







Java String类深入了解JDK各个版本进阶版本
一,底层类型
在jdk11中 String value 存储字符串值 是byte[] 数组 ,String中存储字节码的是coder 也是byte类型,因此String的底层数据存储类型成为了byte类型
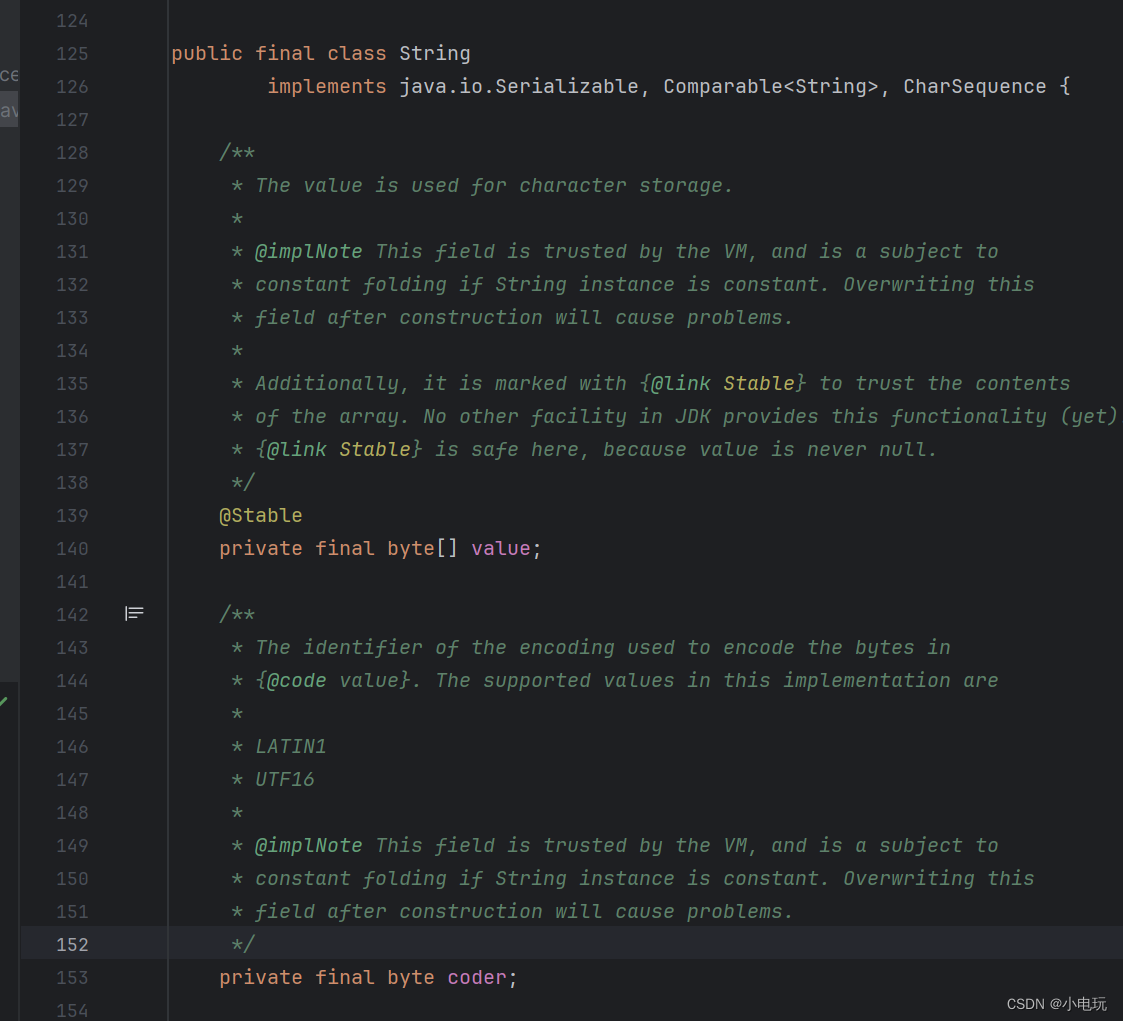
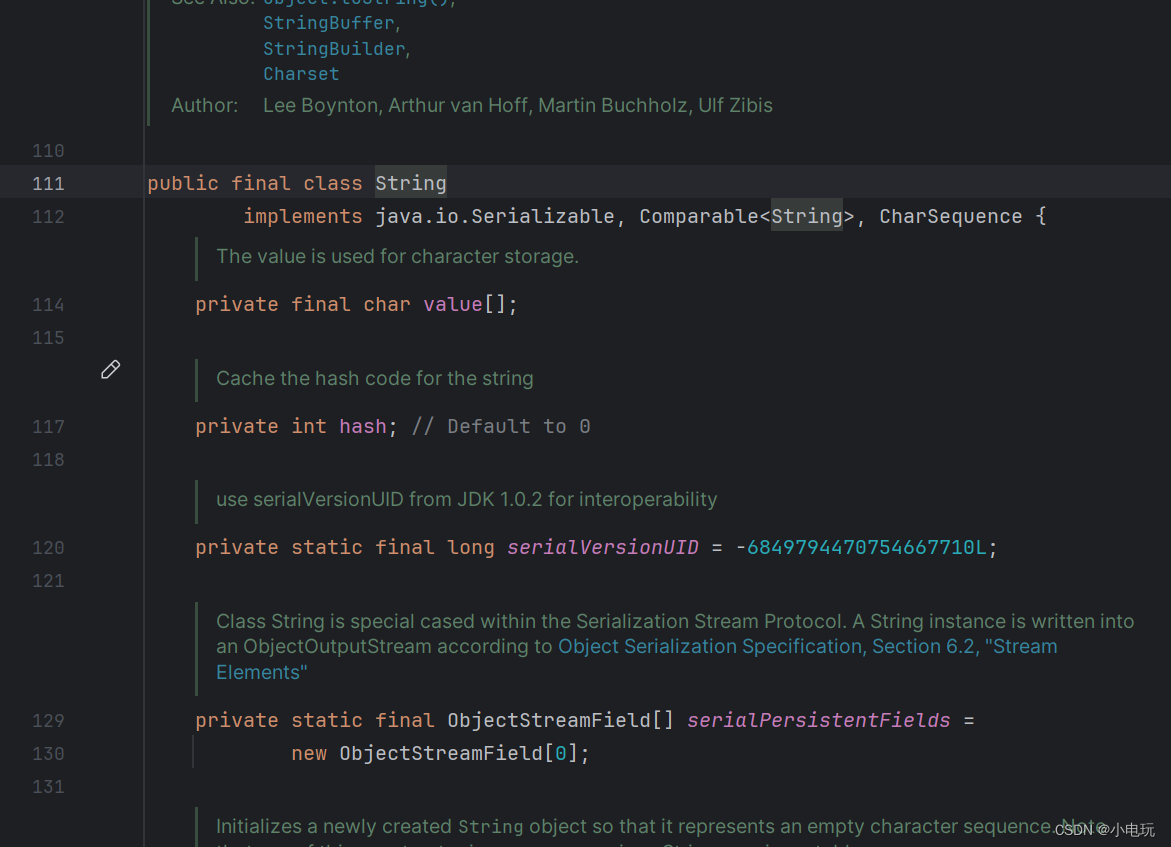
