









景点评论爬取与可视化
摘要
景点评论数据对于旅行者和旅游从业者来说具有重要性,它可以提供有关景点质量、用户体验和旅游建议的宝贵信息。
本文主要利用python中的requests模块请求数据,对评论数据进行清洗,分词,以及可视化。
数据获取
网页分析
下面以爬取武当山评论为例子:
https://you.ctrip.com/sight/danjiangkou1018/136382.html
评论采用瀑布流模式,需要控制台抓包,进行分析
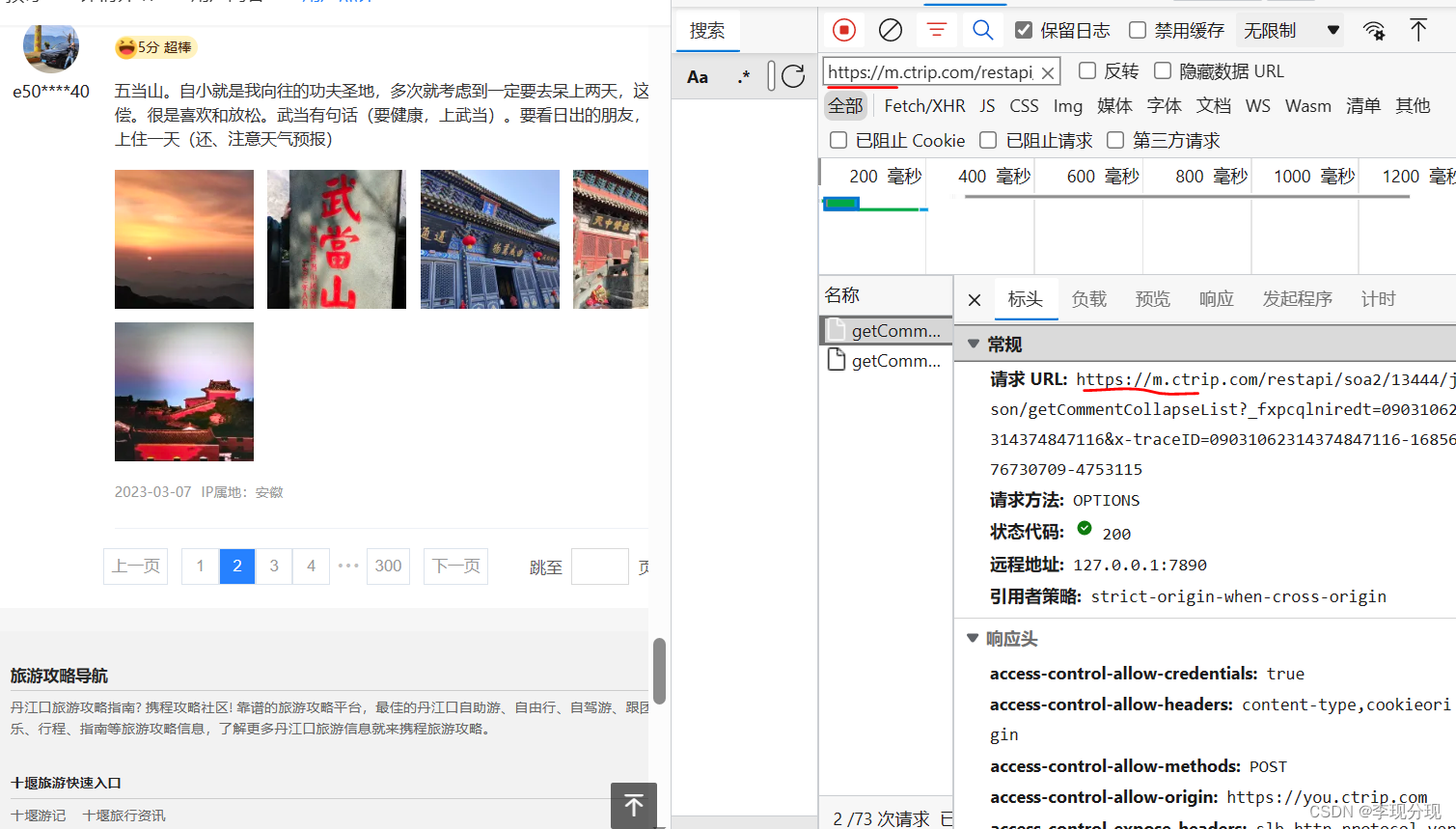
查看携带参数, pageIndex是页数,commentTagId是评论类型,有好评差评等等,poiId是景点id,其他参数不用管
data = {
"arg":
{"channelType":2,
"collapseType":0,
"commentTagId":0,
"pageIndex":page,
"pageSize":10,
"poiId":id,
"sourceType":1,
"sortType":3,
"starType":0
},
"head":
{"cid":"09031062314374847116",
"ctok":"",
"cver":"1.0",
"lang":"01",
"sid":"8888",
"syscode":"09",
"auth":"",
"xsid":"",
"extension":[]}
}
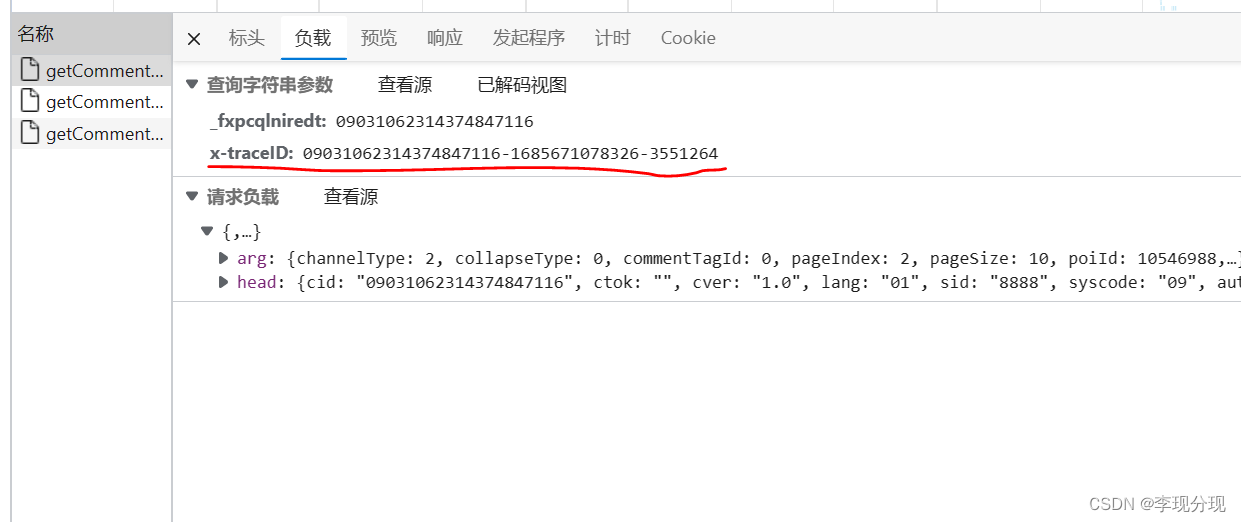
携程评论采用比较简单的js逆向,需要进行js反爬,解析x-traceID
09031062314374847116-1685671078326-3551264
09031062314374847116固定值,不用管
1685671078326 时间戳
3551264 10000000以内随机数
代码编写
import requests
import codecs,csv
import time
import random
#请求头,模拟浏览器操作
headers={
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36 Edg/111.0.1661.41',
'referer': 'https://you.ctrip.com/',
}
#景点id
idList=['10546988']
#爬取景点评论方法方法
def getComment():
#爬取不同景点
for id in idList:
page=1
#循环爬取所有页数
