







 本教程详细介绍了如何安装Ubuntu18操作系统,并在此基础上完成Hadoop的单机及伪分布式配置。从虚拟机搭建开始,一步步指导安装Ubuntu系统、配置网络、使用XShell进行主机与虚拟机之间的交互,直至完成Hadoop环境搭建。
本教程详细介绍了如何安装Ubuntu18操作系统,并在此基础上完成Hadoop的单机及伪分布式配置。从虚拟机搭建开始,一步步指导安装Ubuntu系统、配置网络、使用XShell进行主机与虚拟机之间的交互,直至完成Hadoop环境搭建。
Ubuntu18保姆级教程及其hadoop安装含资源
安装Ubuntu
新建Ubuntu虚拟机
1.点击新建
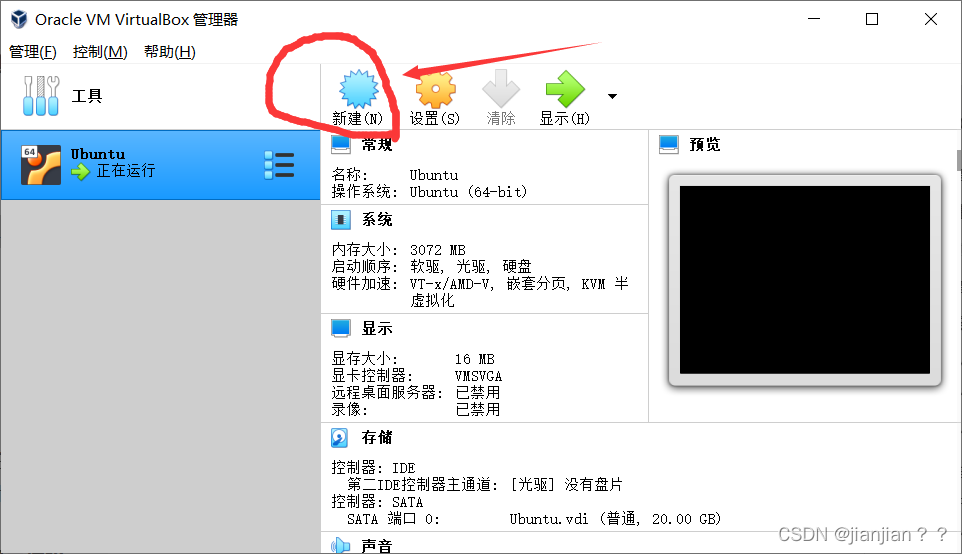
2.自定义虚拟机的名称,修改虚拟机所在文件夹,默认为C盘,建议改到C盘外的其他盘,然后点击下一步
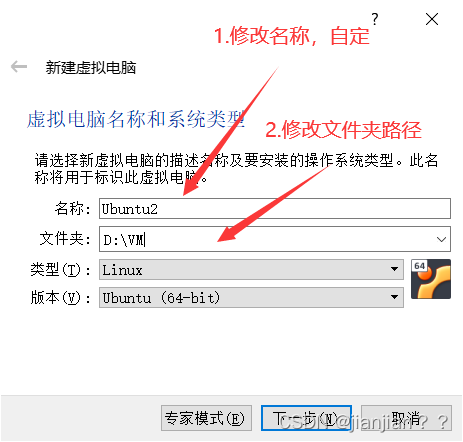
