



重点:给大家推荐一个学习网站https://github.com/0voice
C++新特性主要包括包含语法改进和标准库扩充两个方面,主要包括以下11点:
1. 语法的改进
(1) 统一的初始化方法
在 C++11 中,统一初始化(Uniform Initialization)使用花括号 {} 来初始化对象。这种方式在各个类型之间提供了一致的语法,减少了歧义,并且可以避免某些常见的初始化错误。
1. 示例代码
#include <iostream>
class Foo {
public:
Foo(int) { std::cout << "Foo constructed with int\n"; }
private:
Foo(const Foo&); // 私有拷贝构造函数
};
int main() {
Foo a1(123); // 直接初始化
Foo a2 = 123; // 错误,无法使用私有拷贝构造函数
Foo a3 = { 123 }; // 列表初始化,使用的是构造函数
Foo a4{ 123 }; // 另一种列表初始化
int a5 = { 3 }; // 列表初始化,基本数据类型
int a6{ 3 }; // 另一种列表初始化
return 0;
}2. 优点
-
避免窄化转换:统一初始化可以防止类型窄化(narrowing conversions),即从一个大范围类型转换为一个小范围类型的情况。例如:
int x{3.14}; // 错误:不允许窄化转换 -
一致性:无论是基本类型、类类型还是 STL 容器,使用相同的语法来初始化,提高了代码的可读性。
-
调用构造函数:即使使用等号
=,列表初始化也会调用相应的构造函数,而不会进行拷贝,这在有私有拷贝构造函数的情况下尤其重要。 -
支持聚合类型初始化:如结构体和数组,可以方便地使用花括号初始化。
struct Point { int x; int y; }; -
Point p1{1, 2}; // 使用列表初始化
3. 注意事项
-
当使用
{}进行初始化时,如果初始化的值不匹配目标类型的构造函数,编译器将会报错。 -
在某些情况下,使用
{}进行初始化可能会与 C++98/03 的某些初始化方式产生冲突,因此在迁移旧代码时需要小心。
(2) 成员变量默认初始化
通过在类内部直接为成员变量赋初值,可以确保每次创建对象时,这些成员都有默认值。这在不需要构造函数的情况下,可以大大简化代码。
示例代码
#include <iostream>
using namespace std;
class B {
public:
int m = 1234; // 成员变量 m 具有默认值
int n; // n 没有初始化,将使用默认值 0
};
int main() {
B b; // 创建对象 b
cout << "m: " << b.m << endl; // 输出 m 的值,1234
cout << "n: " << b.n << endl; // 输出 n 的值,0(未初始化会默认为 0)
return 0;
}
主要优点
-
简化初始化:
-
可以省去在构造函数中为每个成员变量手动初始化的步骤,减少了冗余代码。
-
-
提高可读性:
-
类的定义中清晰地指出了每个成员变量的默认值,使得代码的意图更加明确。
-
-
避免未初始化:
-
确保成员变量在对象创建时有初始值,减少了使用未初始化变量导致的潜在错误。
-
-
与构造函数结合使用:
-
允许在构造函数中仅初始化特定的成员变量,默认值仍然适用。
-
注意事项
-
如果成员变量在类的构造函数中被赋予其他值,则该默认值将被覆盖。
-
如果成员变量是类类型且没有提供默认构造函数,编译会报错。
-
成员变量的默认初始化只适用于类和结构体,不适用于非静态数据成员的初始化。
(3) auto 关键字
用于定义变量,编译器可以自动判断的类型(前提:定义一个变量时对其进行初始化)。
#include <iostream>
#include <vector>
using namespace std;
int main() {
// 定义一个嵌套 vector
vector<vector<int>> v = {{1, 2, 3}, {4, 5, 6}};
// 传统的迭代器定义
vector<vector<int>>::iterator it = v.begin();
// 使用 auto 进行类型推导
auto it_auto = v.begin(); // 更简洁的写法
// 输出结果
for (auto inner : *it_auto) {
cout << inner << " "; // 输出 1 2 3
}
cout << endl;
auto x = 5; // x 是 int
auto y = 3.14; // y 是 double
return 0;
}优点
-
简洁性:
-
使用
auto可以避免冗长的类型声明,特别是在处理复杂类型时,代码更加简洁易读。
-
-
减少错误:
-
省去手动输入复杂类型的过程,降低了由于类型错误导致的编译错误。
-
-
提高可维护性:
-
当类型发生变化时,只需修改初始化表达式,其他使用
auto的地方无需改动。
-
-
适应性:
-
在需要与 STL 容器或算法结合使用时,
auto可以自动适应返回类型,提供更大的灵活性。
