







学习参考:
图像预期处理 | 图像增强 |torchvision.transforms() 常用函数_哔哩哔哩_bilibili
图像增强
数据增强可以增加训练集的样本数量,缓解过拟合,并提高模型的泛化能力,从而有效提升算法的性能。

图像预处理
- 将图像转换成 tensor 的数据格式
- 将图像的 像素值范围 由 0~255 转换到 0~1
- (height, width, channel) =====>>> (channel, height, width)
- 归一化图像
- 归一化可以优化算法的收敛速度和性能,和 BN 层的作用差不多。
- 归一化处理还可以消除不同图像之间的亮度和颜色差异,提高模型的鲁棒性。
代码
图像增强/预处理在代码中的流程:
这部分操作是在Dataset内部完成
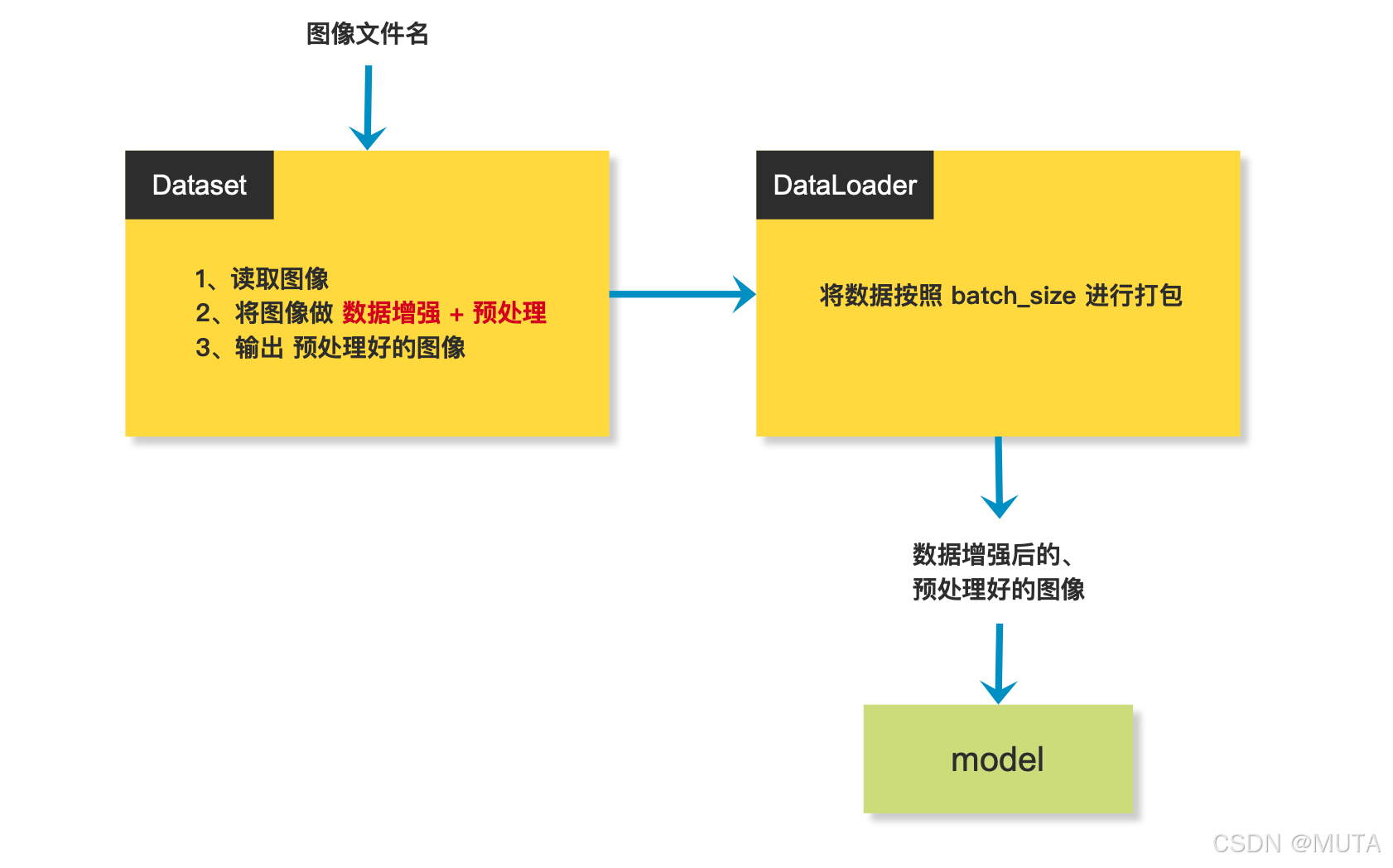
通常会有以下代码块出现在Dataset中,做图像增强/预处理
import torchvision.transforms as transforms
trans = transforms.Compose([transforms.RandomResizedCrop((640, 640)),
transforms.RandomHorizontalFlip(0.5),
transforms.ColorJitter(0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])
torchvision.transforms()常用函数
官方文档地址: https://pytorch.org/vision/stable/transforms.html
1. transforms.RandomResizedCrop 随机尺寸裁剪
import torchvision.transforms as transforms
resized_crop = transforms.RandomResizedCrop(size=(224, 224),
scale=(0.08, 1.0),
ratio=(0.75, 1.3333333333333333),
interpolation=transforms.InterpolationMode.BILINEAR)参数:
- size:期望的输出图像尺寸, 可以是 int值,也可可以是元组(H, W)
- scale :在调整大小之前指定裁剪的随机区域的下界和上界。尺度是根据原始图像的面积来定义的。
- ratio:在调整大小之前,裁剪的随机纵横比的下限和上限。
- InterpolationMode : 插值方式
- InterpolationMode.NEAREST:最近邻插值。
- InterpolationMode.BILINEAR:双线性插值 (默认)
- InterpolationMode.BICUBIC:双三次插值。
上方代码解释:
1、将图像进行随机裁剪,裁剪满足以下条件:
裁剪后的图像 面积 与原图像的面积的比例 在 0.08 ~ 1
裁剪后的图像高宽比范围在 0.75 ~ 1.33之间
2、按照指定的插值方式, 将图像尺寸缩放到 (224, 224)
2. 水平翻转与垂直翻转
horizontal_flip = transforms. RandomHorizontalFlip(0.5)
vertical_flip = transforms. RandomVerticalFlip(0.5)0.5是指随机翻转的概率
3. ColorJitter颜色调整
color_jitter = transforms. ColorJitter(brightness=0,
contrast=0,
saturation=0,
hue=0)参数:
- brightness:亮度调整系数。 ;调整范围为 [ 1-brightness, 1+brightness ],默认值为 0。
- contrast:对比度调整系数。 ;调整范国为 [ 1一 contrast, 1+contrast ],默认值为 0。
- saturation:饱和度调整系数。 ;调整范围为 [ 1- saturation, 1+ saturation ],默认值为 0。
- hue:色调调整系数。 ;调整范围为 [ -hue, hue ],默认值为 0。
4. torchvision.transforms.ToTensor()
torchvision.transforms.ToTensor() 做了三件事:
- 将图像的数据格式由 nump.ndarray 或 PIL.Image 转为 tensor,数据类型为 torch.FloatTensor
- 将像素值范围从 0-255 转换到 0-1之间, 处理方式 :直接除以255
- 将 shape=(H,W, C) 转换为 shape= (C, H, W)

