(zj[1])
print('总共'+str(len(zj))+'章')

 ### 统计每章中对应虚词出现的次数(词频:每个虚词在具体的某一章中出现的频率)
### 统计每章中对应虚词出现的次数(词频:每个虚词在具体的某一章中出现的频率)
data = np.zeros([len(zj), len(big_xuci)])
for i in range(len(zj)):
for j in range(len(big_xuci)):
data[i, j] = zj[i].count(big_xuci[j])
# 这里使用的是该章中,该虚词在该章出现次数占该章统计的全部虚词出现的次数
sdata = np.zeros([len(data), len(big_xuci)])
for i in range(len(data)):
for j in range(len(big_xuci)):
sdata[i, j] = data[i, j] / sum(data[i])
数据进行标准化处理(最大最小标准化)
# 归一化
print("每一章节中每个虚词出现的次数:")
print(sdata)
scaler = MinMaxScaler().fit(sdata)
ndata = scaler.transform(sdata)
使用了两种聚类方法(均值聚类和层次聚类)
# 1------kmeans聚类------
def kMmeans_data(data):
kmeans = KMeans(n_clusters=2).fit(data)
jg = kmeans.labels_
print('------------K-Means聚类------------')
print('全章回结果:\n', jg)
print('前80回结果:\n', jg[:80])
print('后40回结果:\n', jg[80:])
# 2------层次聚类------
def AgglomerativeClustering_data(data):
agg = AgglomerativeClustering(linkage='ward', n_clusters=2).fit(data)
print('------------层次聚类------------')
print('全章回结果:\n', agg.labels_)
print('前80回结果:\n', agg.labels_[:80])
print('后40回结果:\n', agg.labels_[80:])
代码二:(实现可视化)
import numpy as np
from sklearn.cluster import KMeans
from sklearn.cluster import AgglomerativeClustering
from sklearn.preprocessing import MinMaxScaler
import re#正则表达式(re模块)
import scipy.cluster.hierarchy as sch
from matplotlib import pyplot as plt
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
def get_data():
big_xuci = ['之', '其', '或', '亦', '方', '于', '即', '皆', '因', '仍', '故', '尚', '乃',
'呀', '吗', '咧', '罢咧', '啊', '罢', '罢了', '么', '呢',
'了', '的', '着', '一', '不', '把', '让', '向', '往', '是', '在', '别', '好',
'可', '便', '就', '但', '越', '再', '更', '比', '很', '偏']
# xuci:18个常用虚词
# xuci=['而','何','乎','乃','其','且','若','所','为','焉','也','以','因','于','与','则','者','之']
f = open('./data/《红楼梦》完整版.txt', encoding='utf-8')
s = f.read()
# 章节划分
# 建立章节名的正则表达式
rule = re.compile('第[一二三四五六七八九十百]+回 ')
zj = rule.split(s)#将数据按照章节进行切分