-
注意事项
-
auto类型推导需要初始化;如果没有初始化,编译器无法推导类型。 -
在某些情况下,使用
auto可能会导致类型不如预期。例如,使用auto对指针进行推导时,可能会推导成值类型。
(4) decltype
decltype 的作用
decltype 是 C++11 新增的关键字,用于在编译时获取表达式的类型。与 auto 类似,decltype 能够简化类型的书写,但它的使用场景更加广泛。
为什么要使用 decltype
-
自动类型推导:在一些情况下,使用
auto无法满足需求,尤其是当需要根据表达式的结果类型进行推导时。 -
不需要初始化:与
auto不同,decltype不需要在声明时初始化变量,因此适用于更广泛的场景。
auto 与 decltype 的区别
-
初始化要求:
-
auto需要在声明时提供初始值。 -
decltype不需要初始值,可以在声明时只依赖于表达式。
-
-
推导依据:
-
auto根据赋值右边的初始值进行推导。 -
decltype根据表达式的类型进行推导。
-
示例代码
以下是 decltype 的一些用法示例:
#include <iostream>
int main() {
int a = 0;
decltype(a) b = 1; // b 被推导成 int
std::cout << "b: " << b << std::endl; // 输出 1
decltype(10.8) x = 5.5; // x 被推导成 double
std::cout << "x: " << x << std::endl; // 输出 5.5
decltype(x + 100) y; // y 被推导成 double
y = x + 100;
std::cout << "y: " << y << std::endl; // 输出 105.5
// 使用 decltype 获取函数返回类型
auto lambda = [](int x) { return x * 2; };
decltype(lambda(0)) result = lambda(5); // result 被推导成 int
std::cout << "result: " << result << std::endl; // 输出 10
return 0;
}复杂场景
decltype 在处理复杂类型时尤其有用,例如在模板编程中,它可以用于获取模板参数的类型。
template <typename T>
void func(T t) {
decltype(t) var = t; // var 将具有与 t 相同的类型
std::cout << "var: " << var << std::endl;
}
(5) 智能指针 shared_ptr
shared_ptr 的工作原理
shared_ptr 是一种共享所有权的智能指针,允许多个 shared_ptr 实例共同管理同一块动态分配的内存。它使用引用计数机制来跟踪有多少个 shared_ptr 实例指向同一对象。只有当引用计数为零时,内存才会被释放。
代码示例
#include <iostream>
#include <memory>
using namespace std;
int main() {
// 创建一个 shared_ptr,管理一个动态分配的整数
std::shared_ptr<int> p1(new int(10));
std::shared_ptr<int> p2(p1); // p2 共享 p1 的所有权
// 输出 p2 指向的数据
cout << *p2 << endl; // 输出 10
// 重置 p1,引用计数减 1
p1.reset(); // p1 现在为空指针
// 检查 p1 是否为空
if (p1) {
cout << "p1 不为空" << endl;
} else {
cout << "p1 为空" << endl; // 会输出这个
}
// p2 仍然有效
cout << *p2 << endl; // 输出 10
// 输出当前指向同一对象的 shared_ptr 数量
cout << "当前引用计数: " << p2.use_count() << endl; // 输出 1
return 0;
}
输出结果
10
p1 为空
10
当前引用计数: 1
shared_ptr 与其他智能指针的区别
-
unique_ptr:-
只有一个
unique_ptr可以管理一个对象,不能复制,只能转移所有权。 -
适用于明确的独占所有权场景。
-
不支持引用计数,内存会在
unique_ptr作用域结束时立即释放。
std::unique_ptr<int> up1(new int(10)); // std::unique_ptr<int> up2 = up1; // 错误,不能复制 std::unique_ptr<int> up2 = std::move(up1); // 转移所有权 -
-
weak_ptr:-
不是拥有对象的所有权,只能观察
shared_ptr管理的对象。 -
不会增加引用计数,主要用于防止循环引用。
-
当
shared_ptr的引用计数降为零时,weak_ptr也会失效。
-
std::shared_ptr<int> sp1(new int(20));