3.内存分配,笔者主机内存为8G,可分2~3G给虚拟机。如果分多了可能造成主机卡机,分少了可能造成虚拟机卡机,分配好后点击下一步
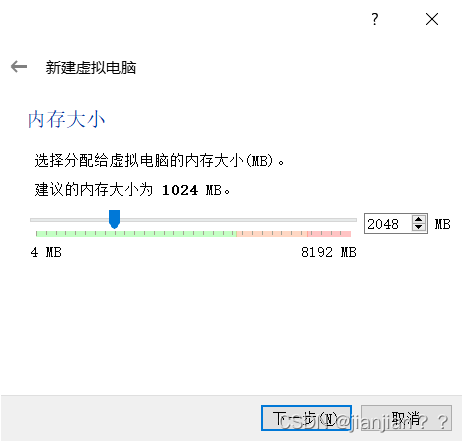
4.一直点击下一步,直至硬盘分配(如下图),默认分配为10G,可根据自身主机的硬盘大小合理分配即可,笔者此处分配20G,设置完后点击创建。
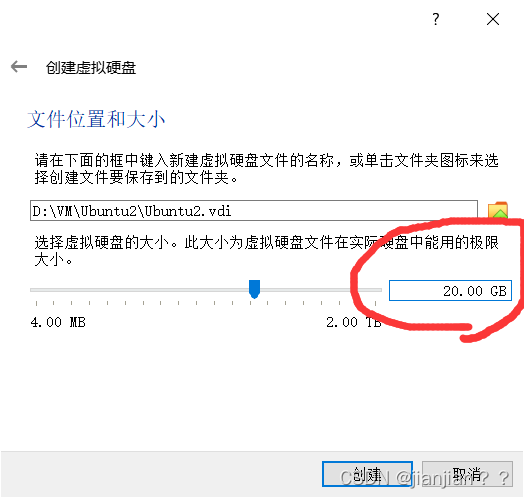
设置虚拟机