5. torchvision.transforms.Normalize()
作用:用均值和标准差对张量图像进行归一化,一般在 torchvision.transforms.ToTensor() 之后使用
在使用 torchvision.transforms.ToTensor() 之后,像素值取值范围会被转换到 [0, 1]之间,再使用 transforms.Normalize(mean, std) 进行归一化后,原像素值就被分布到了 [-1, 1] 之间:
公式:
- 原来的 0~1 最小值 0 则变成 (0 - mean) / std = -1
- 最大值1则变成 (1 - mean) / std = 1
一般 mean 和 std 会分别指定3个值,代表图像3个通道的均值和方差,比如torchvision.transforms.Normalize(mean=[0.5, 0.5, 0.5], std=[0.5, 0.5, 0.5])
如果是单通道的灰度图,均值为0.5,方差为0.5,可以写成 transforms.Normalize(mean=[0.5], std=[0.5])
我们可能会看到很多代码里面是这样写的:
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
这一组数字怎么来的?
通过 ImageNet数据集,提前计算出来的。
因为 ImageNet数据集 是一个大型数据集,由一个大型数据集统计出来的均值和方差,基本符合所有数据集的像素值分布,所以可以直接使用。
重新计算并使用自己数据集的均值和方差也是可以的,就是开销比较大,所以,一般直接使用
mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225]
6. transforms.Compose()
训练阶段:
trans = transforms.Compose([transforms.RandomResizedCrop((640, 640)),
transforms.RandomHorizontalFlip(0.5),
transforms.ColorJitter(0.5),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])推理阶段:
推理阶段不会再对数据进行增强,只会做基础的预处理,比如:将尺寸处理到固定尺寸 ;使用 ToTensor 处理数据; Normalize 归一化
trans = transforms.Compose([transforms.RE((640, 640)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])疑惑:
这些图像增强的数据直接传入模型进行训练,并没有同时用到原来的数据,这样其实数据集的数量并没有发生改变,还会导致图像数据域的偏移,这样不会对结果产生负面影响吗?



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











