




一、序言
根据官网文档一起学习告警规则:https://prometheus.io/docs/prometheus/latest/configuration/alerting_rules/
告警规则描述: 告警规则通过 PromQL 表达式判断指标是否满足告警条件,当条件触发时,会针对符合触发条件的标签组合发送告警通知。
例如:
- alert: HighCpuUsage
expr: avg(rate(node_cpu_seconds_total{mode!="idle"}[5m])) by (instance, job) > 0.8
for: 2m
labels:
severity: critical
执行表达式可能返回这样的结果:
{instance="server1:9100", job="node-exporter", severity="critical"} 0.85
{instance="server2:9100", job="node-exporter", severity="critical"} 0.92
HighCpuUsage 告警规则可以同时触发多个告警(如多台服务器超标),那么标签组合就可以明确是那台主机在告警。
二、告警规则配置
告警规则和记录规则配置方式相同,记录规则使用参考:https://blog.youkuaiyun.com/qq_50247813/article/details/150487185
告警规则语法如下:
# 警报的名称。必须是有效的标签值。
alert: <string>
# 要评估的 PromQL 表达式。在每次评估周期中,此表达式都会在当前时间点进行评估,并且所有生成的结果时间序列都会成为待命/触发的警报。
expr: <string>
# 触发时间满足多久被视为已出发告警
[ for: <duration> | default = 0s ]
# 当表达式触发告警,变为不触发后,保存告警状态多久时间。
[ keep_firing_for: <duration> | default = 0s ]
# 为每个告警添加或覆盖标签
labels:
[ <labelname>: <tmpl_string> ]
# annotations(注释)用于为告警添加详细的描述信息,这些信息不参与告警的分组、路由等逻辑处理,主要用于向用户展示告警的具体内容、原因、解决方案等可读性信息。
annotations:
[ <labelname>: <tmpl_string> ]
配置实例:
使用记录规则作为表达式:
groups:
# 第一组: 记录规则(计算并存储cpu使用率)
- name: cpu_recording_rules
rules:
- record: instance:node_cpu_seconds:avg_rate5m
expr: 100 - (avg by (instance) (rate(node_cpu_seconds_total{mode="idle"}[5m])) * 100)
labels:
metric_type: derived
# 第二组: 告警规则(引用记录规则)
- name: cpu_alerts
rules:
- alert: HighCpuUsage
expr: instance:node_cpu_seconds:avg_rate5m > 80
for: 2m
labels:
severity: warning
annotations:
summary: "实例 {{ $labels.instance }} CPU使用率过高"
description: "CPU使用率已达 {{ $value | humanize }}%(阈值80%)"
- alert: CriticalCpuUsage
expr: instance:node_cpu_seconds:avg_rate5m > 95
for: 1m
labels:
severity: critical
annotations:
summary: "实例 {{ $labels.instance }} CPU使用率临界"
description: "CPU使用率已达 {{ $value | humanize }}%(阈值95%),系统可能无响应!"
重新在家Prometheus配置:
kill -HUP 6163
查看rules列表:
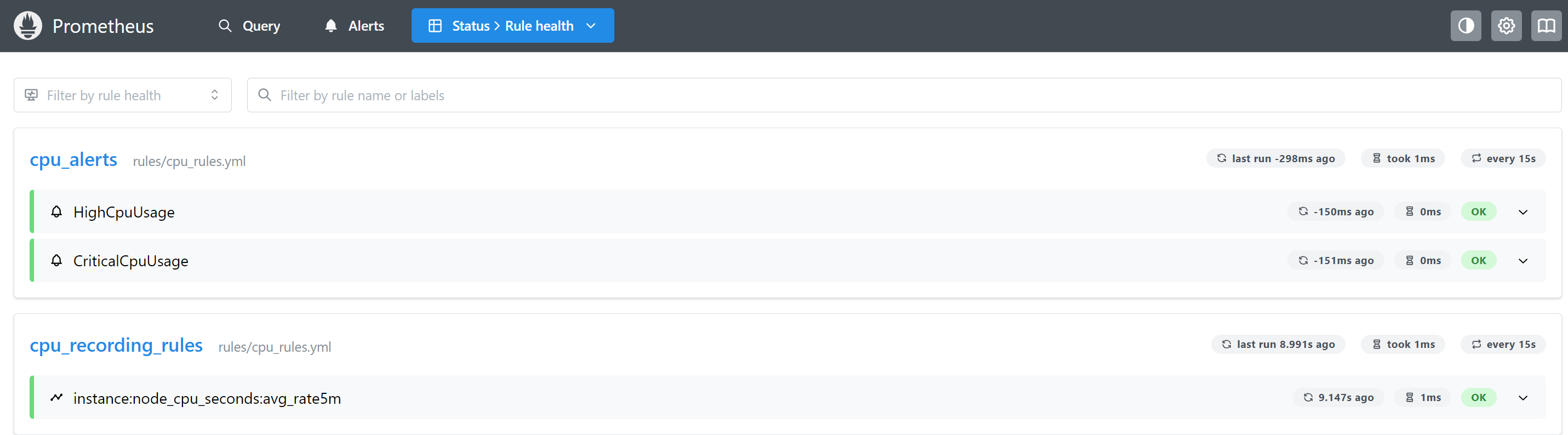
查看告警:

触发告警:
快速将cpu使用率提升上去:
stress的安装使用参考:https://blog.youkuaiyun.com/qq_50247813/article/details/148428133
stress --cpu 2 --timeout 600s
--cpu 2: 指的cpu核心数--timeout 600s: 压测时间
查看告警:
如下图,告警状态由INACTIVE转换成了PENDING

告警状态介绍:
告警状态有3种:
-
INACTIVE(非活跃状态)
含义:表示告警当前没有触发 ,即 Prometheus 通过评估告警规则的表达式,发现当前指标数据未满足告警触发条件。例如,在 CPU 使用率告警规则中,当 CPU 使用率低于设定的阈值(如 80%)时,对应的告警就处于 INACTIVE 状态。 -
PENDING(待处理状态)
含义:当告警规则的表达式开始满足告警条件时,告警会先进入 PENDING 状态。但此时并不会立即发送告警通知,Prometheus 会根据告警规则中设置的 for 时间参数进行判断 。只有当指标数据持续满足告警条件的时长达到 for 所设置的时间,告警才会进入 FIRING 状态。 -
FIRING(触发状态)
含义:表示告警已经触发,即指标数据不仅满足了告警规则设定的条件,而且满足条件的时长也达到了 for 时间的要求。此时,Prometheus 会根据配置,将告警信息发送到对应的告警接收端(如 Alertmanager,然后由 Alertmanager 进一步将告警信息发送到邮件、短信、即时通讯工具等)。
当前告警状态是PENDING,只要满足for: 2m延时就会将状态更改为FIRING如下:

到这里告警规则就学会了,下一篇文章将学习Alertmanager 告警工具,Alertmanager会将告警发送到邮件、短信、即时通讯工具等

















 558
558

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