std::weak_ptr<int> wp1 = sp1; // wp1 观察 sp1
if (auto sp2 = wp1.lock()) { // 尝试获取 shared_ptr
cout << *sp2 << endl; // 输出 20
}(6) 空指针 nullptr
nullptr 是类型安全的空指针,替代了 NULL。
nullptr 的特点
-
类型安全:
-
nullptr是nullptr_t类型的一个实例,能够被隐式转换为任何指针类型,而不可能被误用为整数或其他类型。这解决了NULL在某些情况下被视为整型的问题。
-
-
消除歧义:
-
在函数重载的情况下,
nullptr可以避免因NULL是整数类型而引发的模糊性。
-
-
更好的可读性:
-
使用
nullptr使得代码的意图更加明确,表示一个空指针,而不是一个整型常量。
-
示例代码
#include <iostream>
using namespace std;
void isnull(void* c) {
cout << "void* c" << endl;
}
void isnull(int n) {
cout << "int n" << endl;
}
int main() {
isnull(NULL); // 调用 int n 版本
isnull(nullptr); // 调用 void* c 版本
int* a1 = nullptr; // int 指针初始化
char* a2 = nullptr; // char 指针初始化
double* a3 = nullptr; // double 指针初始化
cout << "a1: " << a1 << ", a2: " << a2 << ", a3: " << a3 << endl;
return 0;
}输出结果
int n
void* c
a1: 0, a2: 0, a3: 0
nullptr 与 NULL 的区别
-
类型:
-
NULL通常定义为0或((void*)0),在不同上下文中可能导致类型混淆。 -
nullptr是专门用于指针的类型,类型安全且避免了重载歧义。
-
-
使用场景:
-
nullptr在现代 C++ 编程中推荐使用,尤其是在函数重载和模板编程中。
-
(7) 基于范围的 for 循环
原始 for 循环遍历数组和 vector
示例代码
#include <iostream>
#include <vector>
#include <cstring> // 注意要包含这个头文件以使用 strlen
using namespace std;
int main() {
char arc[] = "www.123.com";
int i;
// 使用 for 循环遍历普通数组
for (i = 0; i < strlen(arc); i++) {
cout << arc[i]; // 输出数组中的每个字符
}
cout << endl;
// 创建 vector 并初始化
vector<char> myvector(arc, arc + 3);
vector<char>::iterator iter;
// 使用 for 循环遍历 vector 容器
for (iter = myvector.begin(); iter != myvector.end(); ++iter) {
cout << *iter; // 输出 vector 中的每个元素
}
cout << endl;
return 0;
}输出结果
www.123.com
www
代码解释
-
遍历普通数组:
-
使用
strlen函数获取数组的长度,并使用for循环遍历每个字符。 -
arc[i]访问数组的每个元素。
-
-
遍历
vector容器:-
vector<char> myvector(arc, arc + 3);创建一个vector,并用数组的前 3 个字符初始化它。 -
使用迭代器遍历
vector,通过begin()和end()获取起始和结束位置。
-
C++11 中的基于范围的 for 循环
C++11 引入了基于范围的 for 循环,这种语法使得遍历容器更加简洁和易读。以下是如何使用它来遍历数组和 vector 的示例。
#include <iostream>
#include <vector>
#include <cstring>
using namespace std;
int main() {
char arc[] = "www.123.com";
// 使用基于范围的 for 循环遍历普通数组
for (char c : arc) {
cout << c; // 输出数组中的每个字符
}
cout << endl;
// 创建 vector 并初始化
vector<char> myvector(arc, arc + 3);
// 使用基于范围的 for 循环遍历 vector 容器
for (char c : myvector) {
cout << c; // 输出 vector 中的每个元素
}
cout << endl;
return 0;
}
优势
-
简洁性:基于范围的
for循环语法更简洁,无需显式声明迭代器或管理循环条件。 -
可读性:代码更易读,意图明确,适合快速遍历容器。
