







递归
什么是递归
其实之前已经接触过很多,就是函数自己调用自己的情况。
为什么会用到递归
本质是因为在解决主问题的时候,会遇到相同的子问题,在解决子问题的时候,会继续遇到相同的子问题。
如何写好一个递归
1.先找到相同的子问题 ---> 函数头的设计
2.只关心某一个子问题是如何解决的 ---> 函数体的书写
3.注意一下递归函数的出口即可
搜索vs深度优先遍历vs深度优先搜索vs宽度优先遍历vs宽度优先搜索vs暴搜
深度优先遍历vs深度优先搜索 宽度优先遍历vs宽度优先搜索
遍历是形式,搜索是目的。
拓展搜索问题:如果这个问题可以用决策树的形式画出来,那就可以使用dfs。
回溯与剪枝
回溯本质就是深搜!在找到最终结果的过程中,发现某一种情况走不通的时候,此时返回到上一级,从上一级继续开始尝试。所谓剪枝,就是在某一个节点,明确知道某条道路不是我们想要的结果时,就可以把这种结果剪掉。

class Solution
{
public:
void hanota(vector<int>& A, vector<int>& B, vector<int>& C)
{
dfs(A,B,C,A.size());
}
void dfs(vector<int>& A, vector<int>& B, vector<int>& C, int n)
{
if(n == 1)
{
C.push_back(A.back());
A.pop_back();
return;
}
dfs(A,C,B,n-1);
C.push_back(A.back());
A.pop_back();
dfs(B,A,C,n-1);
}
};我们依次来看当N=1、2、3...n的时候,如何解决汉诺塔问题:
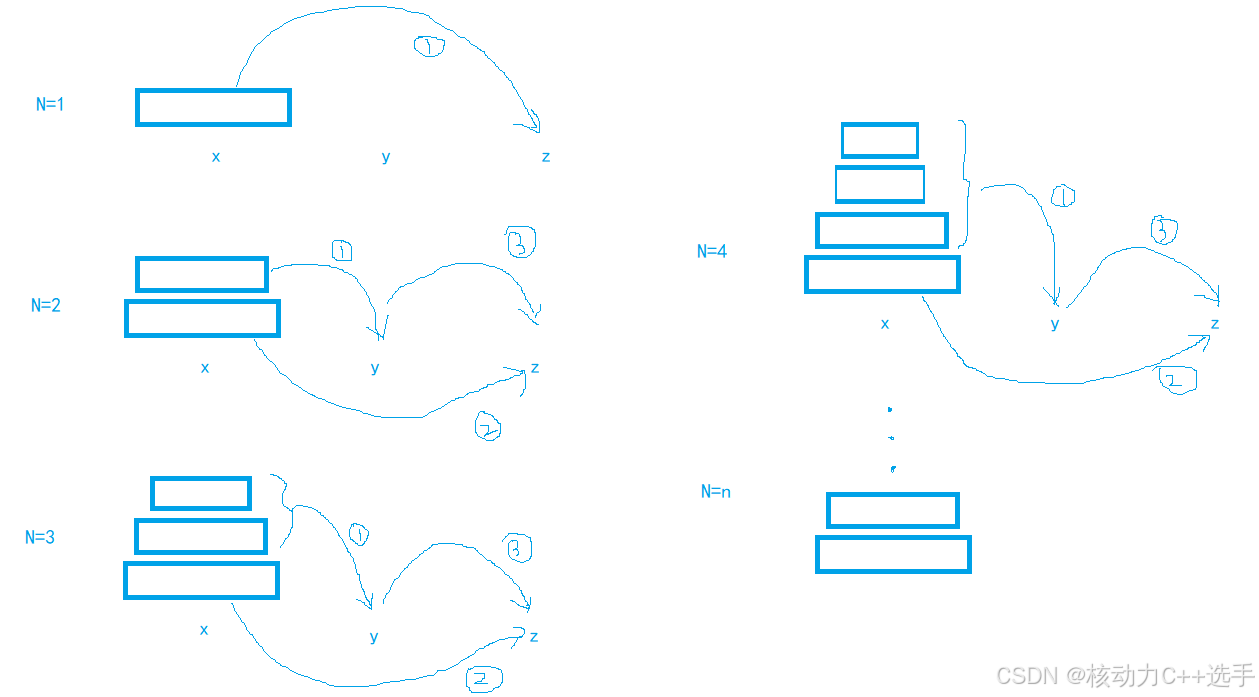
可以发现,当N不同时,步骤完全一样,都包含三步(N≠1),而且我们还发现,第①步和第③步几乎是一样的,都是通过一个柱子,把一堆盘子移到另一个柱子上,而第①步和第③步在N-1个盘子问题中已经实现。
那为什么可以使用递归呢?