1.创建成功后我们此处会有一个虚拟机,但此时千万不要点击启动!!!但此时千万不要点击启动!!!但此时千万不要点击启动!!!先选中虚拟机。
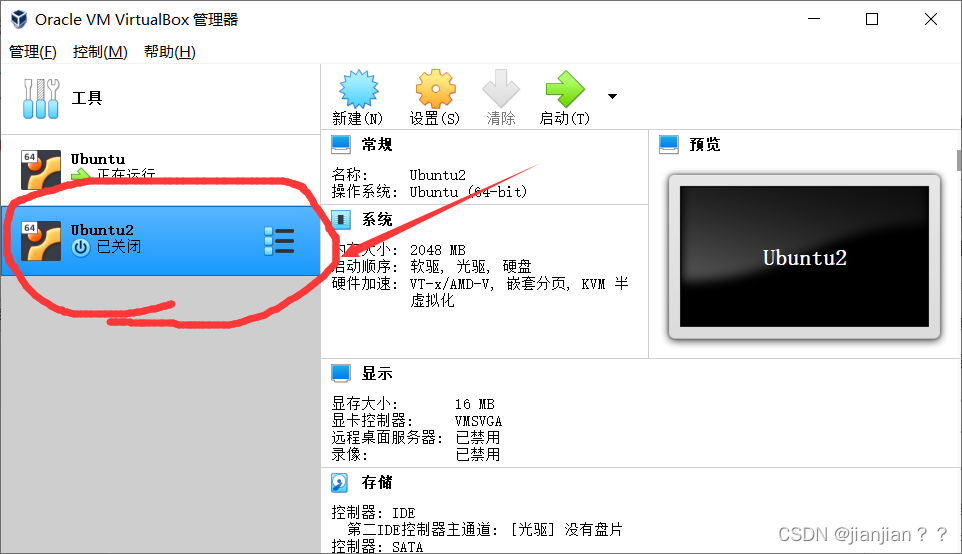
2.此时虚拟机并没有盘面,我们将鼠标移动到[没有盘面]上,然后点击
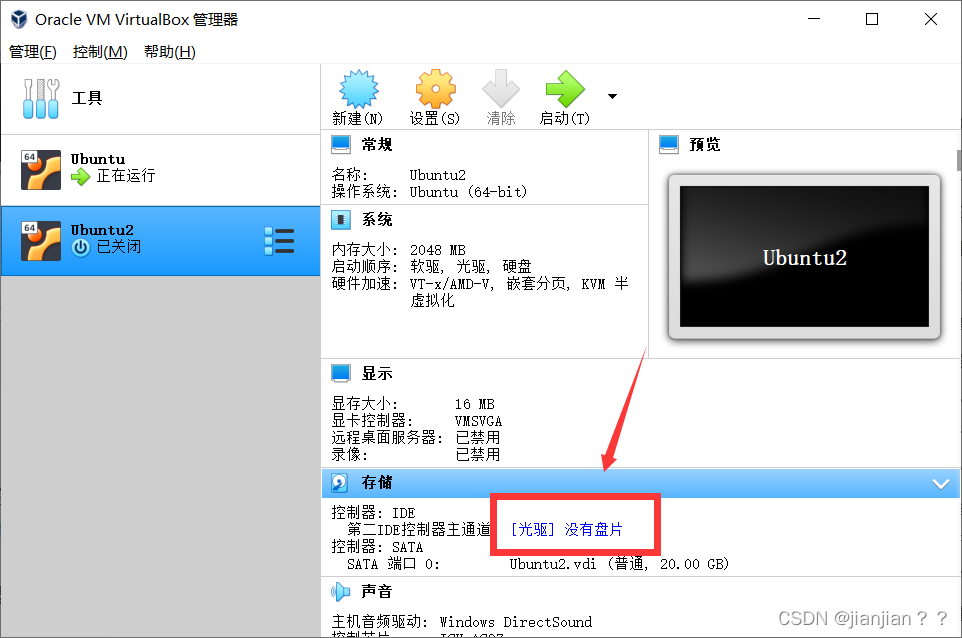
3.如果之前操作过此步骤,则会有盘面,直接点击盘面即可,如ubuntu018.04.6-desktop-amd64.iso 也可能是其他的xx.iso,若没有则点击第二个 