






redis 常用数据类型
(string,list,set,hash,zset)
1.字符串string
string 数据结构是简单的 key-value 类型。构建了一种简单动态字符串SDS,Redis 的 SDS 不光可以保存文本数据还可以保存二进制数据,并且获取字符串长度复杂度为 O(1),Redis 的 SDS API 是安全的,不会造成缓冲区溢出。
常用命令:
set【添加键值对】,get【获取键值对】
strlen【获取值的长度】
append【数据追加到原值的末尾】
dect【key中储存的数值-1】,incr【key中储存的数值+1】
setex【key不存在时,设置key值】` 等等。mset,mget,msetnx
应用场景 :一般常用在需要计数的场景,比如用户的访问次数、热点文章的点赞转发数量等等。
数据结构:简单动态字符串SDS
是可以修改的字符串,内部结构实现上类似于Java的ArrayList!,采用预分配冗余空间的方式来减少内存的频繁分配.
2.队列list
list链表, Redis 实现了自己的链表数据结构。Redis 的 list 的实现为一个双向链表,即可以支持反向查找和遍历,更方便操作,不过带来了部分额外的内存开销。
常用命令:
lpush,【从左边插入一个值或者多个值】rpush【从右边】
lpop【从左边吐出一个值】rpop【从右边】
rpoplpush【从右边吐出一个值插入左边】
lrange【按照索引下标获取元素】【从左到右】
llen` 【获取列表长度】
lrem【从左边删除n个value】
lset【将列表key下标为index的值替换成value】等。
应用场景: 发布与订阅或者说消息队列、慢查询。
数据结构:quickList快速链表
3.集合set
Redis的set是string类型的无序集合。它底层其实是一个value为null的hash表,所以添加,删除,查找的复杂度都是O(1)。
常用命令:
sadd【将一个或多个member元素加入到集合 key中,已经存在的member元素将被忽略。】
smembers【取出该集合的所有值。】
sismember【判断集合<key>是否为含有该<value>值,有1,没有0.】
scard【返回该集合的元素个数】
srem【删除集合中的某个元素】
spop【随机从该集合中吐出一个值】
srandmember【随机从该集合中取出n个值。不会从集合中删除】
smove【把集合中一个值从一个集合移动到另一个集合】
应用场景: 需要存放的数据不能重复以及需要获取多个数据源交集和并集等场景
set数据结构:dict字典,字典是通过哈希表实现的
Java中 HashSet的内部实现使用的是 HashMap,只不过所有的value都指向同一个对象。
Redis的set结构也是一样,它的内部也使用hash结构,所有的value都指向同一个内部值。
4.哈希hash
hash是一个键值对集合。内部实现也差不多(数组 + 链表)。hash 是一个 string 类型的 field 和 value 的映射表,特别适合用于存储对象,后续操作的时候,你可以直接仅仅修改这个对象中的某个字段的值。 比如我们可以 hash 数据结构来存储用户信息,商品信息等等。
常用命令:
hset,【给key集合中的field赋值】hget【从key集合中field取值value】
hmset,【批量设置hash值】
hexists,【查看哈希表key 中,给定域field是否存在。】
hkeys【列出该hash集合的所有fieldv】
hvals【列出该hash集合的所有value】 等。
应用场景: 系统中对象数据的存储。
数据结构: ziplist(压缩列表),hashtable(哈希表)。
当field-value长度软短且个数较少时,使用ziplist,否则使用hashtable。
5.zset
有序集合zset与普通集合set非常相似,是一个没有重复元素的字符串集不同之处是有序集合的每个成员都关联了一个评分( spore) ,这个评分(score)被用来按照从最低分到最高分的方式排序集合中的成员。集合的成员是唯一的,但是评分可以是重复了。
常用命令:
zadd【将一个或多个member元素及其score值加入到有序集 key当中】
zrank,【返回该值在集合中的排名,从О开始。】
zcount,【统计该集合,分数区间内的元素个数】
zrevrange【返回有序集 key中,所有score值介于min和max之间(包括等于min或max )的成员】
zrem【删除该集合下,指定值的元素】等。
应用场景:需要对数据根据某个权重进行排序的场景。比如在直播系统中,实时排行信息包含直播间在线用户列表,各种礼物排行榜,弹幕消息(可以理解为按消息维度的消息排行榜)等信息。
数据结构:
(1) hash , hash的作用就是关联元素value和权重score,保障元素value的唯一性,可以通过元素value找到相应的score值。
(2)跳跃表,跳跃表的目的在于给元素value排序,根据score的范围获取元素列表。
跳跃表(zset跳表)
对于有序集合的底层实现,可以用数组、平衡树、链表等。
数组不方便元素的插入、删除;
平衡树或红黑树虽然效率高但结构复杂;
链表查询需要遍历所有效率低。
Redis采用的是跳跃表。跳跃表效率堪比红黑树,实现远比红黑树简单。
跳表全称为跳跃列表,它允许快速查询,插入和删除一个有序连续元素的数据链表。跳跃列表的平均查找和插入时间复杂度都是O(logn)。
快速查询是通过维护一个多层次的链表,且每一层链表中的元素是前一层链表元素的子集。一开始时,算法在最稀疏的层次进行搜索,直至需要查找的元素在该层两个相邻的元素中间。这时,算法将跳转到下一个层次,重复刚才的搜索,直到找到需要查找的元素为止。
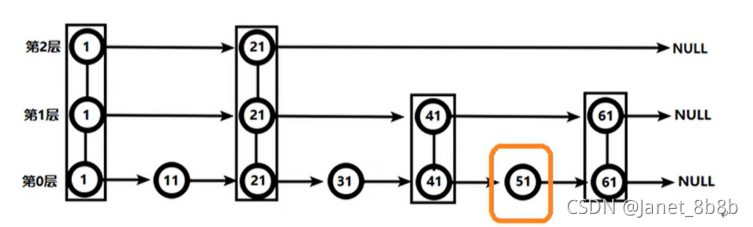
从第2层开始,1节点比51节点小,向后比较。21节点比51节点小,继续向后比较,后面就是NULL了,所以从21节点向下到第1层
在第1层,41节点比51节点小,继续向后,61节点比51节点大,所以从41向下在第0层,51节点为要查找的节点,节点被找到,共查找4次。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