(8) 右值引用和移动语义
1. 右值引用
概念
右值引用用 && 表示,允许我们引用那些临时对象(右值),并能够修改它们。C++11 中引入右值引用的主要目的是实现移动语义,以提高性能。
#include <iostream>
using namespace std;
int main() {
int num = 10;
// 左值引用
int &b = num; // 正确
// int &c = 10; // 错误,不能绑定右值
// 常量左值引用
const int &d = 10; // 正确,可以绑定右值
// 右值引用
int &&a = 10; // 正确
a = 100; // 可以修改右值引用
cout << a << endl; // 输出 100
// 常量右值引用(无实际用处)
const int&& e = 10; // 编译器不会报错
return 0;
}
2. 移动语义
概念
移动语义允许资源的“移动”而不是“复制”,从而提高性能。std::move 函数将一个左值转换为右值,使得可以调用移动构造函数或移动赋值运算符。
#include <iostream>
#include <utility> // 包含 std::move
using namespace std;
class First {
public:
First() : num(new int(0)) {
cout << "construct!" << endl;
}
// 移动构造函数
First(First &&d) : num(d.num) {
d.num = nullptr; // 将源对象的指针置为 nullptr
cout << "first move construct!" << endl;
}
~First() {
delete num; // 释放资源
}
public:
int *num;
};
class Second {
public:
Second() : fir() {}
// 用 First 类的移动构造函数初始化 fir
Second(Second &&sec) : fir(move(sec.fir)) {
cout << "second move construct" << endl;
}
public:
First fir;
};
int main() {
Second oth;
Second oth2 = move(oth); // 通过 std::move 进行移动
// cout << *oth.fir.num << endl; // 运行时错误,因为 oth 的 fir 已经被移动
return 0;
}
输出:
construct!
first move construct!
second move construct
解释
-
右值引用:
-
int &&a = 10;创建一个右值引用,允许对右值进行修改。 -
常量右值引用的定义没有实际用途。
-
-
移动语义:
-
First类的移动构造函数允许资源(如动态分配的内存)从一个对象移动到另一个对象。 -
std::move(sec.fir)将sec.fir转换为右值,以调用移动构造函数。
-
2. 标准库扩充
(9) 无序容器
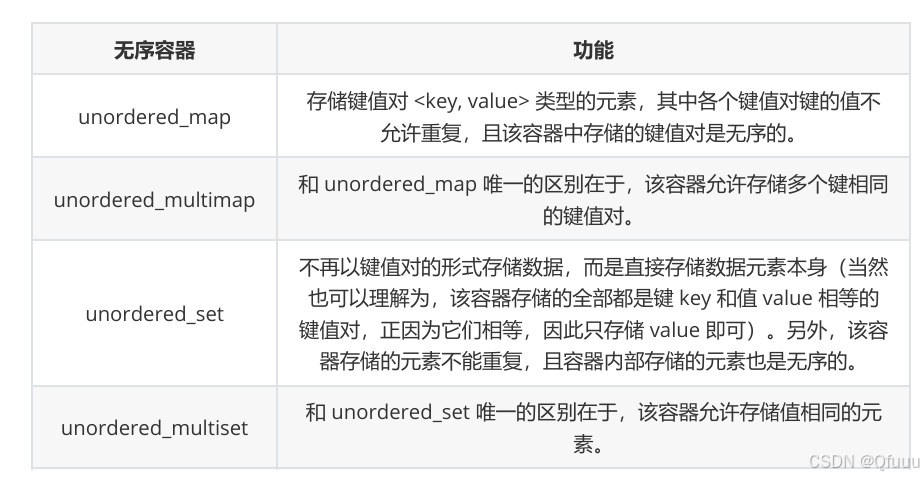
无序容器是一类使用哈希表实现的容器,主要包括以下四种类型:
-
unordered_map:存储键值对<key, value>,键不允许重复。 -
unordered_multimap:与unordered_map相似,但允许存储多个相同的键。 -
unordered_set:存储唯一的值,值本身就是元素。 -
unordered_multiset:与unordered_set相似,但允许存储多个相同的值。
特点
-
无序性:元素的存储位置由键决定,而非插入顺序。
-
查找效率:通过键查找值的平均时间复杂度为 O(1),高于关联式容器。
-
迭代效率:使用迭代器遍历时效率不如关联式容器。
示例代码
#include <iostream>
#include <string>
#include <unordered_map>
using namespace std;
int main() {
// 创建并初始化一个 unordered_map 容器
unordered_map<string, string> my_uMap{
{"教程1", "www.123.com"},
{"教程2", "www.234.com"},
{"教程3", "www.345.com"}
};
// 查找指定键对应的值
try {
string str = my_uMap.at("教程1"); // 查找存在的键
cout << "str = " << str << endl; // 输出: str = www.123.com
// 查找不存在的键,使用 at() 会抛出异常
string nonExistentStr = my_uMap.at("C语言教程");
cout << "nonExistentStr = " << nonExistentStr << endl;
} catch (const out_of_range& e) {