choose a disk file…,进行盘片选择。
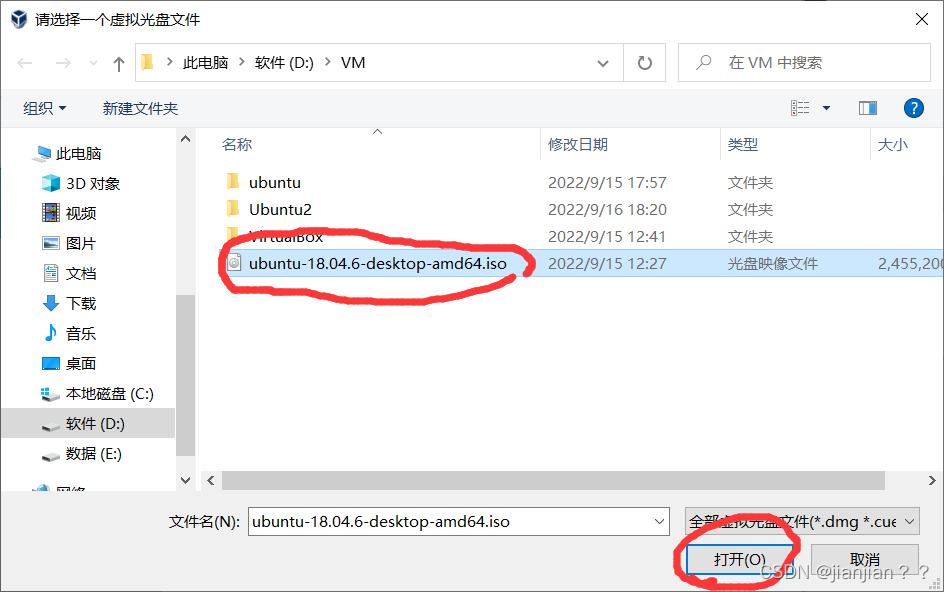
4.选中电脑中的iso文件,点击打开即可。
安装Ubuntu系统
1.选中虚拟机,点击启动
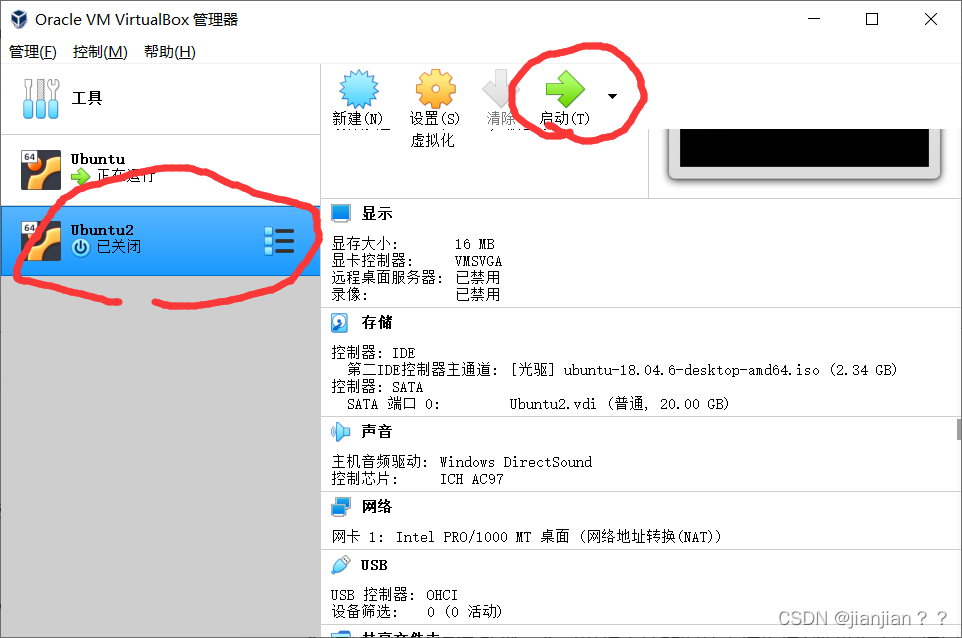
2.选择中文简体,点击安装Ubuntu
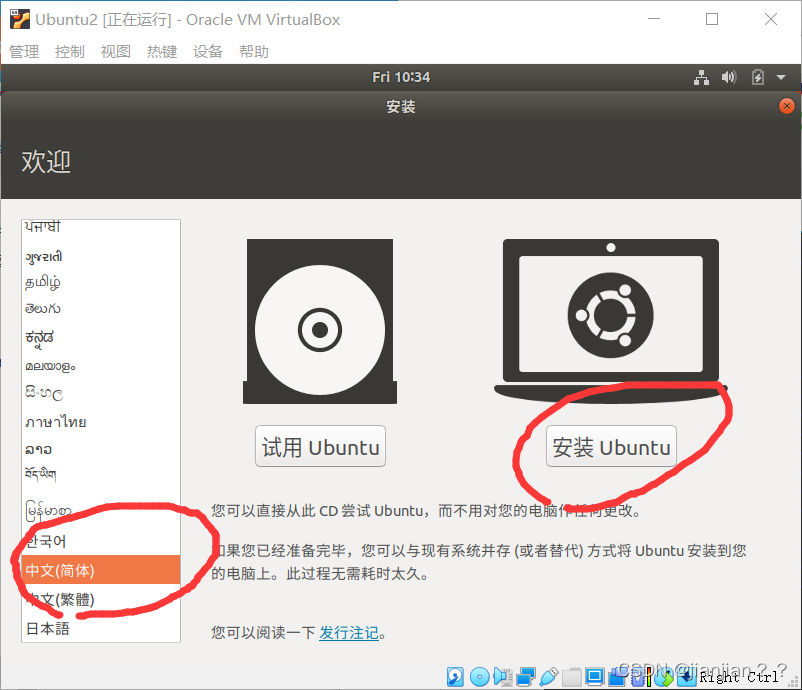
