







【通用灵巧手抓取】UniDexGrasp++算法学习——基于几何感知的课程迭代式专才-通才学习策略
论文题目:《UniDexGrasp++: Improving Dexterous Grasping Policy Learning via Geometry-aware Curriculum and Iterative Generalist-Specialist Learning》
项目地址:https://pku-epic.github.io/UniDexGrasp++/
论文出处:ICCV 2023 (best paper)、王鹤老师团队
背景
UniDexGrasp第一次提出了一种基于视觉的通用灵巧手抓握策略,只需要将点云观测和机器人的本体信息作为输入,模型就可以预测抓握策略。算法的核心在于利用object课程学习策略来简化学习过程,先学习单个物体的抓握,之后逐步过渡到多种物体的抓握,同时利用教师(state-base)— 学生(vision-base)蒸馏学习的策略来训练模型的参数,加速vision-base策略的收敛速度。虽然它可以在一定程度上实现通用的抓握效果,但是这种算法有两个弊端:
- 学生模型的性能很大程度上依赖于教师模型的性能,因为算法核心是将教师模型的决策能力蒸馏给学生模型,学生模型不能自己学习,不能实现自我性能的提升,限制了学生模型性能的进一步提高;
- 对象课程学习依赖于利用物体的标签对任务空间做划分,忽略了人类在判断物体是否相似时的一个重要属性——物体的几何信息;
主要思想
对此,本文改进了UniDexGrasp,提出了UniDexGrasp++算法,显著提高了算法的抓握精度。首先,本文改进了原始的对象课程学习策略(object curriculum learning),提出了基于几何感知的任务课程学习(Geometry-aware Task Curriculum Learning, GeoCurriculum),提升了基于状态的教师策略的性能,这一方法根据场景点云的几何特征来测量任务的相似性,比之前只根据物体的类别来判断相似性更为合理。其次,为了提升算法的通用性,本文引入了通才-专才学习(generalist-specialist learning)理念,将原始任务空间按抓握任务的相似度做划分,划分出多个子集,在子集上训练专才模型,专才模型在子集上训练,可以很好地提升策略在当前子任务下的应用性能,之后再将多个专才的能力蒸馏到同一个通才模型中,提升通才的泛化能力,这一过程迭代进行,称为基于几何感知迭代的通才-专才学习策略(Geometry-aware iterative Generalist-Specialist Learning, GiGSL),这一过程可以以一个自监督的方式提升策略本身的性能,直到达到性能饱和。GiGSL可以单独用于提升学生模型的泛化能力,而不需要受教师模型的监督,也就是可以摆脱教师模型的依赖,逐步提升自己的抓握能力。
专才和通才分别表示:专门解决某类任务的专用模型和可以解决所有任务的通用模型。
