






开散列(哈希桶):将发生哈希冲突的元素以链表的方式串联起来,本质上是衣服一个链表的集合。
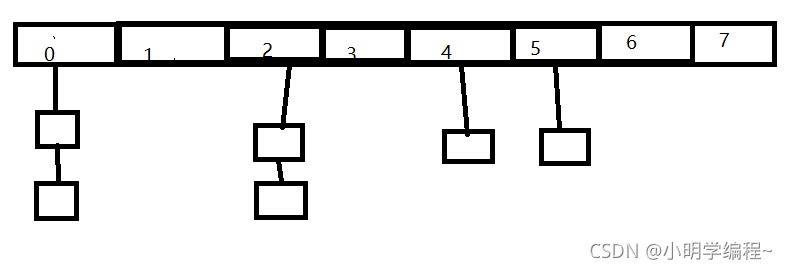
哈希桶的大概结构如上图,可以理解为一个数组中每一个位置存储的是一个链表。
下面大概介绍哈希桶的大概实现:
首先定义存储的节点,此节点跟链表的节点雷同,next存储下一个节点的位置,data存储值域:
template<class T>
struct hashBucketNode {
hashBucketNode(const T& x=T())
:next(nullptr)
,data(x)
{}
hashBucketNode<T>* next;
T data;
};
除留余数法实现:
size_t hashFunc(const T& x) {
return(x % _table.capacity());
}
本文的哈希桶采用除留余数法,模上数组的容量得到桶号(存储位置),然后使用头插法插入到对应的链表中,但是如果存储字符串的话使用除留余数法会出问题,因此本文给出字符串转化成整数数据的方式如下:
template<class T>
class DToInt {
public:
size_t operator()(const T& data) {
return data;
}
};
class Str2Int {
size_t operator()(const string& s) {
return BKDRHash(s.c_str());
}
size_t BKDRHash(const char* str) {
size_t seed = 131;
size_t hash = 0;
while (*str) {
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
};
接下来实现对哈希桶的插入以及删除,本文给出重复元素的插入和删除和不重复元素的插入和删除方法,只不过在重复元素的插入和删除的方法中增加遍历确认元素是否重复:
bool Insert_unique(const T& data) {//插入唯一元素
//通过哈希函数计算哈希桶号
D2I Dtoint;
size_t bucketNo= hashFunc(Dtoint(data));
//查看元素是否重复
Node* cur = _table[bucketNo];
while (cur) {
if (Dtoint(data) == Dtoint(cur->data)) {
return false;
}
cur = cur->next;
}
//插入元素
Node* newnode = new Node(Dtoint(data));
newnode->next = _table[bucketNo];
_table[bucketNo] = newnode;
//修改元素个数
_size++;
}
bool Insert_Repttitiom(const T& data) {
//插入重复元素
//通过哈希函数计算哈希桶号
D2I Dtoint;
size_t bucketNo = hashFunc(Dtoint(data));
//直接插入元素
Node* newnode = new Node(Dtoint(data));
newnode->next = _table[bucketNo];
_table[bucketNo] = newnode;
//修改元素个数
_size++;
return true;
}
bool Erase_unique(const T& data) {
//删除元素
//通过哈希函数计算哈希桶号
size_t bucketNo = hashFunc(data);
//查找元素
Node* prev = nullptr;
Node* cur = _table[bucketNo];
while (cur) {
if (cur->data == data) {
if (prev == nullptr) {
_table[bucketNo] = cur->next;
delete cur;
cur = nullptr;
_size--;
return true;
}
else {
prev->next = cur->next;
delete cur;
_size--;
return true;
}
}
else
{
prev = cur;
cur = cur->next;
}
}
return false;
}
void Erase_Repttitiom(const T& data) {
//删除与data相等的所有元素
//通过哈希函数计算哈希桶号
size_t bucketNo = hashFunc(data);
Node* cur = _table[bucketNo];
Node* prev = nullptr;
while (cur) {
if (cur->data == data) {
if (prev == nullptr) {
_table[bucketNo] = cur->next;
delete cur;
cur = _table[bucketNo];
_size--;
}
else {
prev->next = cur->next;
delete cur;
_size--;
cur = prev;
}
}
else {
prev = cur;
cur = cur->next;
}
}
}
接下来介绍打印和回收方法(析构),这两种方法都需要遍历所有节点:
void Print() {
for (int i = 0; i < _table.size(); i++) {
Node* cur = _table[i];
while (cur) {
cout << cur->data << " ";
cur = cur->next;
}
cout << "\n";
}
}
void Clear() {
for (int i = 0; i < _table.size(); i++) {
Node* cur = nullptr;
while (cur) {
Node* cur = _table[i]->next;