大问题 --> 相同类型的子问题
子问题 --> 相同类型的子问题
如何编写递归代码?
1.重复子问题:函数头
把x柱子上的一堆盘子,借助y柱子,转移到z柱子上面。为了实现这个问题,至少要传4个参数,3个柱子以及要传几个盘子,因此dfs(x,y,z,int n)。
2.只关心某一个子问题要解决的事情:函数体
①先借助z柱子,把x上的n-1个盘子,放到y上,dfs(x,z,y,n-1)
②再把x柱子上的最后一个盘子放到z上,x.back() --> z
③再把y柱子上的n-1个盘子借助x放到z柱子上,dfs(y,x,z,n-1)
3.递归的出口
当n=1时,直接把x上的那个放到z上,不需要借助柱子。
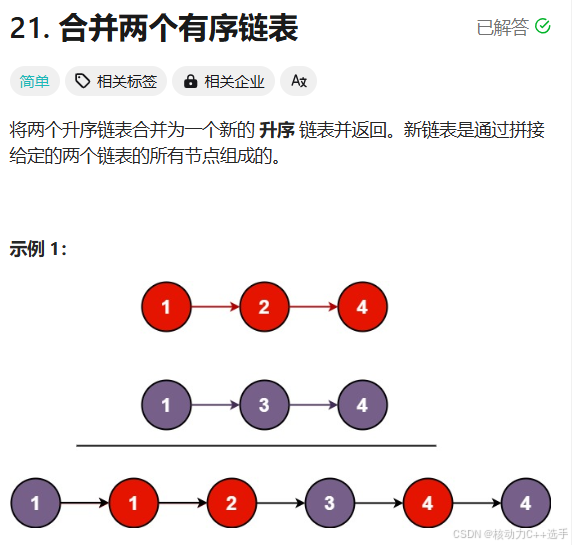
class Solution {
public:
ListNode* mergeTwoLists(ListNode* l1, ListNode* l2)
{
if(l1 == nullptr) return l2;
if(l2 == nullptr) return l1;
if(l1->val <= l2->val)
{
l1->next = mergeTwoLists(l1->next, l2);
return l1;
}
else
{
l2->next = mergeTwoLists(l1, l2->next);
return l2;
}
}
};题目分析:我们先来看这道题怎么想,首先要合并l1和l2两个链表,如果发现l1->val < l2->val,那么把l1->next和l2继续合并,插在l1指向节点的后面,我们发现每次合并两个链表是一个重复子问题,因此可以使用递归解决。
1.重复子问题:函数体设计,合并两个有序链表,Node* dfs(l1,l2)
2.只关心某一个子问题在做什么事情:函数体设计
1)比较大小 2)l1->next = dfs(l1->next,l2) 3)return l1;
3.递归的出口
如果某一个链表为空,则返回另一个链表
总结:我们来对比一下循环(迭代)和递归,其实它们本质都是解决重复的子问题,那有的时候用循环(迭代)容易,有的时候用递归容易,那如何选取呢?我们先来看一下递归和深搜的区别,递归的展开图其实就是对一棵树做一次深度优先遍历(dfs)。如果要改成循环,那就需要把每次的执行放到栈中保存。