这篇文章的核心思想其实是对原始复杂的任务做拆解,抓握任务跟物体的几何特征息息相关,几何特征相似的物体,抓握策略也可以非常相似,因此我们可以根据物体的几何特性来对原始的抓握任务做划分,将几何特性相似抓握任务的划分到同一子任务集合下面。策略可以独立地在每个子任务集合中学习到较好的专用抓握模型(专才),之后将这一策略视为伪标签,来训练通用的抓握模型模型(通才),这也是蒸馏算法的一个核心思想。
方法
方法总览
按照之前的研究思路,作者在这里将策略学习分为两个阶段:①基于状态(state-based)的策略学习阶段;②基于视觉(vision-based)的策略学习阶段。直接学习基于视觉的抓握策略非常有挑战,作者首先学习可以访问Oracle信息的基于状态的抓握策略,并让该策略辅助基于视觉策略的学习。
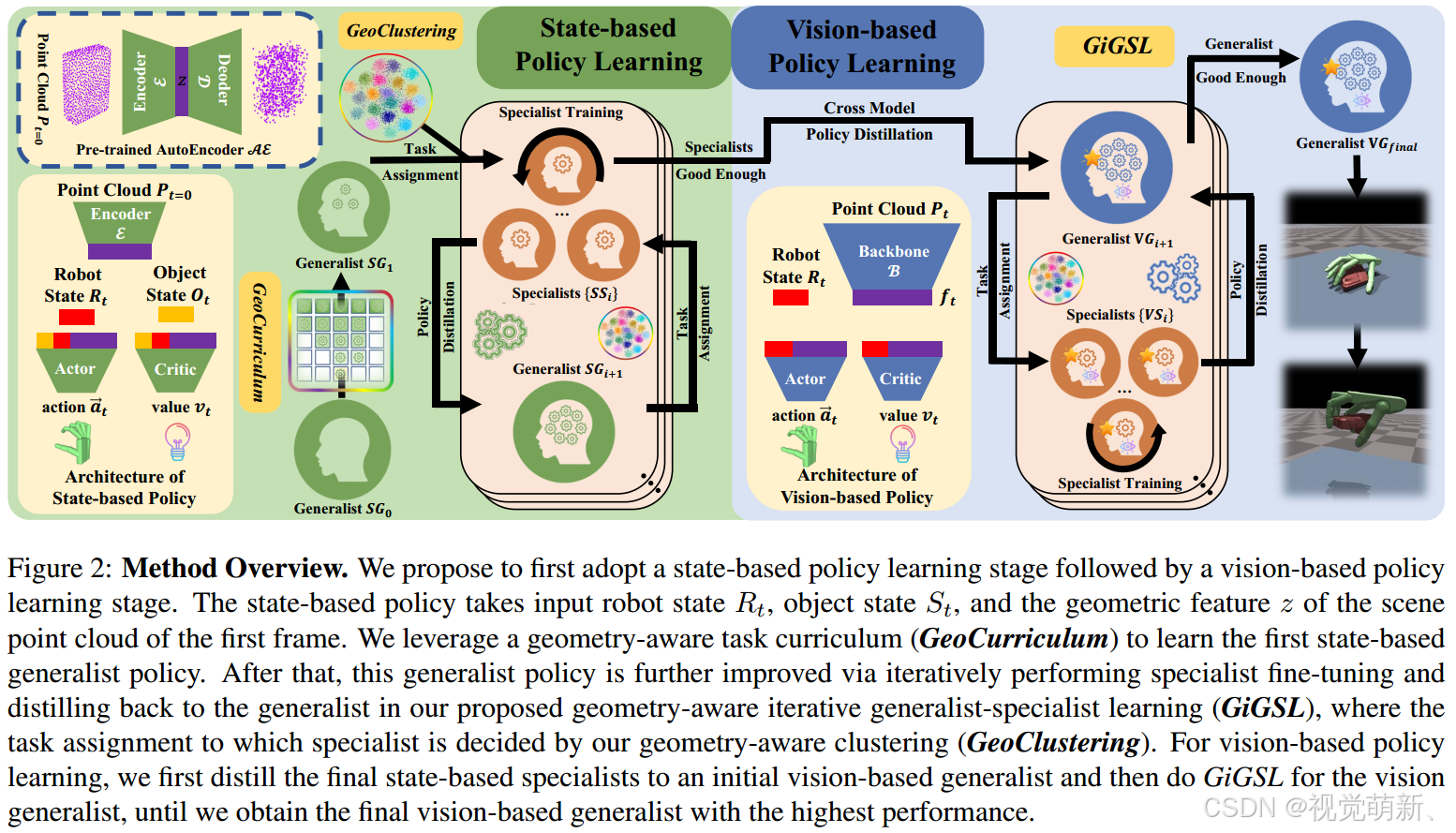
基于状态的策略学习(state-based)
此阶段的目标是获得一个通用抓握策略,或者我们称之为 “通才”,该策略 以机器人本体状态 R t R_t Rt、对象状态 O t O_t Ot和第一帧的场景点云 P t = 0 P_{t=0} Pt=0作为输入,对象点云由多个视角的深度相机捕获的多个深度点云图融合而成。在每一步 t t t决策时,我们都将第一帧的点云数据 P t = 0 P_{t=0} Pt=0传入模型,用于提供物体的几何信息,并且使用预训练的点云自动编码器来提取点云的几何特征。注意在这一阶段,点云编码器被冻结住,不会干扰策略学习,将 P t P_t Pt的处理留给基于视觉的策略模型。
虽然基于状态的策略模型比基于视觉的策略模型更容易收敛,但在如此多样化的多任务设置下,想要实现高成功率仍然非常具有挑战性,因此,本算法还提出了一种基于几何感知的课程学习策略(geometry-aware curriculum learning, GeoCurriculum)来简化多任务RL的学习过程,并提高成功率。
经过GeoCurriculum之后,我们获得了第一个基于状态的通才(generalist) S G 1 SG_1 SG1,他可以处理所有任务,然后我们提出了一种基于几何感知的迭代式通才-专才学习策略(geometry-aware iterative Generalist-Specialist Learninng strategy),简称为GiGSL,以进一步提高通才的性能。这一过程为 “在学习几个专门从事特定任务范围的基于状态的专才 { S S i } \{SS_i\} { SSi}” 和 “将专才提炼为通才 S G i + 1 SG_{i+1} SGi+1” 之间的迭代,其中 i i i表示迭代的次数索引。通过这种迭代学习,模型的整体性能不断提高,直到接近饱和。
基于视觉的策略学习(vision-based)