而在jdk8中String 的String value 存储字符串值 是char[] 数组,因此 因此可以看出在jdk8中String底层数据存储类型成为了char类型
二,"coder"属性
JDK 8中的String类没有"coder"属性,而JDK 11中的String类引入了"coder"属性。这是因为在JDK 8及之前的版本中,Java字符串内部使用的是UTF-16编码,每个字符占用两个字节。在JDK 8中,String类仅保存了一个字符数组(char[])来存储字符串的内容。
而在JDK 9及之后的版本中,Java引入了Compact Strings(紧凑字符串)的概念,以节省内存空间。在这种情况下,String类的实现采用了一种称为Latin-1的编码方式,即对于只包含拉丁字符(Unicode码点小于等于255)的字符串,只需要一个字节来存储每个字符。这样做可以显著减少内存消耗。
为了支持这种新的编码方式,JDK 11中的String类引入了"coder"属性,用于标识字符串使用的编码类型。在JDK 11中,String类内部的字符数组(byte[])只存储Latin-1编码的字符,而针对非拉丁字符的部分,会通过调用StringCoding类的方法进行转码和处理,转码之后依然是byte[]数组
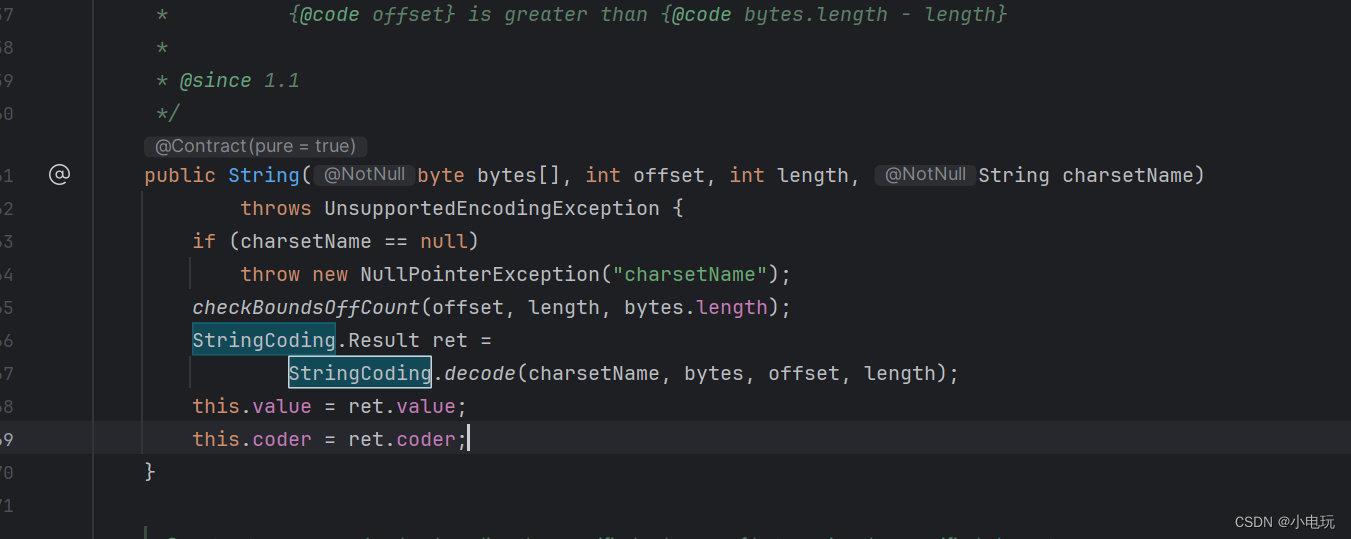
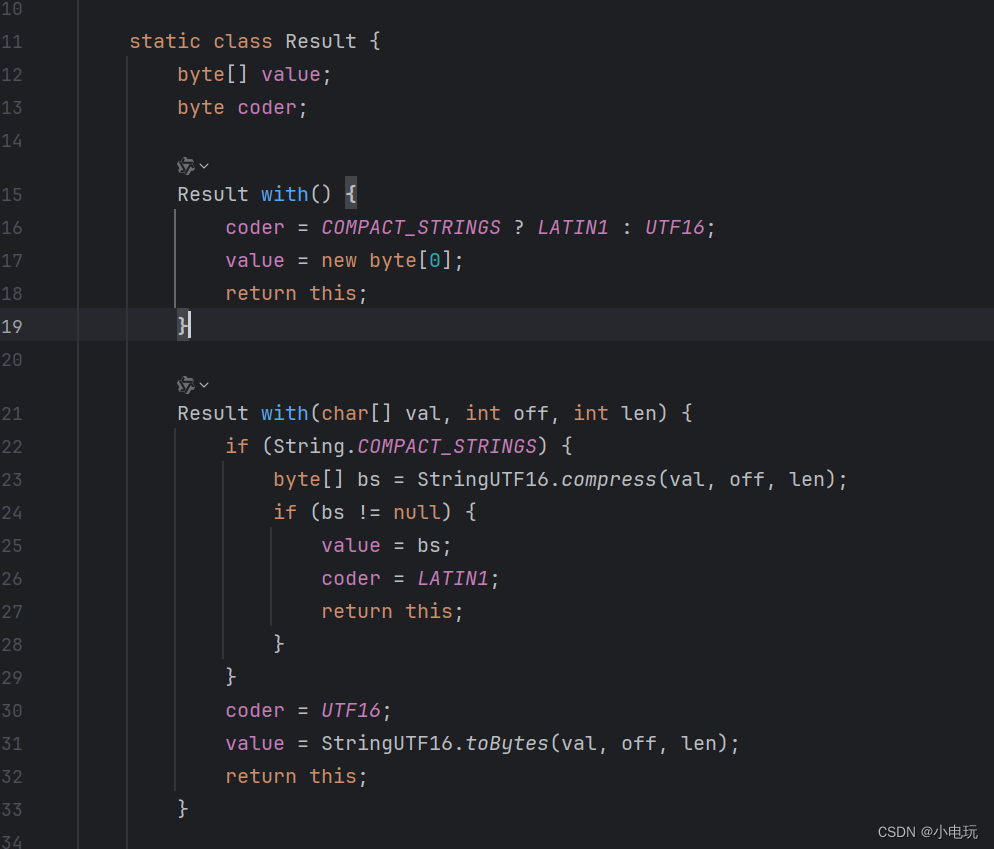
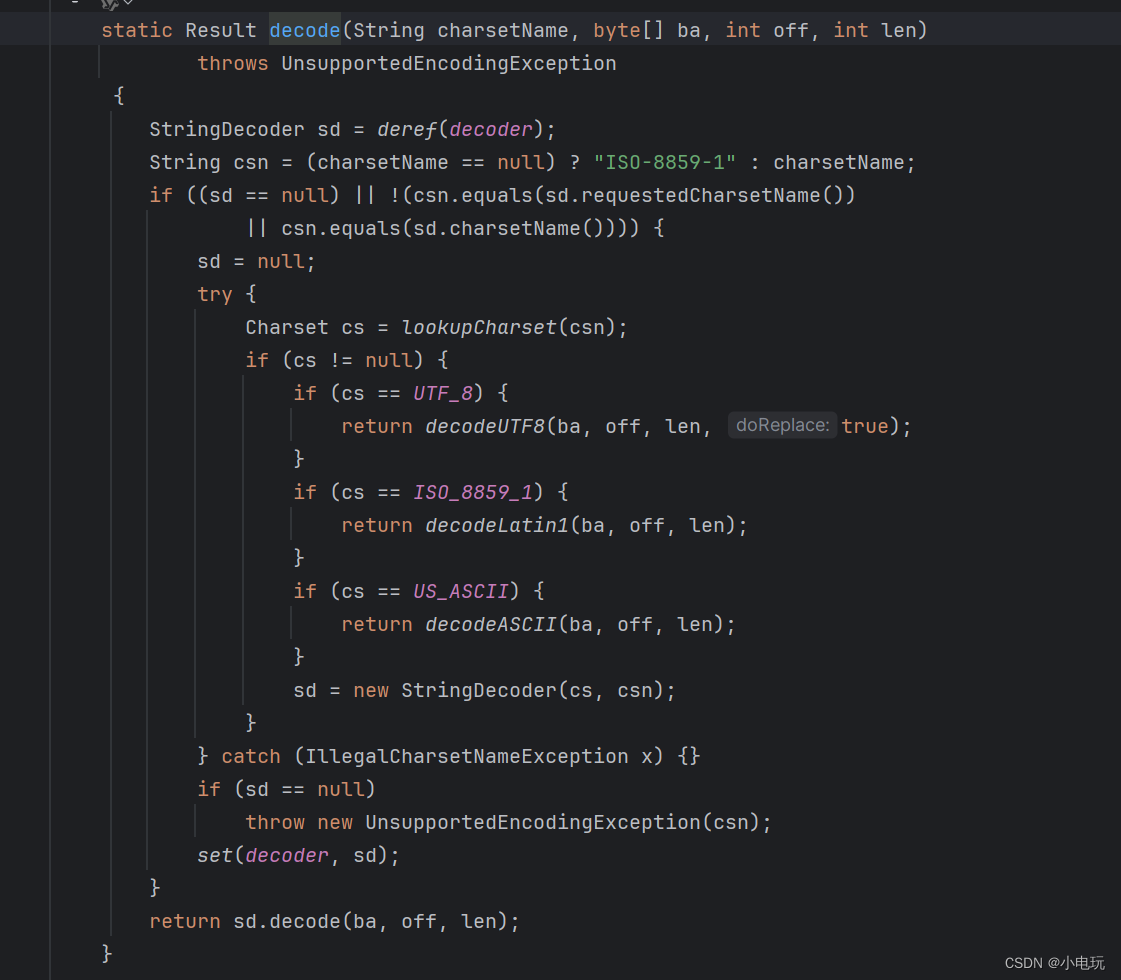
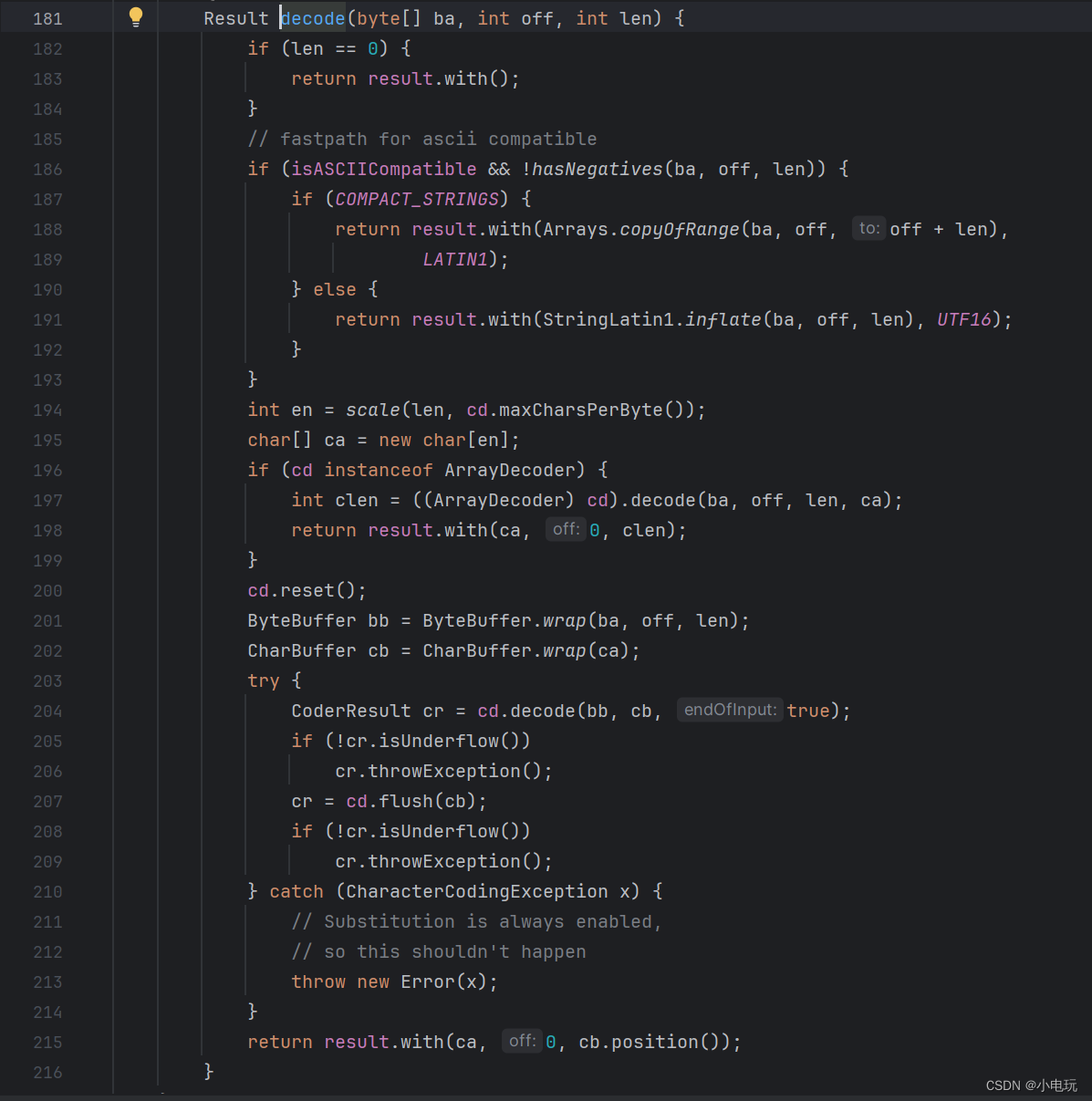