while True:
try:
print('正在爬取'+str(page)+'页')
#综合 commentTagId:0
#差评 commentTagId:-12
#好评 commentTagId:-11
#post请求携带参数
data = {
"arg":
{"channelType":2,
"collapseType":0,
"commentTagId":0,
"pageIndex":page,
"pageSize":10,
"poiId":id,
"sourceType":1,
"sortType":3,
"starType":0
},
"head":
{"cid":"09031062314374847116",
"ctok":"",
"cver":"1.0",
"lang":"01",
"sid":"8888",
"syscode":"09",
"auth":"",
"xsid":"",
"extension":[]}
}
#时间戳
t="09031062314374847116"
times=round(time.time()*1000)
#随机数
num=int(10000000*random.random())
# 拼接参数
n=t+"-"+str(times)+"-"+str(num)
print(n)
url='https://m.ctrip.com/restapi/soa2/13444/json/getCommentCollapseList?_fxpcqlniredt=09031062314374847116&x-traceID='+str(n)
#发送请求
res=requests.post(url,headers=headers,json=data)
print(res)
# print(res.json()['result']['items'])
#提取数据
data=res.json()['result']['items']
#页数遍历完成,为空
if data==None:
print('over')
break
# if(page>=1000):
# break
#提取评论信息
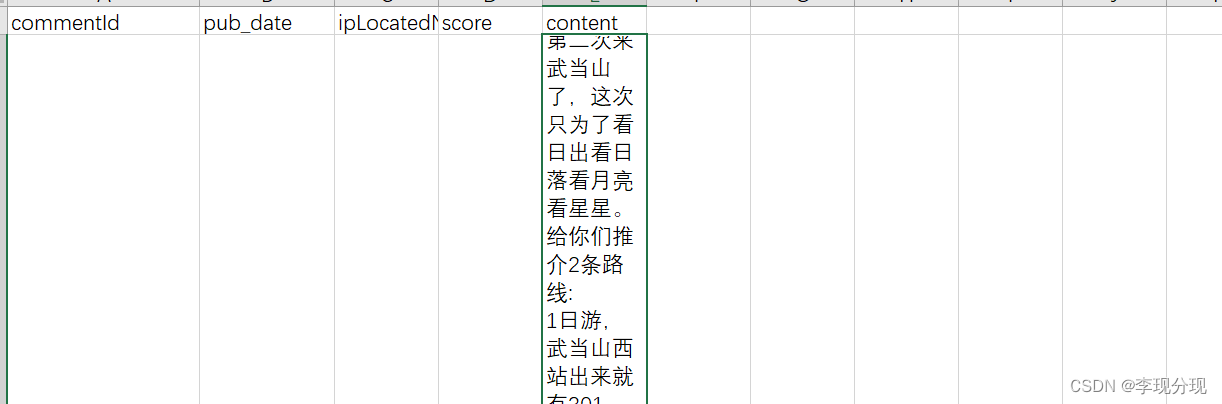
for item in data:
comments={}
comments['commentId']=item['commentId']
comments['content']=item['content']
comments['pub_date']=item['publishTypeTag'].split(' ')[0]
