







HDFS分布式文件系统
概述
HDFS是hadoop核心组成,是一种分布式存储服务;选择分布式的原因是分布式文件系统横跨2多台计算机,在大数据时代有着广泛的应用前景,它们为存储和处理超大规模数据提供所需的扩展能力;
而且,HDFS通过统一的命名空间目录树来定位文件;另外,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色(分布式本质是拆分,各司其职)。
在讲解架构之前先要了解一些重要的概念
(1)Master/Slave架构:hdfs集群往往是一个namenode(HA架构是两个) (主节点)+ 多个datanode(从节点)组成;
-
(2)分块存储:hdfs中的文件在物理上是分块(block)存储,块的大小通过配置参数规定;
-
(3)命名空间(name space):文件系统名字空间的层次结构和大多数现有的文件系统类似,用户可以创建、删除、移动或重命名文件;
-
(4)NameNode元数据管理:目录结构及文件分块位置信息叫做元数据,它记录每一个文件所对应的block信息,包括block的id,所在datanode节点的信息;
-
(5)DataNode数据存储:文件的各个block的具体存储管理由datanode节点承担,一个block会有多个datanode来存储,datanode会定时向namenode来汇报自己持有的block信息;
-
(6)副本机制:为了容错,文件的所有block都会与哦副本,每个文件的block大小和副本系数都是可配置的,应用程序可以指定某个文件的副本数目。副本系数可以在文件创建时指定,也可之后改变,副本数量默认3个;
-
(7)一次写入,多次读出:hdfs是设计成适应一次写入,多次读出的场景,且不支持文件的随机修改,也就是支持追加写入,不支持随机更新;所以hdfs适合用来做大数据分析的底层存储服务,并不适合用来做网盘等应用,因为修改不方便,延迟大,网络开销大,成本太高。
架构图示:
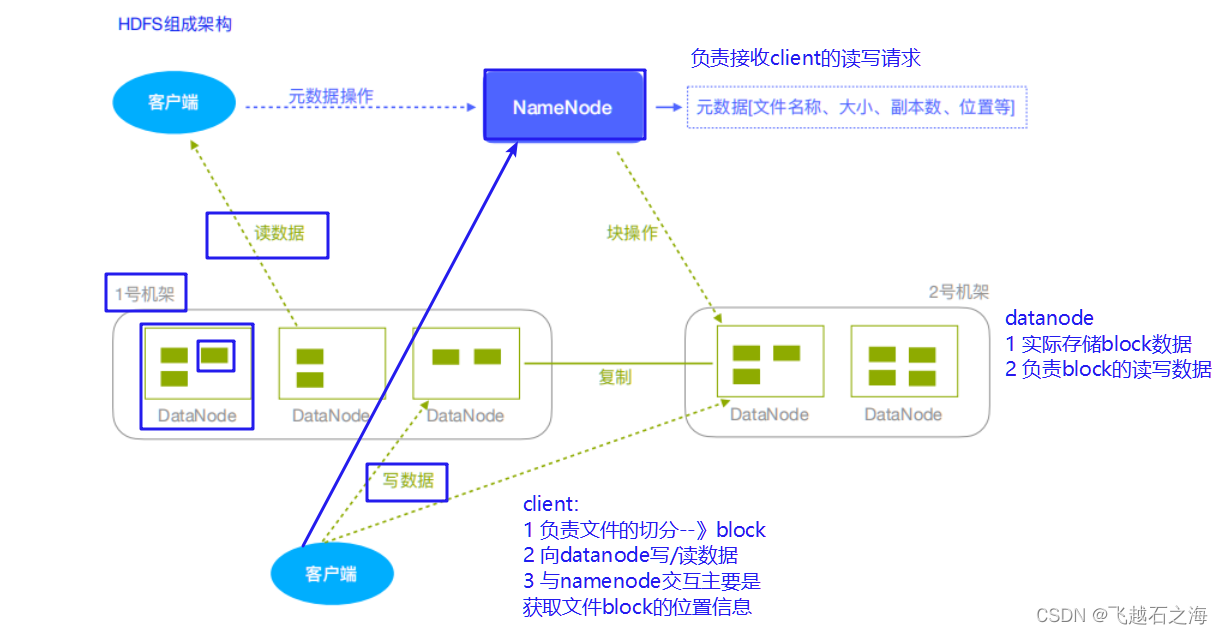
NameNode(nn):Hdfs集群的管理者,Master
维护管理Hdfs的名称空间(NameSpace)
维护副本策略
记录文件块(Block)的映射信息
负责处理客户端读写请求
DataNode:NameNode下达命令,DataNode执行实际操作,Slave节点
保存实际的数据块
负责数据块的读写
Client:客户端
上传文件到HDFS的时候,Client负责将文件切分成Block,然后进行上传
请求NameNode交互,获取文件的位置信息
读取或写入文件,与DataNode交互
Client可以使用一些命令来管理HDFS或者访问HDFS
客户端操作
方式分为两种,一种是shell,另一种通过java API的方式。
Shell命令行操作HDFS
启动虚拟机并进行挂载,在shell上进行远程操作。
基本语法如下所示
bin/hadoop fs 具体命令bin/hdfs dfs 具体命令
这里简单举例几种常用的shell命令
-
-mkdir:在HDFS上创建目录
[root@linux121 hadoop-2.9.2]$ hadoop fs -mkdir -p /lagou/bigdata -
-moveFromLocal:从本地剪切粘贴到HDFS
[root@linux121 hadoop-2.9.2]$ touch hadoop.txt