cout << "错误: " << e.what() << endl; // 处理键不存在的情况
}
// 使用迭代器遍历 unordered_map
cout << "遍历 unordered_map:" << endl;
for (auto iter = my_uMap.begin(); iter != my_uMap.end(); ++iter) {
cout << iter->first << " " << iter->second << endl; // 输出键值对
}
return 0;
}输出结果
str = www.123.com
遍历 unordered_map:
教程1 www.123.com
教程2 www.234.com
教程3 www.345.com
代码解释
-
初始化:
-
使用初始化列表创建一个
unordered_map,键和值都是string类型。
-
-
查找值:
-
使用
at()方法查找对应的值,如果键不存在,会抛出out_of_range异常。
-
-
遍历:
-
使用迭代器遍历整个容器,并打印出每个键值对。
-
(10) 正则表达式
正则表达式是字符串处理中的强大工具,用于描述字符串的模式并进行匹配和替换。
#include <regex>
std::regex pattern("^[a-z]+");
常用符号及其意义
| 符号 | 意义 | 示例 | 解释 |
|---|---|---|---|
^ | 匹配行的开头 | ^abc | 匹配以 "abc" 开头的字符串 |
$ | 匹配行的结尾 | xyz$ | 匹配以 "xyz" 结尾的字符串 |
. | 匹配任意单个字符 | a.b | 匹配 "a" 后面跟着任意一个字符和 "b" |
[...] | 匹配方括号内的任意一个字符 | [abc] | 匹配 "a"、"b" 或 "c" 中的任意一个字符 |
(…) | 设定分组 | (abc) | 捕获 "abc" 作为一个组 |
\ | 转义字符 | \. | 匹配 "." 字符本身 |
\d | 匹配数字(0-9) | \d{3} | 匹配任意三位数字 |
\D | 匹配非数字字符 | \D | 匹配任意非数字字符 |
\w | 匹配字母、数字及下划线 | \w+ | 匹配一个或多个字母、数字或下划线 |
\W | 匹配非字母、数字或下划线 | \W | 匹配任意非字母、数字或下划线 |
\s | 匹配空格、制表符等空白字符 | \s+ | 匹配一个或多个空白字符 |
\S | 匹配非空白字符 | \S | 匹配任意非空白字符 |
+ | 前面的元素重复 1 次或多次 | a+ | 匹配一个或多个 "a" |
* | 前面的元素重复 0 次或多次 | b* | 匹配 0 个或多个 "b" |
? | 前面的元素重复 0 次或 1 次 | c? | 匹配 0 个或 1 个 "c" |
{n} | 前面的元素重复 n 次 | d{2} | 匹配两个 "d" |
{n,} | 前面的元素至少重复 n 次 | e{2,} | 匹配至少两个 "e" |
{n,m} | 前面的元素重复至少 n 次,至多 m 次 | f{1,3} | 匹配 1 到 3 个 "f" |
| ` | ` | 逻辑或 | `cat |
示例代码
#include <iostream>
#include <regex>
#include <string>
using namespace std;
int main() {
string text = "I have 2 cats and 3 dogs.";
// 匹配数字
regex number_regex(R"(\d+)"); // 匹配一个或多个数字
cout << "Numbers in the text: ";
for (sregex_iterator it = sregex_iterator(text.begin(), text.end(), number_regex); it != sregex_iterator(); ++it) {
cout << it->str() << " "; // 输出匹配的数字
}
cout << endl;
// 匹配以 "I" 开头的句子
regex start_with_I(R"(^I.*)");
if (regex_search(text, start_with_I)) {
cout << "Text starts with 'I'." << endl;
} else {
cout << "Text does not start with 'I'." << endl;
}
// 匹配 "cat" 或 "dog"
regex animal_regex(R"(cat|dog)");
cout << "Animals found: ";
for (sregex_iterator it = sregex_iterator(text.begin(), text.end(), animal_regex); it != sregex_iterator(); ++it) {
cout << it->str() << " "; // 输出匹配的动物
}
cout << endl;
return 0;
}
输出结果
Numbers in the text: 2 3
Text starts with 'I'.