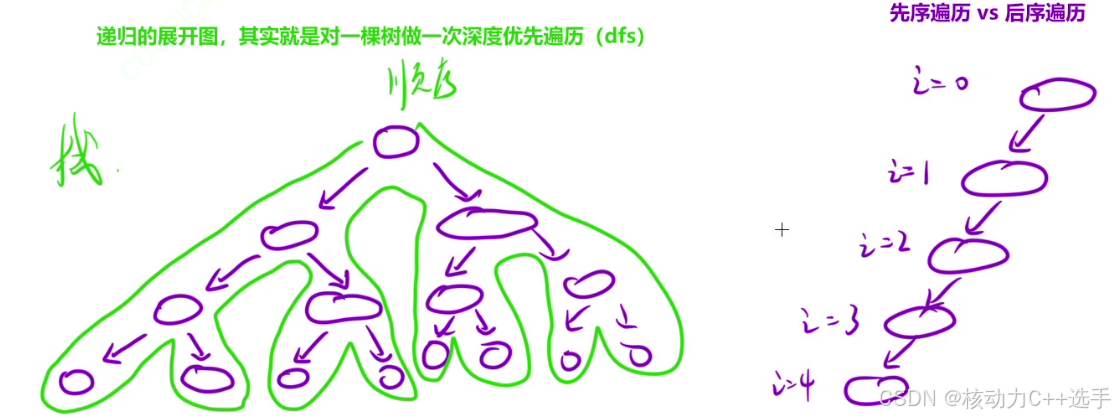
实际上,当遍历的树比较复杂时,如左图,就使用递归;当只需要遍历单支树时,如右图,就使用循环。
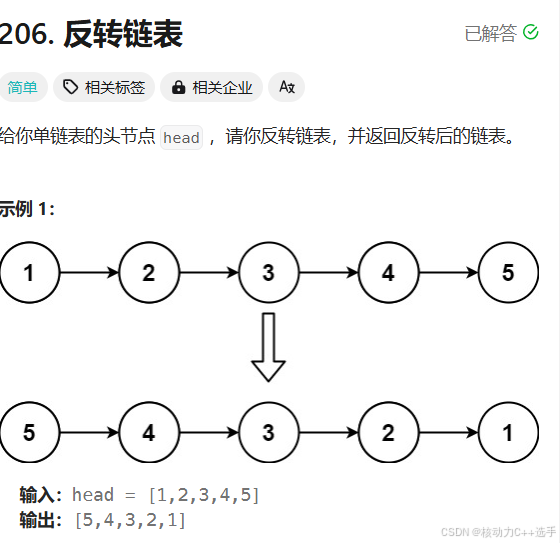
class Solution {
public:
ListNode* reverseList(ListNode* head)
{
if(head == nullptr || head->next == nullptr) return head;
ListNode* newnode = reverseList(head->next);
head->next->next = head;
head->next = nullptr;
return newnode;
}
};题目分析:采用递归,在把reverseList(head->next)递归后,再讲剩下的这个节点放到逆序后链表的后边。

class Solution {
public:
double myPow(double x, long long n)
{
return n < 0 ? 1/Pow(x, -n) : Pow(x, n);
}
double Pow(double x, long long n)
{
if(n == 0) return 1.0;
double tmp = Pow(x, n/2);
return n % 2 == 0 ? tmp*tmp : tmp*tmp*x;
}
};题目解析:这道题我们可以考虑使用递归,

1.相同的子问题:函数头->int pow(x,n)
2.只关心每一个子问题做了什么 ->函数体
tmp = pow(x, n/2) ; return n%2 == 0 ? tmp*tmp : tmp*tmp*x;
3.递归出口
n=0,return 1;
需要注意的是,需要考虑n为负数的情况;另外,如果n为-2^32,那取反就是2^32,int存不下,因此,需要强转为long long。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









