




 本文探讨了机器学习中数据预处理的重要环节——特征编码,特别是针对离散数据的标签编码和独热编码。标签编码将分类特征转化为数字,适用于定序数据和对数值大小不敏感的模型。独热编码则解决分类变量问题,适用于定类数据,但可能导致维度灾难。sklearn库提供了LabelEncoder和OneHotEncoder工具进行这些编码操作。
本文探讨了机器学习中数据预处理的重要环节——特征编码,特别是针对离散数据的标签编码和独热编码。标签编码将分类特征转化为数字,适用于定序数据和对数值大小不敏感的模型。独热编码则解决分类变量问题,适用于定类数据,但可能导致维度灾难。sklearn库提供了LabelEncoder和OneHotEncoder工具进行这些编码操作。
机器学习之数据预处理——特征编码
机器学习里有一句名言:数据和特征决定了机器学习的上限,而模型和算法的应用只是让我们逼近这个上限。这个说法形象且深刻的提出前期数据处理和特征分析的重要性。这一点从我们往往用整个数据挖掘全流程60%以上的时间和精力去做建模前期的数据处理和特征分析也能看出。那么疑问来了,这超过60%时间和精力我们都用在哪了?本文基于以往的知识储备以及实际的项目经验,我做一个总结。
主要包括三部分,一是获取数据、数据抽样,二是数据探索,三是数据预处理与清洗
数据预处理——特征编码
由于机器学习算法都是在矩阵上执行线性代数计算,所以参加计算的特征必须是数值型的,对于非数值型的特征需要进行编码处理。对于离散型数据的编码,我们通常会使用两种方式来实现,分别是标签编码和独热编码
离散数据的编码
对于离散型数据的编码,我们通常会使用两种方式来实现,分别是标签编码和独热编码
标签编码
将类别型特征从字符串转换为数字
先说结论:OneHotEncoder更常用,LabelEncoder目前应用场景不多
特点:
- 解决了分类编码的问题,可以自由定义量化数字
- 数值本身没有任何含义,仅是标识或者排序的作用
- 可解释性比较差
适用范围:
- 对于定序类型的数据,使用标签编码更好,虽然定序类型也属于分类,但是其有排序逻辑
- 对数值大小不敏感的模型(如树模型),建议使用标签编码
sklearn LabelEncoder(使用fit_transform函数)
将离散型的数据转换成 0 0 0 到 n − 1 n − 1 n−1 之间的数
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
print(df)
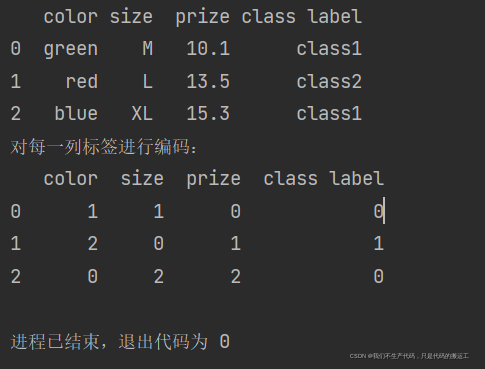
print("对每一列标签进行编码:")
# 将类别标签转化为数值
class_le = LabelEncoder()
df['color'] = class_le.fit_transform(df['color'])
df['size'] = class_le.fit_transform(df['size'])
df['prize'] = class_le.fit_transform(df['prize'])
df['class label'] = class_le.fit_transform(df['class label'])
print(df)
sklearn LabelEncoder(反向变换可以用函数 inverse_transform)