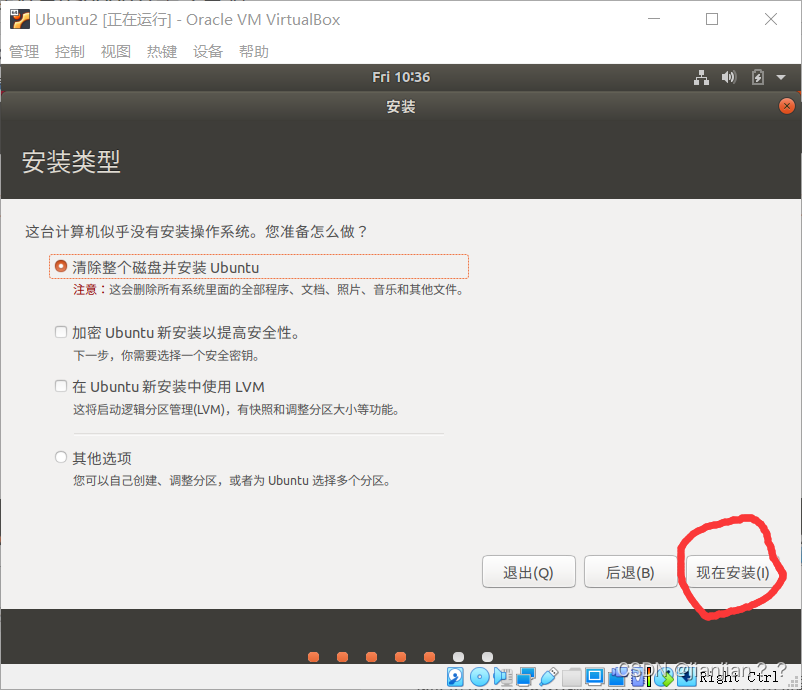
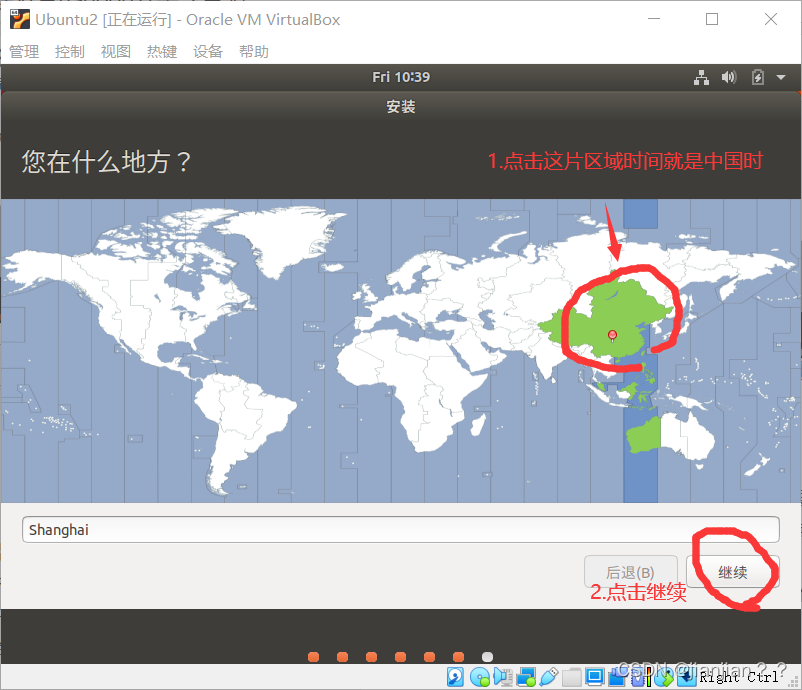
3.点击继续
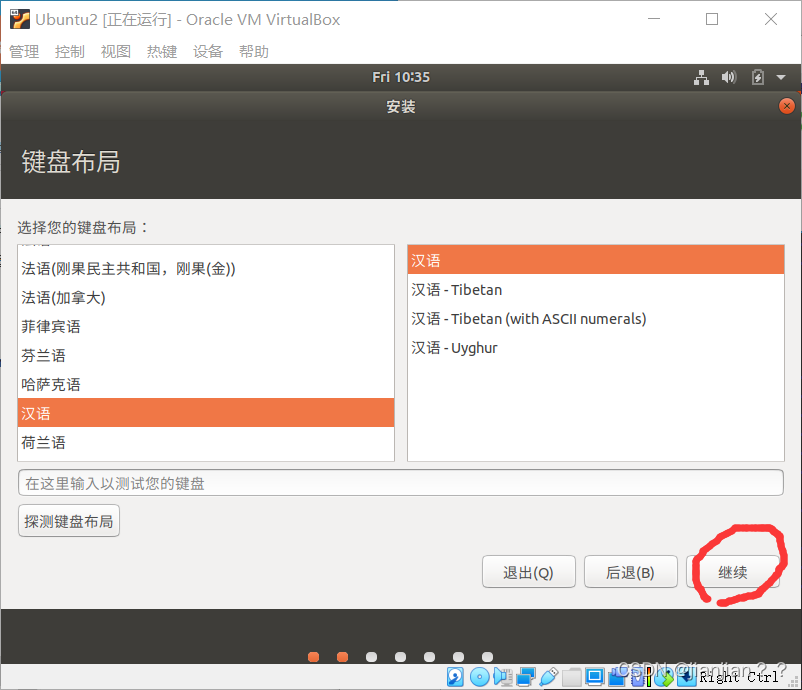
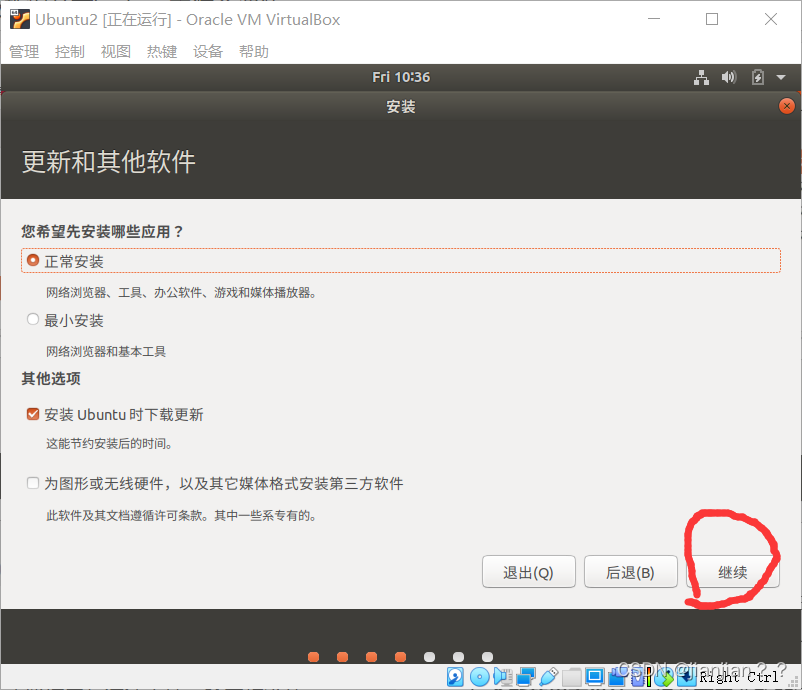
【有条件的可以选择其他选项 自己分区 此处不分区影响不大】

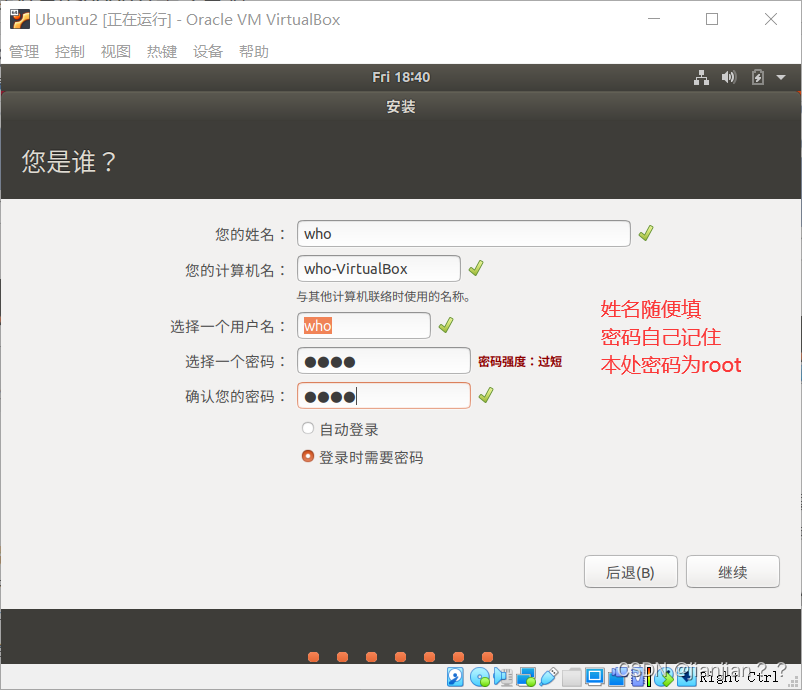