可以说JDK 11中的String类引入了"coder"属性是为了支持紧凑字符串的优化,以提高性能和节省内存空间。
jdk选择更换String的底层存储类型的原因是为了降低资源的浪费,char存储是两个字节,而byte存储为1个字节
三,hash 字段
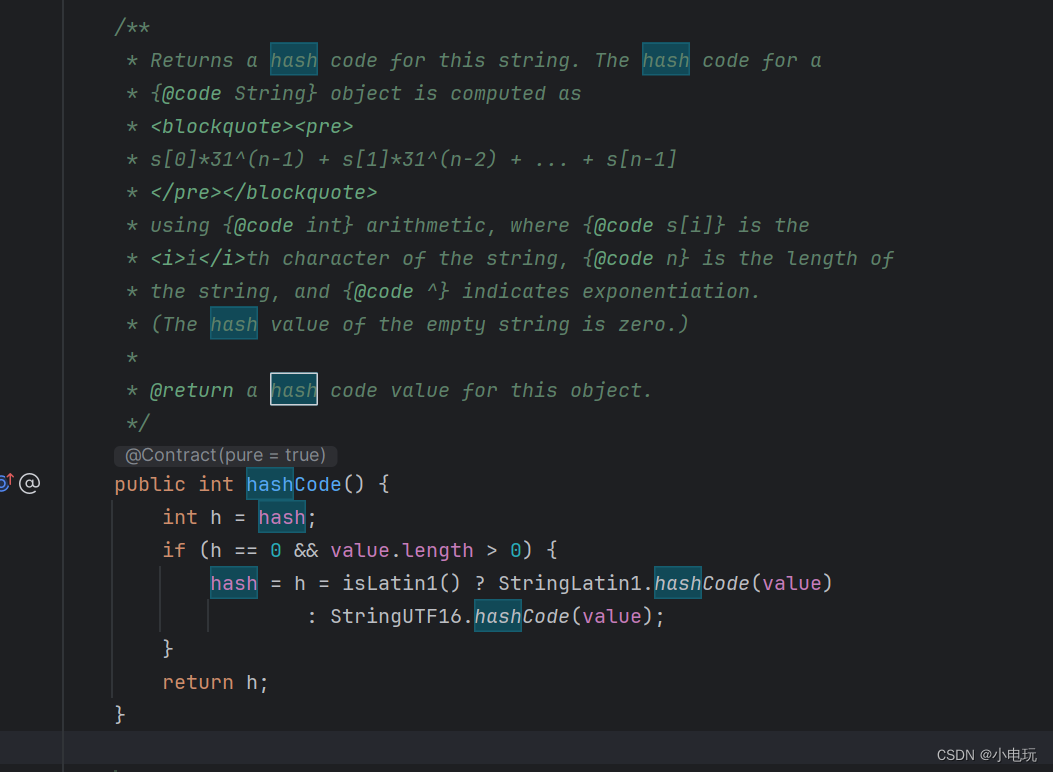
String 内部包含了一个 private 修饰的int 类型的hash 字段 用于缓存字符串的哈希代码 