comments['ipLocatedName']=item['ipLocatedName']
comments['score']=item['score']
yield comments
time.sleep(1)
page+=1
except Exception as e:
print(e)
break
if __name__=='__main__':
#保存数据
f=codecs.open('武当山.csv','w+',encoding='utf-8-sig')
filename=['commentId','pub_date','ipLocatedName','score','content']
writer=csv.DictWriter(f,filename)
writer.writeheader()
#调用方法
for i in getComment():
print(i)
writer.writerow(i)
可视化
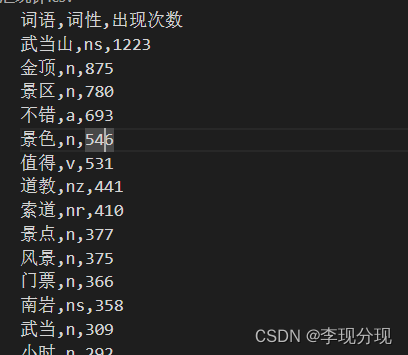
分词,统计词频
import jieba.posseg as pseg
from collections import Counter
import pandas as pd
import codecs
import csv
import jieba
import jieba.analyse
# 创建文件
f = codecs.open('词汇统计.csv', 'w+', encoding='utf-8-sig')
filename = ['词语', '词性', '出现次数']
writer = csv.DictWriter(f, filename)
writer.writeheader()
# 读写评论文件
df = pd.read_csv('武当山.csv')
text = ''
for i in df['content']:
text += str(i)
# 分词
words = jieba.lcut(text, cut_all=False, HMM=True)
# 获取停用词列表
filterWord = []
# 自行网络下载
with open('stopwords.txt', 'r', encoding='utf-8') as f:
for word in f.readlines():
word = word.replace('\n', '')
filterWord.append(word)
# 指定要统计的词语列表,topK指定统计词汇权重
target_words = jieba.analyse.extract_tags(' '.join(words), topK=100)