对于基于视觉的策略模型,我们只允许它访问现实世界中可用的信息,包括机器人当前时刻的状态信息 R t R_t Rt和场景的点云数据 P t P_t Pt。在这一阶段,我们利用最终的策略损失共同学习 决策网络 和 视觉backbone B \mathcal B B(图2中的蓝色部分),实施阶段采用PointNet+Transformer来组成 B \mathcal B B,共同提取点云特征。在训练过程中,我们随机初始化第一个视觉通才 V G 1 VG_1 VG1的网络权重,之后首先执行跨模态蒸馏,将最新的基于状态的策略专才 { S S n } \{SS_n\} { SSn}蒸馏到 V G 1 VG_1 VG1中,然后,我们可以启动基于视觉的策略模型的GIGSL的循环,在微调 { V S i } \{VS_i\} { VSi}和提炼到 V G i + 1 VG_{i+1} VGi+1之间进行迭代,直到基于视觉的通才性能达到饱和。最终的基于视觉的通才 V G f i n a l VG_{final} VGfinal是我们学习到的通用抓取策略,可以产生最高的性能。
伪代码流程如下

iGSL:迭代的通才—专才学习
通才-专才学习策略(GSL)回顾
通才-专才的学习策略来源于ICML22的一篇论文GSL,这种方法将整个任务空间分成多个子空间,并让一位专才(specialist)负责一个子空间。由于每个子空间的任务变化较少,因此更容易学习,每位专才都可以得到良好的训练,并且在其任务分布上表现出较好的性能。最后,将所有的专才蒸馏为一个通才,适用于整个任务空间。
注意,在文章GSL中,只有一个 专家学习和通才学习 的循环,并且蒸馏是使用GAIL或者DAPG算法实现,作者发现这种方法性能一般,在本文中使用一种基于DAgger的蒸馏策略,以迭代的方式实现通才-专才的学习。
基于Dagger的策略蒸馏算法
DAgger是一种基于策略的模仿学习算法(Dataset Aggregation),需要专家策略(称为老师)和负责与环境交互的学生策略参与训练。当学生采取行动时,专家策略也同样基于学生的输入状态来得到一组动作,用于改进学生模型的预测,也就是将教师模型的预测结果蒸馏到学生模型上。这种模仿是基于策略的,因此不会受到行为克隆算法中常见的协变量转移问题(covariate shift)的影响。
然而,DAgger算法的一个缺点在于它只关心策略网络,忽略了RL中常用的价值网络(value network),例如AC算法中的评论家算法(critic),因此不能直接用于以AC算法为框架的模型学习中。对此,本算法提出了一种新的基于DAgger的蒸馏方法,它在监督策略蒸馏的过程中同时学习策略函数和评论家函数,其中策略函数的损失为教师策略模型 π t e a c h e r \pi_{teacher} πteacher输出和学生策略模型 π θ \pi_\theta πθ输出之间的MSE损失(与DAgger相同),评价函数的损失为价值函数 V ϕ V_{\phi}
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章




















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











