







桶排序(Bucket Sort)是一种分布式排序算法,适用于数据范围明确且均匀分布的情况。它的工作原理是将数组分到有限数量的桶子里,每个桶再个别排序(通常使用插入排序或其他简单排序算法),最后将所有桶中的元素合并成一个有序数组。桶排序的关键在于如何划分桶以及桶内元素的排序方法。下面是桶排序的基本步骤:
-
初始化桶:确定桶的数量和范围。桶的数量和数据范围有关,通常根据待排序数据的最大值和最小值来决定桶的数量,以保证数据分布的均衡。
-
分配元素到桶:遍历输入数组,根据元素值将它们分配到相应的桶中。分配方式通常是计算元素值与最小值的差值,然后除以桶的间隔(数据范围除以桶的数量),得到的结果即为元素应放入的桶的索引。
-
对每个桶进行排序:对每个非空桶内的元素进行排序。这里可以使用任何有效的排序算法,但通常选择简单且在小数据集上高效的算法,如插入排序。
-
合并桶:将所有桶中的元素按顺序合并成一个数组。这一步通常很简单,只需依次遍历每个非空桶,将桶内的元素顺序加入到结果数组中即可。
桶排序的优点是,当输入数据均匀分布时,它的平均时间复杂度可以达到线性时间O(n),这在某些特定情况下非常高效。然而,如果数据分布不均匀或者桶的数量选择不当,桶排序的性能会下降,甚至退化到接近O(n^2)。此外,桶排序需要额外的空间来存储桶,其空间复杂度取决于桶的数量,最坏情况下为O(n)。
桶排序实现示例图如下:
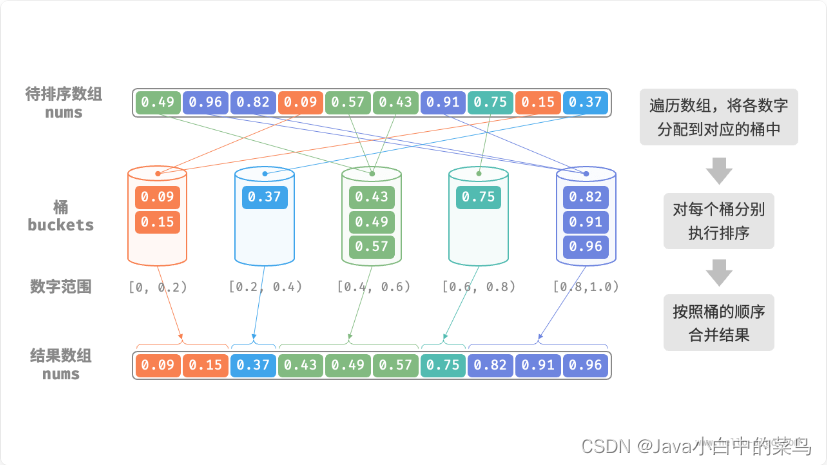
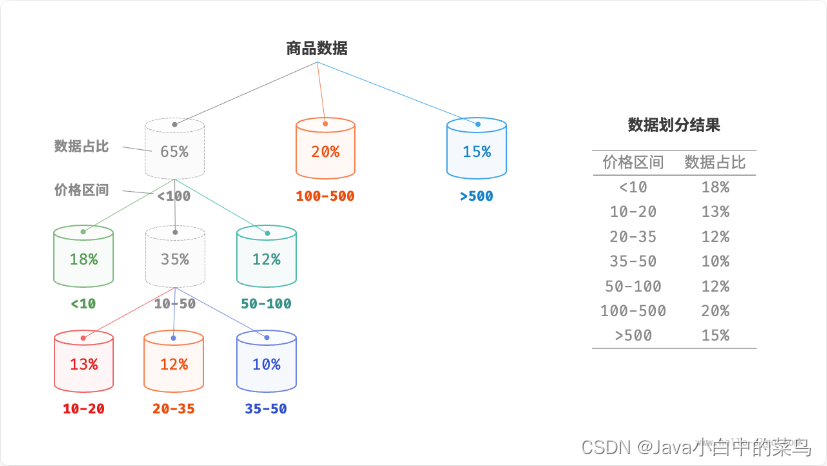
桶排序的时间复杂度理论上可以达到 𝑂(𝑛) ,关键在于将元素均匀分配到各个桶中,因为实际数据往往不是均匀分布的。例如,我们想要将淘宝上的所有商品按价格范围平均分配到 10 个桶中,但商品价格分布不均,低于 100 元的非常多,高于 1000 元的非常少。若将价格区间平均划分为 10 个,各个桶中的商品数量差距会非常大。
为实现平均分配,我们可以先设定一条大致的分界线,将数据粗略地分到 3 个桶中。分配完毕后,再将商品较多的桶继续划分为 3 个桶,直至所有桶中的元素数量大致相等。
桶排序在一些分布不均的时候桶划分如下图所示:
桶排序不适合于数据范围极大或极小的情况,也不适合数据分布极其不均匀的情况。在适用场景下,桶排序常与其他排序算法结合使用,以提高整体效率。
一下是实现桶排序的Java代码:
/* 桶排序 */
void bucketSort(float[] nums) {
// 初始化 k = n/2 个桶,预期向每个桶分配 2 个元素
int k = nums.length / 2;
List<List<Float>> buckets = new ArrayList<>();
for (int i = 0; i < k; i++) {
buckets.add(new ArrayList<>());
}
// 1. 将数组元素分配到各个桶中
for (float num : nums) {
// 输入数据范围为 [0, 1),使用 num * k 映射到索引范围 [0, k-1]
int i = (int) (num * k);
// 将 num 添加进桶 i
buckets.get(i).add(num);
}
// 2. 对各个桶执行排序
for (List<Float> bucket : buckets) {
// 使用内置排序函数,也可以替换成其他排序算法
Collections.sort(bucket);
}
// 3. 遍历桶合并结果
int i = 0;
for (List<Float> bucket : buckets) {
for (float num : bucket) {
nums[i++] = num;
}
}
}
















 2460
2460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









