






 本文详细介绍了如何使用Python的open()函数处理文件,包括读取、写入、定位等操作,以及如何向HTML文件中插入特定内容。通过主函数,实现了对多个HTML文件的批量修改,添加'下载源码'链接。虽然代码可读性有待提高,但展现了Python在文件处理上的高效性。
本文详细介绍了如何使用Python的open()函数处理文件,包括读取、写入、定位等操作,以及如何向HTML文件中插入特定内容。通过主函数,实现了对多个HTML文件的批量修改,添加'下载源码'链接。虽然代码可读性有待提高,但展现了Python在文件处理上的高效性。
2021SC@SDUSC
前文分析如何获取符合要求的文件目录和对文件内容处理上部分,本文分析对文件内容做处理下部分和main函数。
目录
所需基本知识
Python open()
python open()函数用于打开一个文件,创建一个file对象,相关的方法才可以调用它进行读写。
语法
open(name[,mode[,buffering]]),mode、buffering是可选的
参数
name——一个包含要访问的文件名称的字符串值。
mode——决定了打开文件的模式:只读、写入、追加等。所有可取值见下列列表。mode是非强制的,默认文件访问模式为只读(r)。
buffering——如果buffering的值被设为0,就不会有寄存。如果 buffering 的值取 1,访问文件时会寄存行。如果将 buffering 的值设为大于 1 的整数,表明了这就是的寄存区的缓冲大小。如果取负值,寄存区的缓冲大小则为系统默认。
常用的打开文件模式列表:
- t:文本模式。
- x:写模式,新建一个文件,如果该文件已存在则会报错。
- b:二进制模式。
- +:打开一个文件进行更新(可读可写)。
- U:通用换行模式(不推荐)
- r:以制度方式打开文件。文件的指针将会放在文件的开头。这是默认模式。
- r+:打开一个文件用于读写。文件指针将会放在文件的开头。
- w:打开一个文件只用于写入。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
- w+:打开一个文件用于读写。如果该文件已存在则打开文件,并从开头开始编辑,即原有内容会被删除。如果该文件不存在,创建新文件。
- a:打开一个文件用于追加。如果该文件已存在,文件指针将会放在文件的结尾。也就是说,新的内容将会被写入到已有内容之后。如果该文件不存在,创建新文件进行写入。
- a+:打开一个文件用于读写。如果该文件已存在,文件指针将会放在文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
file对象方法
file.read()
用于从文件读取指定的字节数,如果未给定或为负则读取所有。
语法:fileObject.read([size]),返回从字符串中读取的字节。
参数:size——从文件中读取的字节数,默认为-1,表示读取整个文件。
file.readline()
用于从文件读取整行,包括 "\n" 字符。如果指定了一个非负数的参数,则返回指定大小的字节数,包括 "\n" 字符。
语法:fileObject.readline(size),返回从字符串中读取的字节。
参数:size——从文件中读取的字节数。
file.write()
方法用于向文件中写入指定字符串。
在文件关闭前或缓冲区刷新前,字符串内容存储在缓冲区中,这时你在文件中是看不到写入的内容的。
如果文件打开模式带 b(如rb、wb、rb+、wb+等),那写入文件内容时,str (参数)要用 encode 方法转为 bytes 形式,否则报错:TypeError: a bytes-like object is required, not 'str'。
file.tell()
返回文件的当前位置,即文件指针当前位置。
file.seek()
用于移动文件读取指针到指定位置。
语法:fileObject.seek(offset[,whence]),如果操作成功,则返回新的文件位置,如果操作失败,则函数返回 -1。
参数:offset——开始的偏移量,也就是代表需要移动偏移的字节数
whence——可选,默认值为0。给offset参数一个定义,表示要从哪个位置开始偏移;0代表从文件开头开始算起,1代表从当前位置开始算起,2代表从文件末尾算起。
file.close()
用于关闭一个已打开的文件。关闭后的文件不能再进行读写操作, 否则会触发 ValueError 错误。 close() 方法允许调用多次。
当 file 对象,被引用到操作另外一个文件时,Python 会自动关闭之前的 file 对象。 使用 close() 方法关闭文件是一个好的习惯。
对文件内容做处理
上文分析了定义addtofile函数,分析了如何得到filename,以及拼接href和addstr,用html表示出要下载的示例app的压缩包。
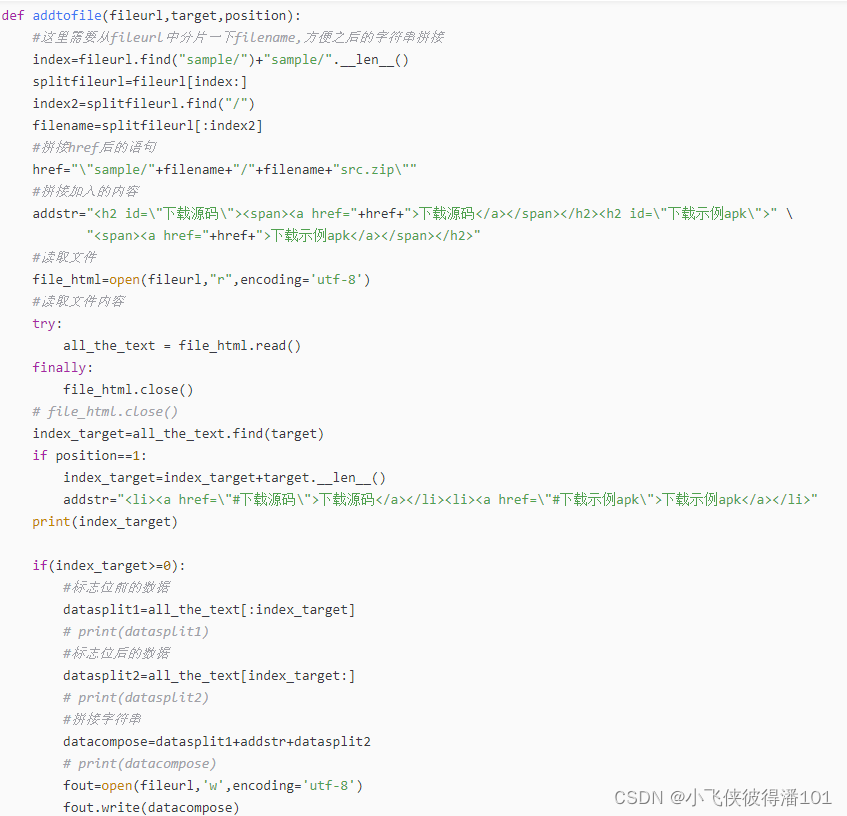
接下来分析如何向指定文件添加html"下载源码"的
首先调用open()函数打开fileurl指定的文件,mode为"r",表示为只读模式,encoding设置为"utf-8"。得到一个file对象file_html。