[root@linux121 hadoop-2.9.2]$ hadoop fs -moveFromLocal ./hadoop.txt
/lagou/bigdata -
-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径中
[root@linux121 hadoop-2.9.2]$ hadoop fs -copyFromLocal README.txt /
Java API操作HDFS
先做Java 客户端环境准备,将Hadoop-2.9.2安装包解压到非中文路径(例如:E:\hadoop-2.9.2),之后在计算机环境变量配置HADOOP_HOME环境变量和Path环境变量,创建一个Maven工程,再导入相应的依赖坐标和日志配置文件。
以下是用到的一些依赖,可以在maven官网查询并粘贴相关依赖
<artifactId>junit</artifactId>
<artifactId>log4j-core</artifactId>
<artifactId>hadoop-common</artifactId>
<artifactId>hadoop-client</artifactId>
<artifactId>hadoop-hdfs</artifactId>
为了便于控制程序运行打印的日志数量,需要在项目的src/main/resources目录下,新建一个文件,命名为“log4j.properties”,文件内容自行查找。
最后创建HdfsClient类,具体代码如下:
public class HdfsClient{
@Test
public void testMkdirs() throws IOException, InterruptedException,
URISyntaxException {
// 1 获取文件系统
Configuration configuration = new Configuration();
// 配置在集群上运行
// configuration.set("fs.defaultFS", "hdfs://linux121:9000");
// FileSystem fs = FileSystem.get(configuration);
FileSystem fs = FileSystem.get(new URI("hdfs://linux121:9000"),
configuration, "root");
// 2 创建目录
fs.mkdirs(new Path("/test"));
// 3 关闭资源
fs.close();
}
}
问题:如果不指定操作HDFS集群的用户信息,默认是获取当前操作系统的用户信息,出现权限被拒绝的问题,报错如下图示
解决方案
- 指定用户信息获取FileSystem对象
- 关闭HDFS集群权限校验
打开相关文件 vim hdfs-site.xm
添加如下属性,修改后分发到其他节点,同时重启HDFS集群
<property>
<name>dfs.permissions</name>
<value>true</value>
</property>
- 基于HDFS权限本身比较鸡肋的特点,彻底放弃HDFS权限校验,若生产环境中可考虑借助kerberos以及sentry等安全框架来管理大数据集群安全。所以直接修改HDFS的根目录权限为777
hadoop fd -chmod -R 777 /


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