# 筛选出指定的词语并进行词性标注
filtered_words = []
for word, flag in pseg.cut(' '.join(words)):
if word in target_words and word not in filterWord:
filtered_words.append((word, flag))
# 统计词频并转换成 DataFrame 格式
word_counts = Counter(filtered_words)
for (word, flag), count in word_counts.most_common():
obj = {
'词语': word,
'词性': flag,
'出现次数': count
}
print(obj)
writer.writerow(obj)
f.close()
词云
对词汇统计表手动去除无用词之后,进行词云可视化
import matplotlib.pyplot as plt
from PIL import Image
import numpy as np
from wordcloud import WordCloud, ImageColorGenerator
import pandas as pd
from nltk.corpus import stopwords
words=[]
df = pd.read_csv('词汇统计.csv')
for word in df['词语']:
words.append(word)
stop_words = set(stopwords.words('chinese'))
words=[word for word in words if word not in stop_words]
word=' '.join(words)
print(word)
# image = np.array(Image.open('./bg.png'))#打开背景图
# mask=image 添加词云形状
# wordcloud = WordCloud(background_color="white",mask=image, font_path='simfang.ttf', margin=2).generate(word)
wordcloud = WordCloud(background_color="white", font_path='simfang.ttf', margin=2).generate(word)
plt.imshow(wordcloud, alpha=1)
plt.axis("off")