调用file.read()方法读取整个文件。read([size])方法从文件读取指定的字节数,如果未给定或为负则读取所有。默认参数为-1,表示读取整个文件。
用try...catch...finally来预防读取文件时报错,此处省略catch,在一定会执行的finally语句中调用close()方法关闭打开的文件,释放资源。

传入的字符串target,需要找到target的index,调用string的find()方法返回target的开始索引。
开发者定义position为1时就得添加addstr,若为0则不用添加。

index_target为文件中指定的target的开始索引,如果position等于1时,index_target需要加上target的长度,得到指定文件中target的结束索引。但是如果文件中不包含指定的target,index_target为-1。
用一个if语句判断index_target是否>0,如果target在文件中或position为1,即index_target>0,就要将addstr拼接到index_target索引处,并对文件内容进行修改。

datacompose为在index_target中插入addstr的新字符串。
调用open()方法打开指定文件,并调用file的write()方法将其写入文件。
缺点:应该调用file.close()关掉打开的文件。
主函数

首先调用上一篇文章分析的getfilelist_1()获取传入路径下所有包含"sample.html"(教学示例app的页面)的所有文件路径,储存在filelist列表中。
![]()
用for循环遍历列表中的所有文件,并调用addtofile()方法,向每个文件"</div></div>\n</body>\n</html>"开始处(因为position=0),添加"下载源码"链接并且a标签的href为相应的案例app源码的压缩包。

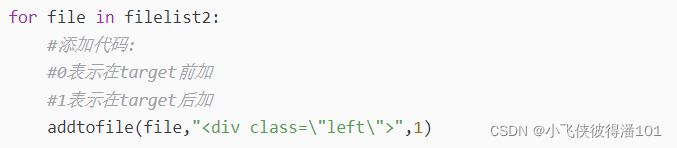
再调用getfilelist_2()方法获取指定路径的子目录文件中与子目录名相同的文件路径列表
![]()
用for循环遍历列表中的所有文件,并调用addtofile()方法,向每个文件"<div class=\"left\">"字符的结尾处(因为position=1),添加"下载源码"链接并且a标签的href为相应的案例app源码的压缩包。
总结
用python批量修改html,效率高,但是代码有些杂乱,逻辑性较差,复用性低,封装也较差,阅读起来较为费劲,是开发者为了修改页面写的零散的代码。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