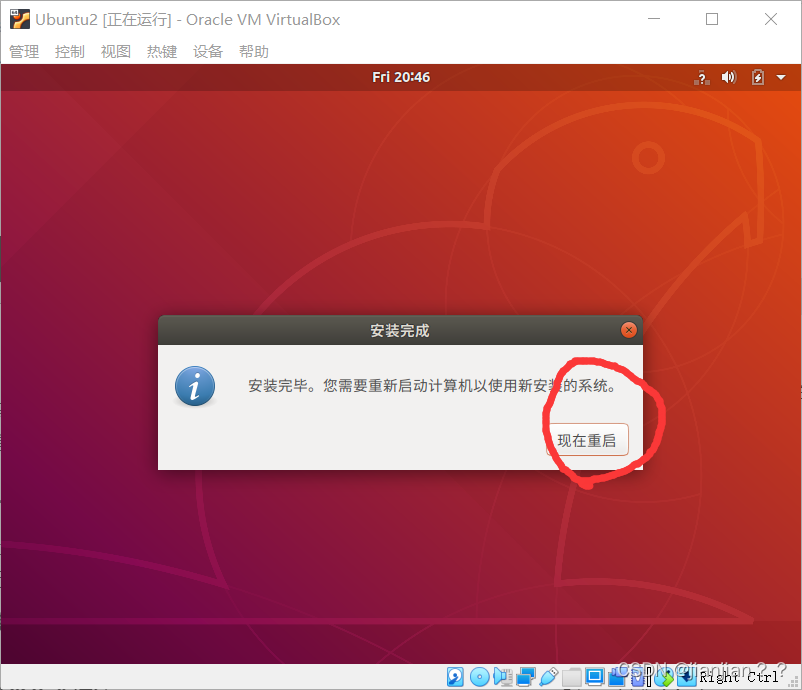
4.创建自己的用户,姓名随便填,密码自己记住,笔者此处密码为root,建议初学者与笔者创建用户一致,方便学习。设置完成后点击继续。安装系统时间可能有点久,可以继续下载百度网盘里的资源,安装好XShell(一路下一步,顶多修改个安装路径,就不讲咋安装了),等会需要。
连接网络和Xshell
连接网络
才安装好的ubuntu系统主机无法访问,并且没有root用户。