plt.show()
wordcloud.to_file('词云.png')

情感分析
from snownlp import SnowNLP
import pandas as pd
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['Microsoft YaHei']
plt.rcParams['font.size'] = 10
plt.rcParams['axes.unicode_minus'] = False
df = pd.read_csv('武当山.csv')
comment_list = df['content'].tolist()
def sentiment_analyze(comment_list):
score_list = []
tag_list = []
pos_count = 0
neg_count = 0
mid_count = 0
for comment in comment_list:
tag = ''
sentiment_score = SnowNLP(comment).sentiments
if sentiment_score < 0.5:
tag = '消极'
neg_count += 1
elif sentiment_score > 0.5:
tag = '积极'
pos_count += 1
else:
tag = '中性'
mid_count += 1
score_list.append(sentiment_score)
tag_list.append(tag)
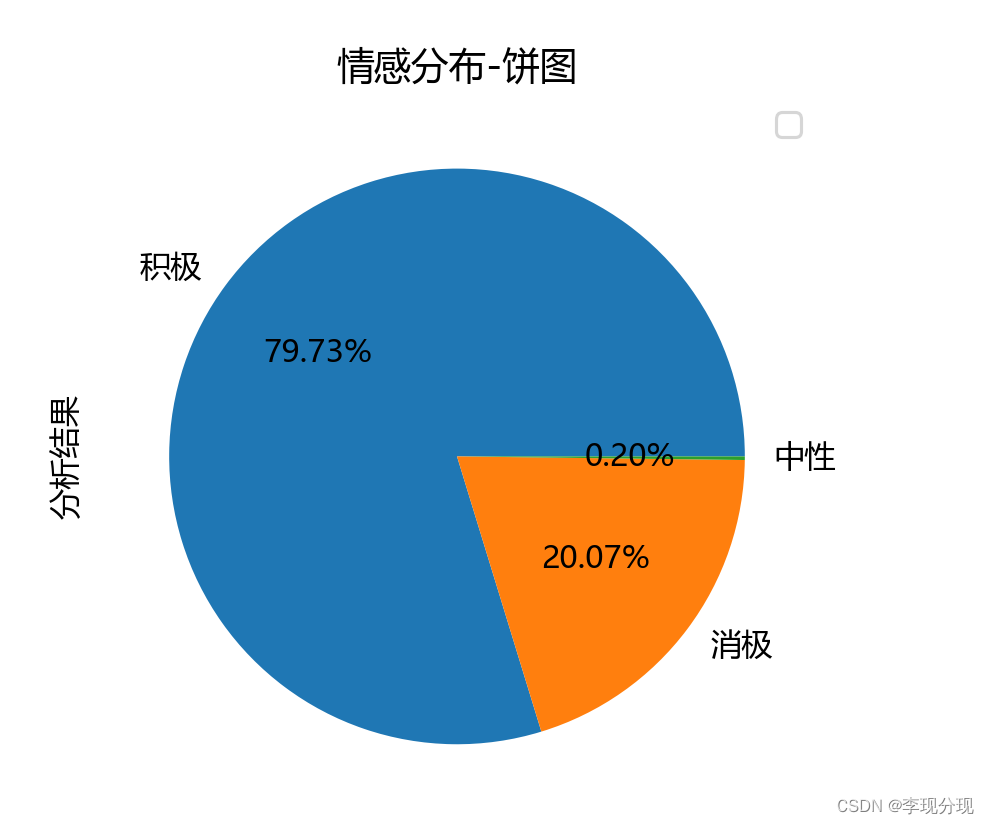
df['情感得分'] = score_list
df['分析结果'] = tag_list
grp = df['分析结果'].value_counts()
plt.figure(figsize=(5, 5), dpi=150)
grp.plot.pie(autopct='%.2f%%')
plt.title('情感分布-饼图')
plt.savefig('情感分布-饼图.png')
plt.show()
plt.close()
df.to_excel('情感评分结果.xlsx', index=None)
sentiment_analyze(comment_list)
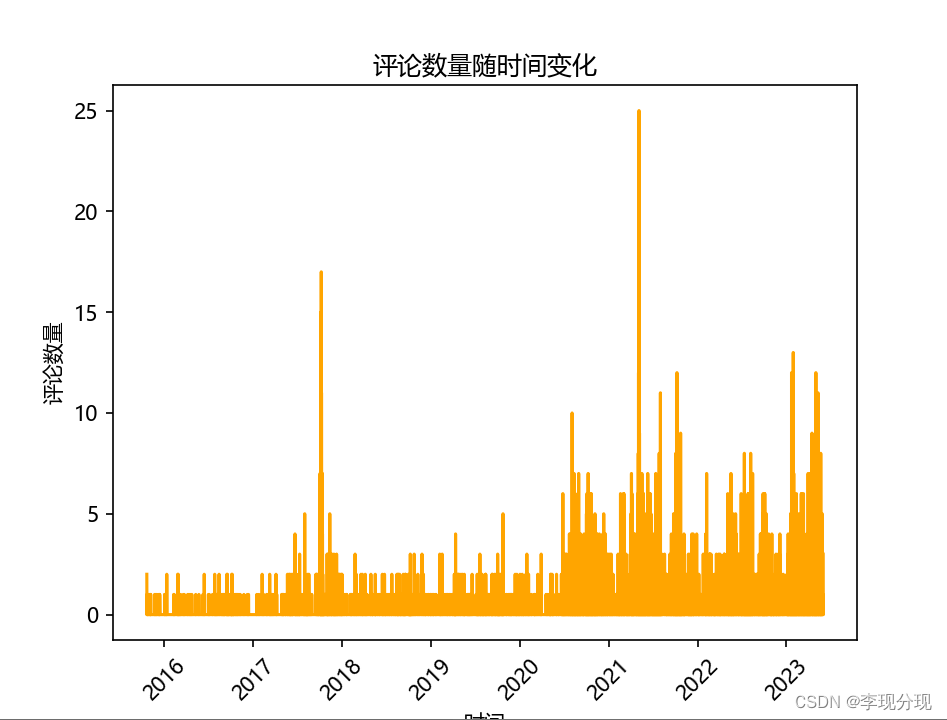
评论热度折线图
import pandas as pd
import matplotlib.pyplot as plt
# 读取CSV文件
df = pd.read_csv('武当山.csv')