zj = zj[1:]#跳过了第一行
print("输出一下第二章的内容:")
print(zj[1])
print('总共'+str(len(zj))+'章')
data = np.zeros([len(zj), len(big_xuci)])
for i in range(len(zj)):
for j in range(len(big_xuci)):
data[i, j] = zj[i].count(big_xuci[j])
# 这里使用的是该章中,该虚词在该章出现次数占该章统计的全部虚词出现的次数
sdata = np.zeros([len(data), len(big_xuci)])
for i in range(len(data)):
for j in range(len(big_xuci)):
sdata[i, j] = data[i, j] / sum(data[i])
# 归一化
print("每一章节中每个虚词出现的次数:")
print(sdata)
scaler = MinMaxScaler().fit(sdata)
ndata = scaler.transform(sdata)
return ndata
# 1------kmeans聚类------
def kMmeans_data(data):
kmeans = KMeans(n_clusters=2).fit(data)
jg = kmeans.labels_
print('------------K-Means聚类------------')
print('全章回结果:\n', jg)
print('前80回结果:\n', jg[:80])
print('后40回结果:\n', jg[80:])
# 2------层次聚类------
def AgglomerativeClustering_data(data):
agg = AgglomerativeClustering(linkage='ward', n_clusters=2).fit(data)
print('------------层次聚类------------')
print('全章回结果:\n', agg.labels_)
print('前80回结果:\n', agg.labels_[:80])
print('后40回结果:\n', agg.labels_[80:])
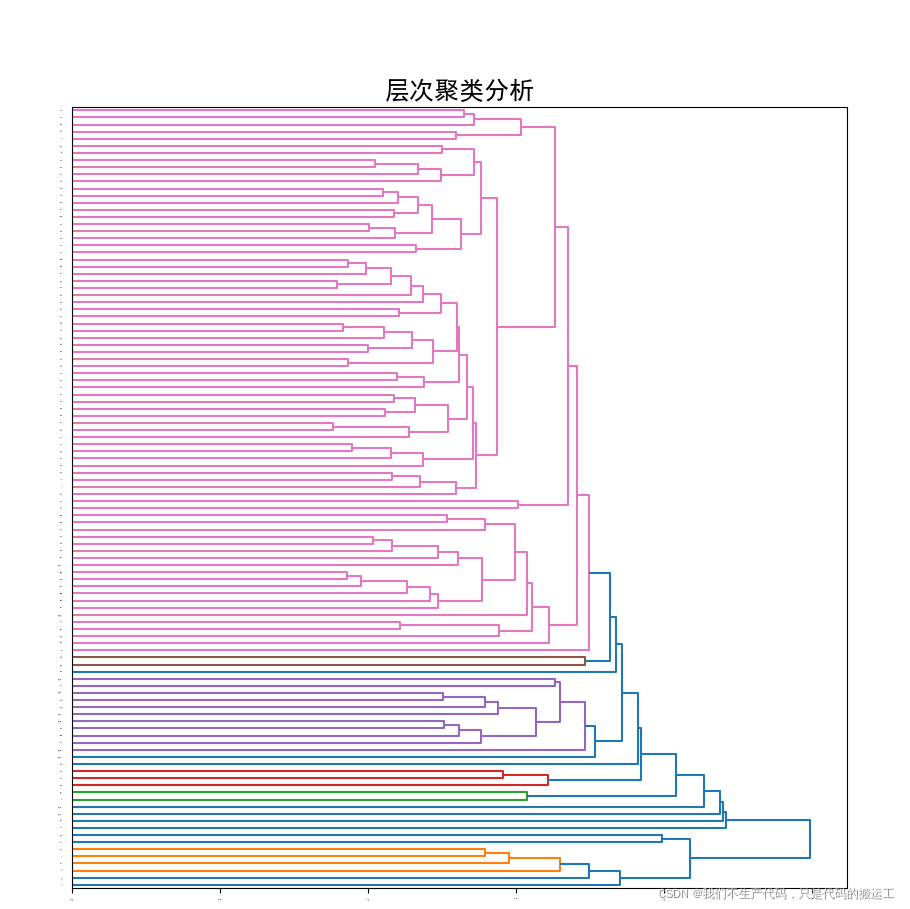
def draw_picture(data):
plt.figure(figsize=(10, 25))
Z = sch.linkage(data, method='average')#进行层次聚类/凝聚聚类。UPGMA算法(非加权组平均)法。
P = sch.dendrogram(Z, orientation="right")
plt.tick_params(labelsize=2)
plt.savefig('./res1.png')
plt.title('层次聚类分析', fontsize=18)
plt.show()
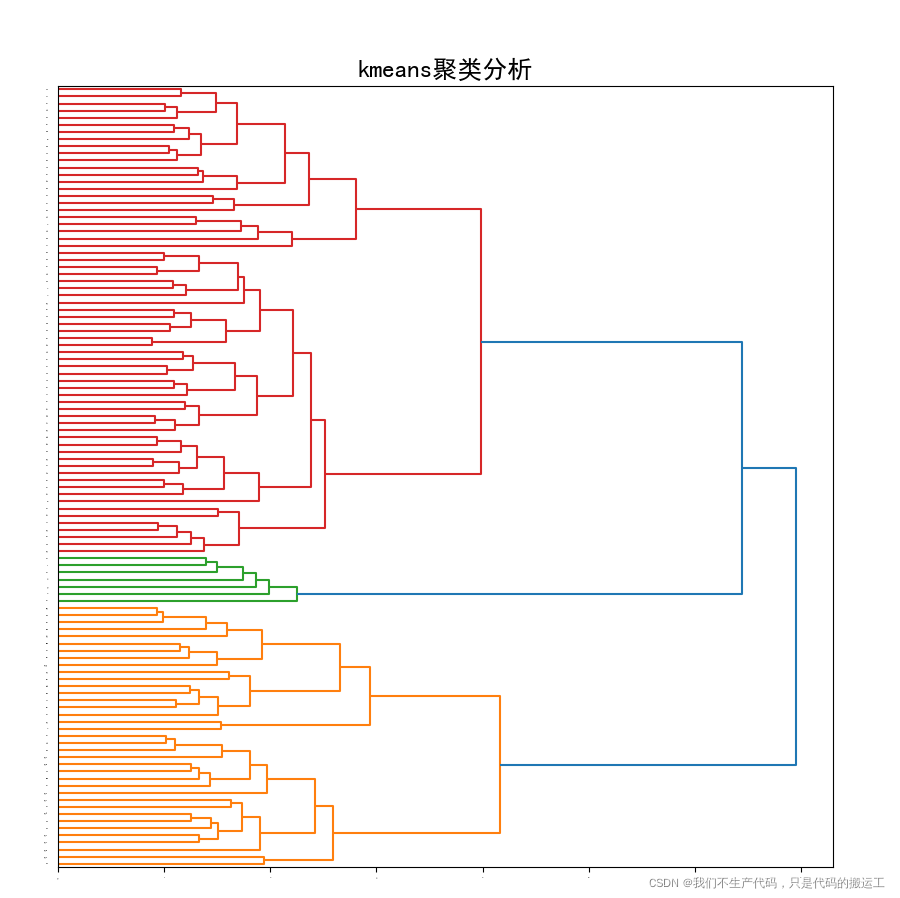
plt.figure(figsize=(10, 25))
Z = sch.linkage(data, method='ward')#(沃德方差最小化算法)
P = sch.dendrogram(Z, orientation="right")
plt.tick_params(labelsize=2)
plt.savefig('./res2.png')
plt.title('kmeans聚类分析', fontsize=18)
plt.show()
if __name__ == '__main__':
data = get_data()
# 1------kmeans聚类------
kMmeans_data(data)
# 2------层次聚类------
AgglomerativeClustering_data(data)
#画一下图片
draw_picture(data)
出现的问题
画图时中文显示问题
#解决中文显示问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False

















 9291
9291




 到【灌水乐园】发言
到【灌水乐园】发言