_table[i] = cur->next;
delete cur;
}
}
_size = 0;
}
哈希桶的迭代器,哈希桶的迭代器实现过程中不止对每一条链表进行移动还要对哈希表格进行移动,因此要将迭代器类声明为哈希桶类的友元类,:
template<class T,class D2I= DToInt<T>>
class hashBucket;//后面实现过程中要用到哈希桶类,此前声明
//封装迭代器
template<class T, class D2I = DToInt<T>>//DTOINT为将数据转化成整数数据方便使用哈希函数
class HashBucketIterator {
public:
typedef hashBucketNode<T> Node;
typedef hashBucket<T, D2I> table;
typedef HashBucketIterator<T, D2I> Self;
public:
HashBucketIterator(Node* node = nullptr, table* ht = nullptr)
:_node(node)
, _ht(ht)
{}
T& operator*() {
return _node->data;
}
T* operator->() {
return &(operator*());
}
bool operator==(Self& s) {
return _node == s._node;
}
bool operator!=(Self& s) {
return _node != s._node;
}
Self& operator++() {
Next();
return *this;
}
Self& operator++(int) {
Self temp = this;
Next();
return *temp;
}
private:
Node* _node;//哈希桶中存储的节点
table* _ht;//哈希表格
private:
void Next() {
if (_node->next) {
_node = _node->next;
}
//BucketNumber是哈希桶类中的哈希桶桶数量
else {
size_t No = _ht->hashFunc(_node->data) + 1;
for (; No < _ht->BucketNumber(); No++) {
_node = _ht->_table[No];
if (_node) {
return;
}
}
_node = nullptr;
}
}
};
后文为全部源代码:
Common.h
#pragma once
#include<string>
#include<iostream>
using namespace std;
template<class T>
class DToInt {
public:
size_t operator()(const T& data) {
return data;
}
};
class Str2Int {
size_t operator()(const string& s) {
return BKDRHash(s.c_str());
}
size_t BKDRHash(const char* str) {
size_t seed = 131;
size_t hash = 0;
while (*str) {
hash = hash * seed + (*str++);
}
return (hash & 0x7FFFFFFF);
}
};
HashBucket.hpp
#pragma once
#include<vector>
#include"Common.h"
//定义存储节点
template<class T>
struct hashBucketNode {
hashBucketNode(const T& x=T())
:next(nullptr)
,data(x)
{}
hashBucketNode<T>* next;
T data;
};
template<class T,class D2I= DToInt<T>>
class hashBucket;
//封装迭代器
template<class T, class D2I = DToInt<T>>
class HashBucketIterator {
public:
typedef hashBucketNode<T> Node;
typedef hashBucket<T, D2I> table;
typedef HashBucketIterator<T, D2I> Self;
public:
HashBucketIterator(Node* node = nullptr, table* ht = nullptr)
:_node(node)
, _ht(ht)
{}
T& operator*() {
return _node->data;
}
T* operator->() {
return &(operator*());
}
bool operator==(Self& s) {
return _node == s._node;
}
bool operator!=(Self& s) {
return _node != s._node;
}
Self& operator++() {
Next();
return *this;
}
Self& operator++(int) {
Self temp = this;
Next();
return *temp;
}
private:
Node* _node;
table* _ht;
private:
void Next() {
if (_node->next) {
_node = _node->next;
}
else {
size_t No = _ht->hashFunc(_node->data) + 1;
for (; No < _ht->BucketNumber(); No++) {
_node = _ht->_table[No];
if (_node) {
return;
}
}
_node = nullptr;
}
}
};
template<class T, class D2I >
