






论文:Exploring Lightweight Hierarchical Vision Transformers for Efficient Visual Tracking
这篇文章在AGX上tiny模型可以达到80fps,我来看看怎么个事。
模型如图:
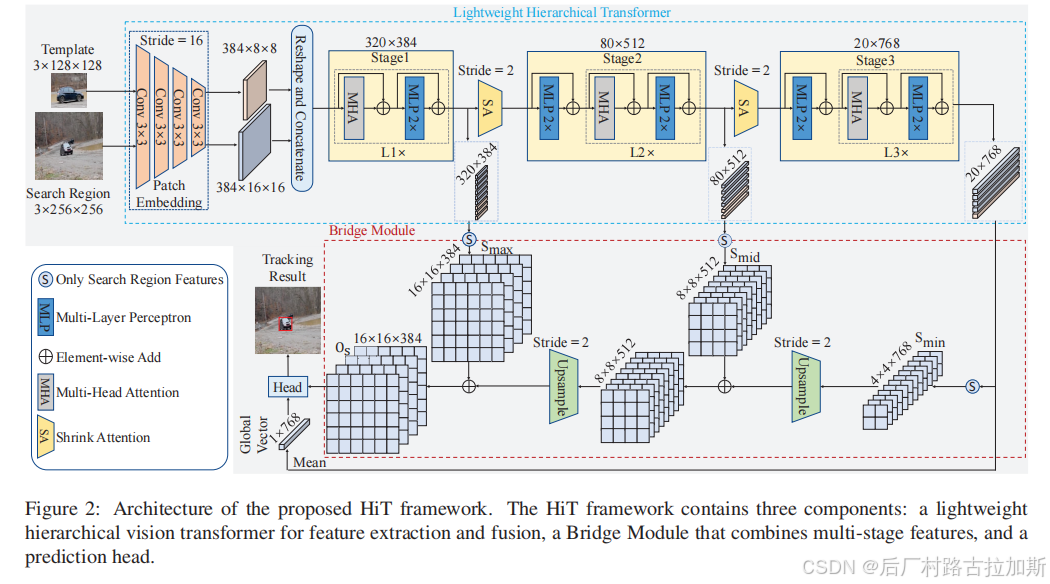
先看lib/models/Hit/backbone.py,发现这里就是引用封装一下,真正的backbone不在这,在pvt.py或者levit.py中。我们直接去看
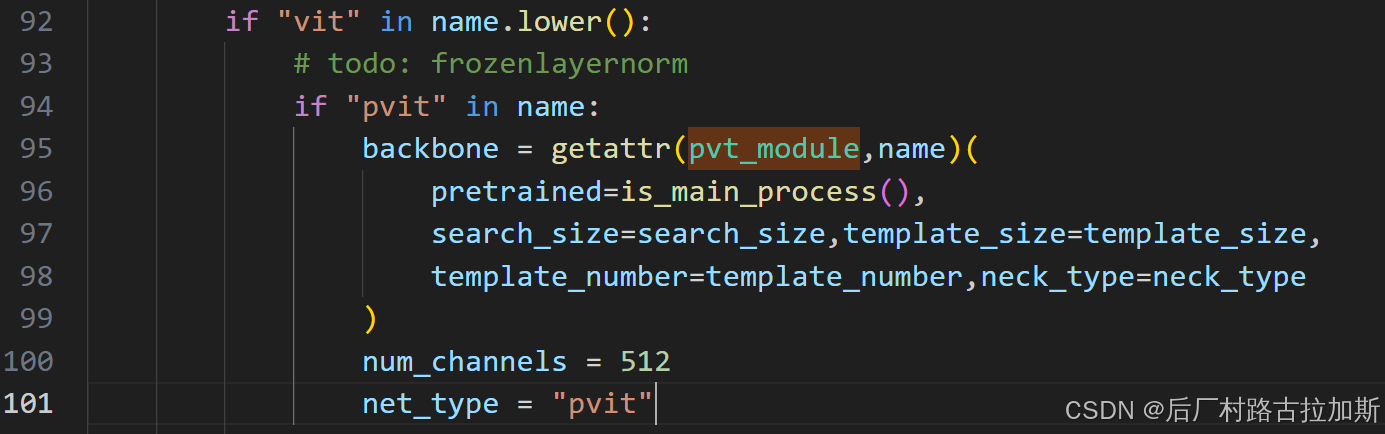
以pvit_small为例:
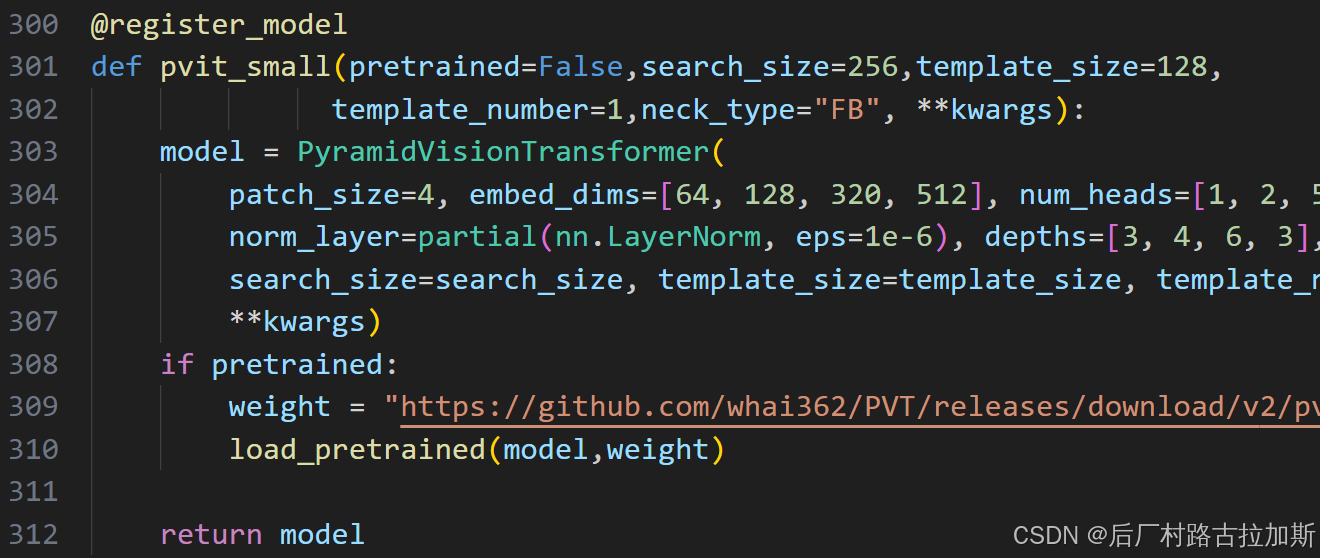
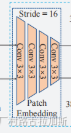
这里面写着是4个3*3卷积,实际上呢?在pvt.py的125行,patch_size=16
class PatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, search_size=256, template_size=128,patch_size=16, in_chans=3, embed_dim=768):
super().__init__()
search_size = to_2tuple(search_size)
template_size = to_2tuple(template_size)
patch_size = to_2tuple(patch_size)
self.search_size = search_size
self.template_size = template_size
self.patch_size = patch_size
# assert img_size[0] % patch_size[0] == 0 and img_size[1] % patch_size[1] == 0, \
# f"img_size {img_size} should be divided by patch_size {patch_size}."
self.search_H, self.search_W = search_size[0] // patch_size[0], search_size[1] // patch_size[1]
self.template_H,self.template_W = template_size[0] // patch_size[0], template_size[1] // patch_size[1]
self.num_search_patches = self.search_H * self.search_W
self.num_template_patches = self.template_H * self.template_W
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)
self.norm = nn.LayerNorm(embed_dim)
def forward(self, iamge_list):
for i in range(len(iamge_list)):
x = iamge_list[i]
B, C, H, W = x.shape
x = self.proj(x).flatten(2).transpose(1, 2)
x = self.norm(x)
if i == 0:
search_H, search_W = H // self.patch_size[0], W // self.patch_size[1]
xz = x
else:
template_H, template_W = H // self.patch_size[0], W // self.patch_size[1]
xz = torch.cat((xz,x),dim=1)
return xz, (search_H, search_W,template_H,template_W)
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=patch_size)这一句话就是前面的四层卷积。
forward里面进行了reshape和connection。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