# 将发布时间转换为日期格式
df['pub_date'] = pd.to_datetime(df['pub_date'])
# 设置日期为索引
df.set_index('pub_date', inplace=True)
# 按日期统计评论数量
comment_counts = df.resample('H').count()
# 生成折线图
plt.plot(comment_counts.index, comment_counts['content'],color='orange')
#防止字体乱码
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
plt.rcParams['font.size']=10
plt.rcParams['axes.unicode_minus']=False
# 设置图表标题和坐标轴标签
plt.title('评论数量随时间变化')
plt.xlabel('时间')
plt.ylabel('评论数量')
# 旋转x轴标签以避免重叠
plt.xticks(rotation=45)
plt.savefig('评论热度折线图.png')
# 显示图表
plt.show()
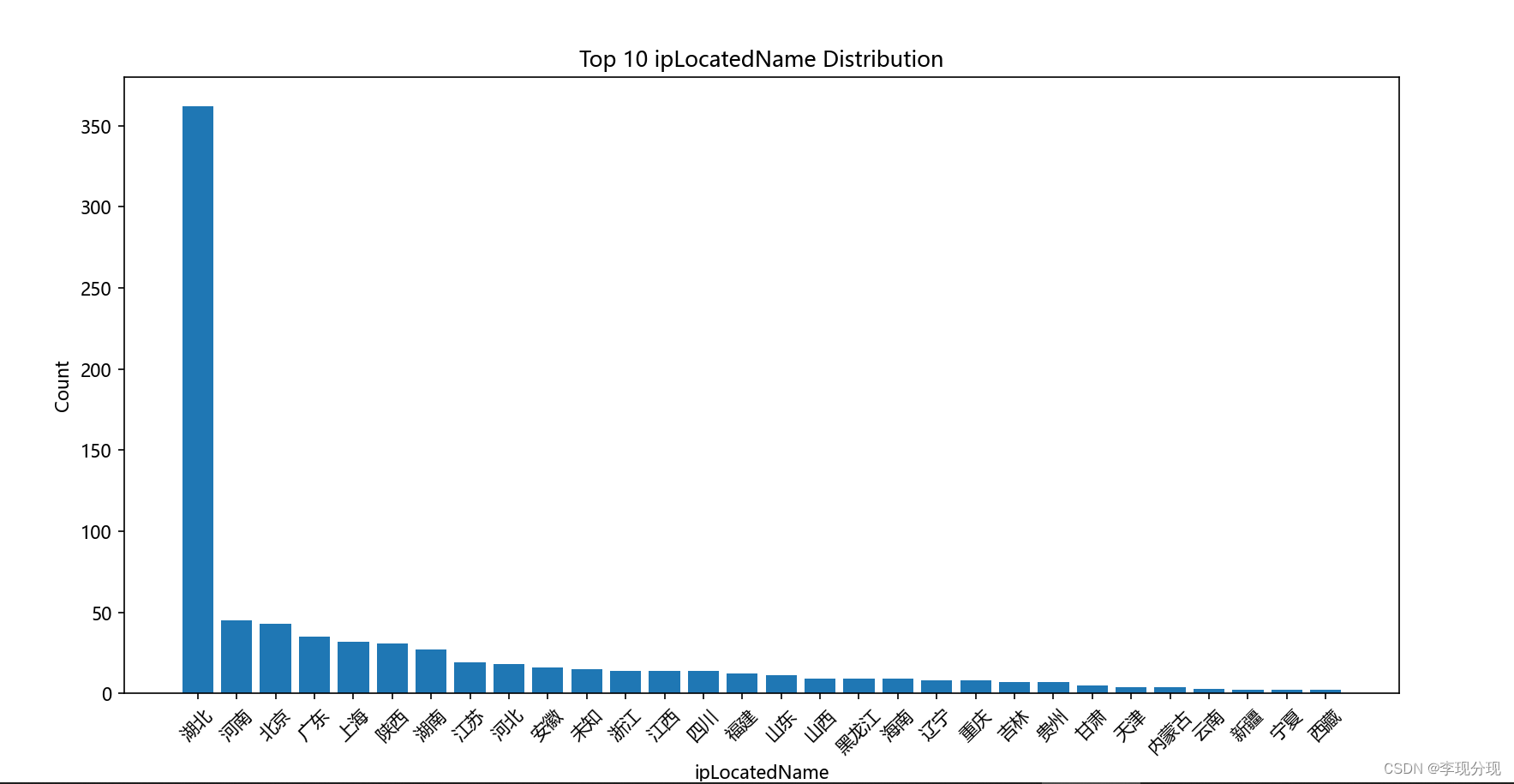
评论用户分布
import pandas as pd
import matplotlib.pyplot as plt
# 加载CSV文件
df = pd.read_csv('武当山.csv')
# 统计ipLocatedName的分布并选取top10
top10_ip = df['ipLocatedName'].value_counts().head(30)
#防止字体乱码
plt.rcParams['font.sans-serif']=['Microsoft YaHei']
plt.rcParams['font.size']=10
plt.rcParams['axes.unicode_minus']=False
# 可视化
plt.bar(top10_ip.index, top10_ip.values)
plt.xlabel('ipLocatedName')
plt.ylabel('Count')
plt.title('Top 10 ipLocatedName Distribution')
plt.xticks(rotation=45)
plt.show()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