import pandas as pd
from sklearn.preprocessing import LabelEncoder
df = pd.DataFrame([
['green', 'M', 10.1, 'class1'],
['red', 'L', 13.5, 'class2'],
['blue', 'XL', 15.3, 'class1']])
df.columns = ['color', 'size', 'prize', 'class label']
print(df)
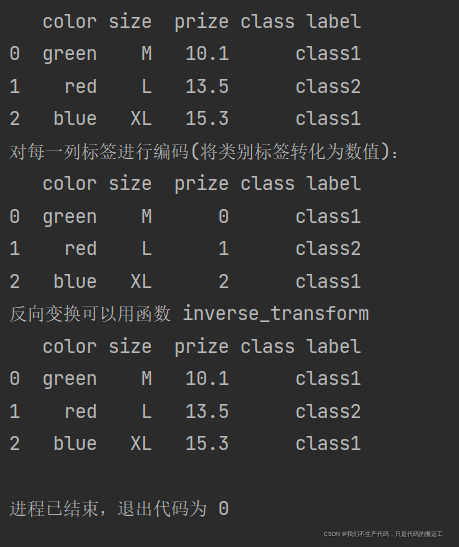
print("对每一列标签进行编码(将类别标签转化为数值):")
class_le = LabelEncoder()
df['prize'] = class_le.fit_transform(df['prize'])
print(df)
print("反向变换可以用函数 inverse_transform")
df['prize'] = class_le.inverse_transform(df['prize'])
print(df)
独热编码
采用 N 位状态寄存器来对 N 个可能的取值进行编码,每个状态都由独立的寄存器来表示,并且在任意时刻只有其中一位有效
特点:
- 解决了分类器不好处理分类变量的问题,同时也可以扩展特征
- 编码后的属性是稀疏的,存在大量的零元分量
- 当类别非常多时,特征空间会非常大,容易导致维度灾难的问题
适用范围:
- 适用于定类类型的数据,该类型数据是纯分类,不进行排序,互相之间也没有逻辑关系
- 对数值大小敏感的模型,必须使用独热编码
sklearn OneHotEncoder
import numpy as np
from sklearn.preprocessing import OneHotEncoder
data = ['cold', 'cold', 'warm', 'cold', 'hot', 'hot', 'warm', 'cold', 'warm', 'hot']
values = np.array(data)
values.shape # (10,)
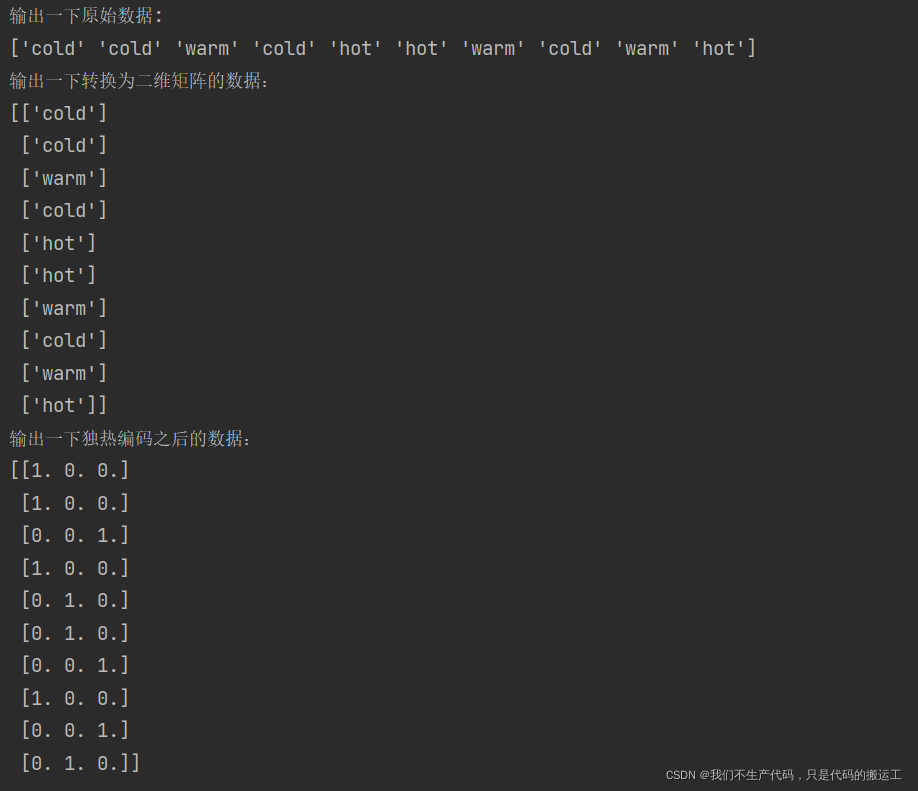
print("输出一下原始数据:")
print(values)
# 必须转换为二维得矩阵
values_reshape = values.reshape((-1,1)) # (10, 1)
print("输出一下转换为二维矩阵的数据:")
print(values_reshape)
onehot_encoder = OneHotEncoder(sparse=False)
values_onehot=onehot_encoder.fit_transform(values_reshape)
print("输出一下独热编码之后的数据:")
print(values_onehot)
 优秀文章:
优秀文章:
数据预处理:独热编码(One-Hot Encoding)和 LabelEncoder标签编码
独热编码(One-Hot)最简洁理解


















 967
967

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