Animals found: cat dog
(11) Lambda 表达式
支持匿名函数,简化了函数对象的定义。
所谓匿名函数,简单地理解就是没有名称的函数,又常被称为 lambda 函数或者 lambda 表达式。 (1)定义 lambda 匿名函数很简单,可以套用如下的语法格式:
[外部变量访问方式说明符] (参数) mutable noexcept/throw() -> 返回值类型 { 函数体; };
其中各部分的含义分别为:
a. [外部变量方位方式说明符]
[ ] 方括号用于向编译器表明当前是一个 lambda 表达式,其不能被省略。在方括号内部,可以注明当前 lambda 函数的函数体中可以使用哪些“外部变量”。
所谓外部变量,指的是和当前 lambda 表达式位于同一作用域内的所有局部变量。
b. (参数)
和普通函数的定义一样,lambda 匿名函数也可以接收外部传递的多个参数。和普通函数不同的是,如果不需要传递参数,可以连同 () 小括号一起省略;
c. mutable
此关键字可以省略,如果使用则之前的 () 小括号将不能省略(参数个数可以为 0)。默认情况下,对于以值传递方式引入的外部变量,不允许在 lambda 表达式内部修改它们的值(可以理解为这部分变量都是const 常量)。而如果想修改它们,就必须使用 mutable 关键字。
注意:对于以值传递方式引入的外部变量,lambda 表达式修改的是拷贝的那一份,并不会修改真正的外部变量;
d. noexcept/throw()
可以省略,如果使用,在之前的 () 小括号将不能省略(参数个数可以为 0)。默认情况下,lambda 函数的函数体中可以抛出任何类型的异常。而标注noexcept 关键字,则表示函数体内不会抛出任何异常;使用 throw() 可以指定 lambda 函数内部可以抛出的异常类型。
e. -> 返回值类型
指明lambda 匿名函数的返回值类型。值得一提的是,如果 lambda 函数体内只有一个 return 语 句,或者该函数返回void,则编译器可以自行推断出返回值类型,此情况下可以直接省略"-> 返回值类型"。
f. 函数体
和普通函数一样,lambda 匿名函数包含的内部代码都放置在函数体中。该函数体内除了可以使用指定传递进来的参数之外,还可以使用指定的外部变量以及全局范围内的所有全局变量。
#include <iostream>
#include <algorithm>
using namespace std;
int main() {
int num[4] = {4, 2, 3, 1};
// 对数组中的元素进行排序
sort(num, num + 4, [](int x, int y) -> bool {
return x < y; // 返回 x 是否小于 y
});
// 输出排序后的数组
for (int n : num) {
cout << n << " ";
}
cout << endl;
return 0;
}
输出:1234
更多lambda参考我另外一篇文章https://blog.youkuaiyun.com/qq_50373827/article/details/142382417

















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