当第一次调用String a 的时候 a会调用HashCode 进行计算哈希码,当下次再次调用a的时候会直接调用hash而不会再调用hashCode 原因是当第一次调用HashCode的时候HashCode 计算哈希码并赋值给hash。如果a的值不发生改变以后的每次调用a都是从hash里面进行获取哈希码进行获取存储的值
四,hashIsZero 字段
在 JDK 17 中,String 类新增了一个名为 hashIsZero 的私有字段,用于表示字符串的哈希码是否为零。这个字段主要用于优化字符串哈希码的计算和存储。
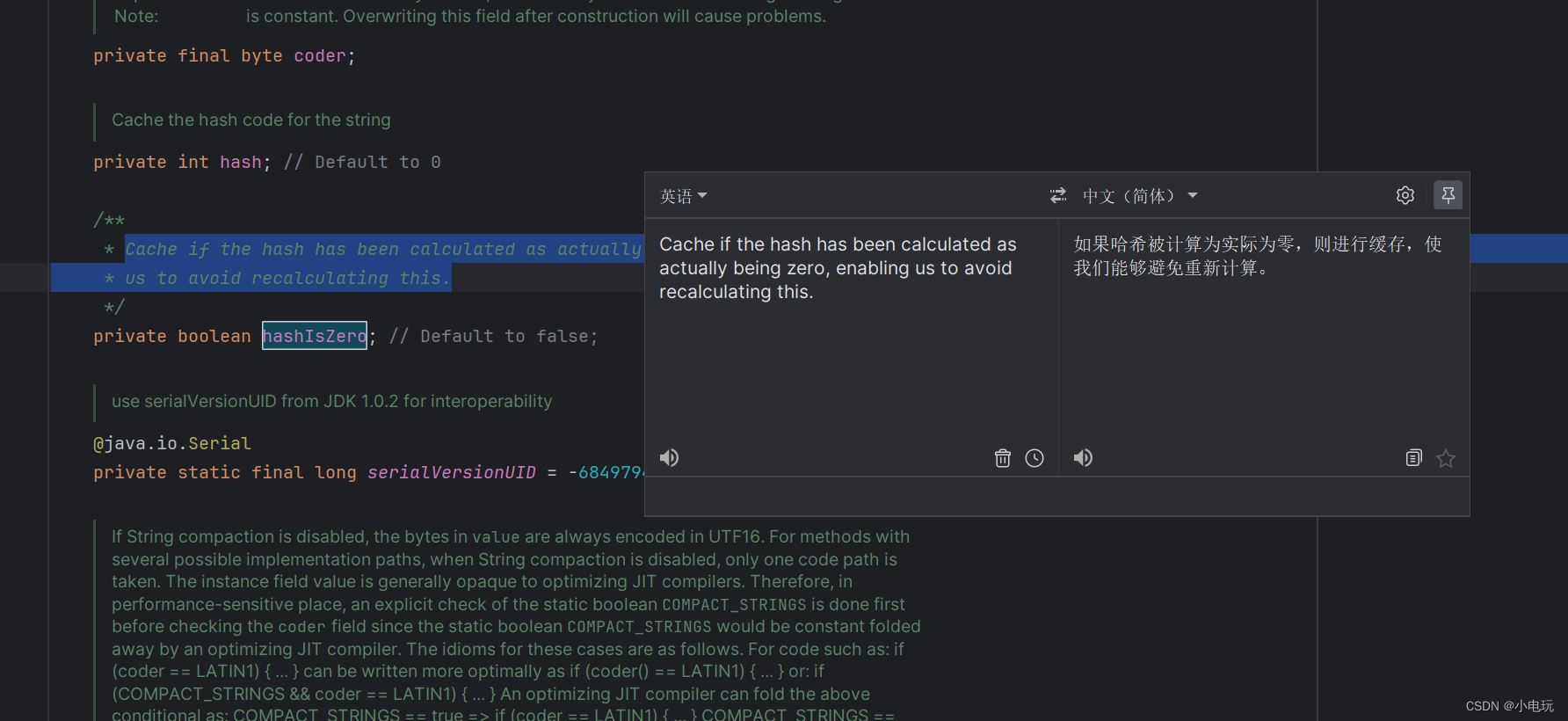
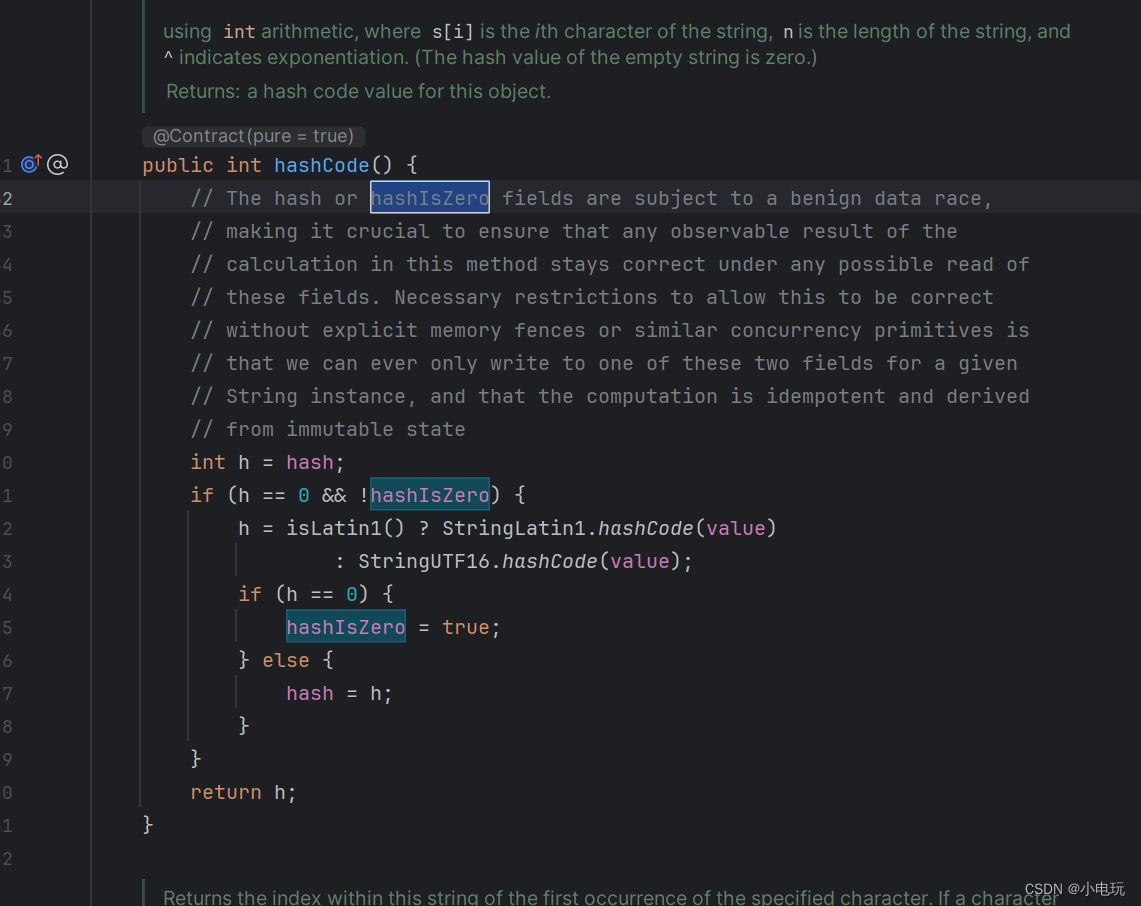
在 JDK 17 中,String 类的哈希码计算方式发生了改变。之前的版本中,String 类的哈希码是延迟计算的,即在第一次调用 hashCode 方法时才会计算并缓存哈希码。而在 JDK 17 中,哈希码将在字符串被创建时立即计算,并存储在 hash 字段中。同时,新增的 hashIsZero 字段用于标记哈希码是否为零,以便快速判断字符串的哈希码状态。
这种优化可以提高字符串哈希码的计算和比较性能,并且在某些场景下可以避免不必要的哈希码计算。因此,hashIsZero 字段在新版 JDK 中是为了提升字符串处理的性能而引入的。


















 329
329

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