class hashBucket {
public:
friend HashBucketIterator<T,D2I>;
public:
typedef HashBucketIterator<T,D2I> iterator;
typedef hashBucketNode<T> Node;
hashBucket(const size_t capacity=10)
:_table(capacity)
,_size(0)
{}
iterator begin() {
Node* cur = nullptr;
for (int i = 0; i < BucketNumber(); i++) {
if (_table[i]) {
cur = _table[i];
return iterator(cur, this);
}
}
}
iterator end() {
size_t No= BucketNumber()-1;
for (; No >= 0; No--) {
if (_table[No]) {
Node* cur = _table[No];
while (cur) {
cur = cur->next;
}
return iterator(cur, this);
}
}
}
size_t hashFunc(const T& x) {
return(x % _table.capacity());
}
bool Insert_unique(const T& data) {//插入唯一元素
//通过哈希函数计算哈希桶号
D2I Dtoint;
size_t bucketNo= hashFunc(Dtoint(data));
//查看元素是否重复
Node* cur = _table[bucketNo];
while (cur) {
if (Dtoint(data) == Dtoint(cur->data)) {
return false;
}
cur = cur->next;
}
//插入元素
Node* newnode = new Node(Dtoint(data));
newnode->next = _table[bucketNo];
_table[bucketNo] = newnode;
//修改元素个数
_size++;
}
bool Insert_Repttitiom(const T& data) {
//插入重复元素
//通过哈希函数计算哈希桶号
D2I Dtoint;
size_t bucketNo = hashFunc(Dtoint(data));
//直接插入元素
Node* newnode = new Node(Dtoint(data));
newnode->next = _table[bucketNo];
_table[bucketNo] = newnode;
//修改元素个数
_size++;
return true;
}
bool Erase_unique(const T& data) {
//删除元素
//通过哈希函数计算哈希桶号
size_t bucketNo = hashFunc(data);
//查找元素
Node* prev = nullptr;
Node* cur = _table[bucketNo];
while (cur) {
if (cur->data == data) {
if (prev == nullptr) {
_table[bucketNo] = cur->next;
delete cur;
cur = nullptr;
_size--;
return true;
}
else {
prev->next = cur->next;
delete cur;
_size--;
return true;
}
}
else
{
prev = cur;
cur = cur->next;
}
}
return false;
}
void Erase_Repttitiom(const T& data) {
//删除与data相等的所有元素
//通过哈希函数计算哈希桶号
size_t bucketNo = hashFunc(data);
Node* cur = _table[bucketNo];
Node* prev = nullptr;
while (cur) {
if (cur->data == data) {
if (prev == nullptr) {
_table[bucketNo] = cur->next;
delete cur;
cur = _table[bucketNo];
_size--;
}
else {
prev->next = cur->next;
delete cur;
_size--;
cur = prev;
}
}
else {
prev = cur;
cur = cur->next;
}
}
}
~hashBucket()
{
Clear();
}
void Print() {
for (int i = 0; i < _table.size(); i++) {
Node* cur = _table[i];
while (cur) {
cout << cur->data << " ";
cur = cur->next;
}
cout << "\n";
}
}
size_t Size() {
return _size;
}
//获取桶的数量
size_t BucketNumber() {
return _table.size();
}
private:
vector<Node*> _table;
size_t _size;
private:
void Clear() {
for (int i = 0; i < _table.size(); i++) {
Node* cur = nullptr;
while (cur) {
Node* cur = _table[i]->next;
_table[i] = cur->next;
delete cur;
}
}
_size = 0;
}
};


















 2180
2180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











