







 本文通过实验比较了SVM、MLP、SGD三种分类器在手写数字体digits和鸢尾花数据集上的性能。SVM在digits数据集上,使用rbf核函数达到98.9%的准确率。而对于鸢尾花数据集,MLP的不同参数组合,如adam优化器配合特定激活函数,可以实现100%的准确率。实验强调了针对不同数据集选择最佳分类器参数的重要性。
本文通过实验比较了SVM、MLP、SGD三种分类器在手写数字体digits和鸢尾花数据集上的性能。SVM在digits数据集上,使用rbf核函数达到98.9%的准确率。而对于鸢尾花数据集,MLP的不同参数组合,如adam优化器配合特定激活函数,可以实现100%的准确率。实验强调了针对不同数据集选择最佳分类器参数的重要性。
问题描述
提示:这里可以添加系列文章的所有文章的目录,目录需要自己手动添加
通过实验方法(分类器类型选择、优化方法、激活函数),设计一个“最优的”手写数字体digits数据集和鸢尾花数据集的分类器
欢迎大家交流技术,如果有任何问题可以私聊我,期待你们的关注
方法
我是使用到SVM、MLP、SGD三种分类器,针对每个分类器指定不同的参数,SVM设置不同的kernel参数值,包括’linear’, ‘poly’, ‘rbf’, ‘sigmoid’;MLP设置不同的solver优化器,包括’adam’, ‘lbfgs’, ‘sgd’,activation激活函数包括’tanh’, ‘relu’, ‘logistic’, ‘identity’;SGD设置不同的loss包括’hinge’, ‘log’, ‘modified_huber’, ‘squared_hinge’, ‘perceptron’。然后针对这些不同的分类器对手写体数字的数据集进行分类测试,根据测试的准确率来判断每个分类器的性能,将每个分类器的准确率放到一个字典中,字典的键是分类器的名称,字典的值是分类器对应的准确率,最后得到最好的分类器及其准确率。
optim = ['adam', 'lbfgs', 'sgd']
act = ['tanh', 'relu', 'logistic', 'identity']
ker = ['linear', 'poly', 'rbf', 'sigmoid']
opt = ['hinge', 'log', 'modified_huber', 'squared_hinge', 'perceptron']
结果展示
经过实验验证得到使用SVM并且使用rbf的和函数能够在手写体数字识别的数据集上获得最后的分类准确率,为98.9%。
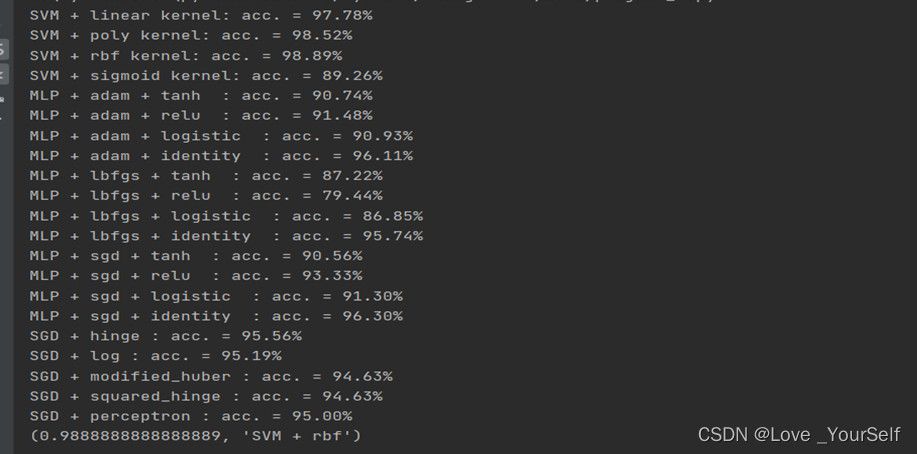
针对鸢尾花的数据集,性能较好的分类器包括MLP使用adam的优化器和logistic的激活函数、MLP使用adam的优化器和tanh的激活函数、MLP使用adam的优化器和identity的激活函数、MLP使用sgd的优化器和tanh的激活函数、MLP使用sgd的优化器和identity的激活函数、MLP使用lbfgs的优化器和identity的激活函数的分类器,这些能够使准确率达到100%。
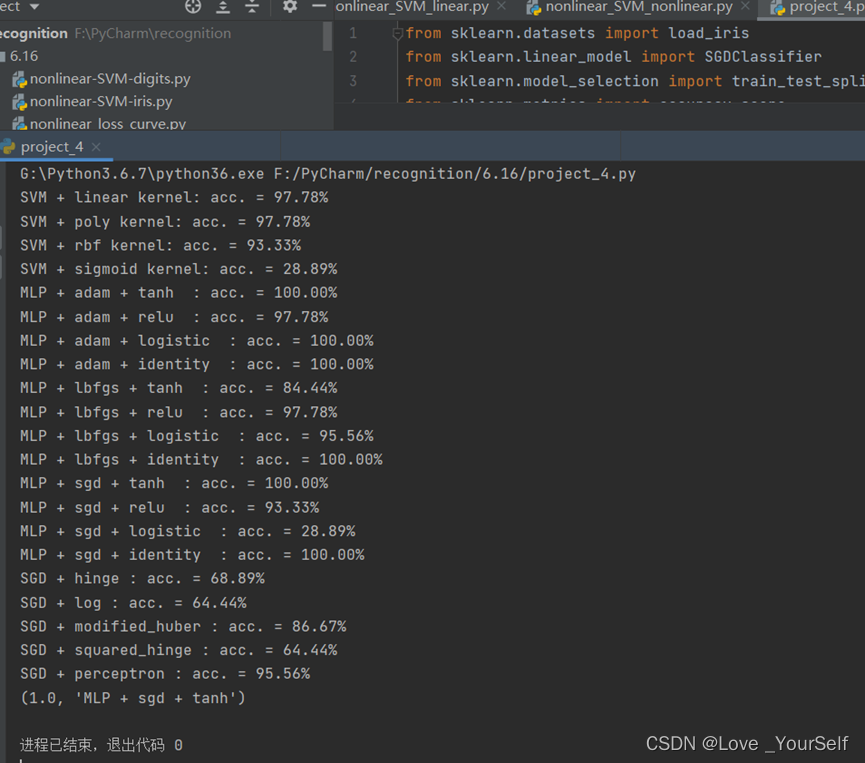
针对不同的数据集分类器的性能是不同的,要针对不同情况的数据集实验得到最优的分类器的参数。

















 805
805

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