而jdk的安装包在我们主机上,因此让主机与虚拟机进行通讯是必要的操作。
1.关闭Ubuntu,进行网络设置,选中虚拟机,点击设置。
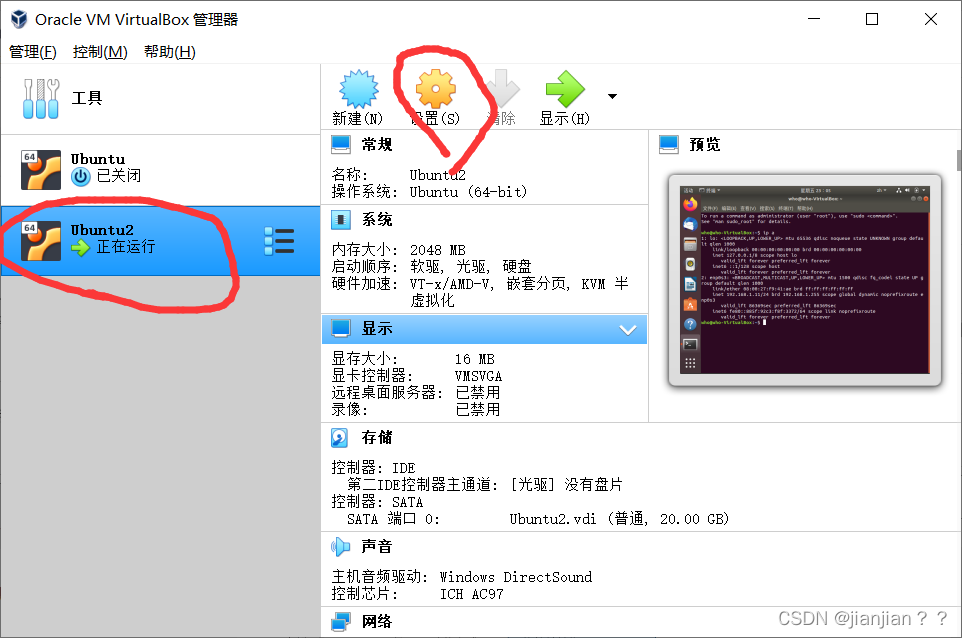
2.点击网络,选择桥接网卡,点击OK,然后再次启动Ubuntu
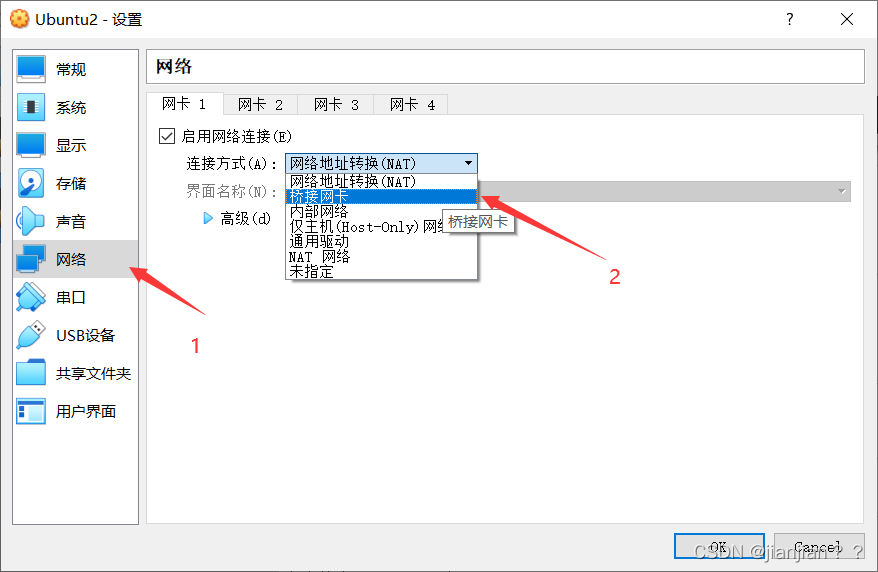
3.输入密码登录成功后,在桌面鼠标右键,点击打开终端。此时可能会弹出询问是否更新,一律不!
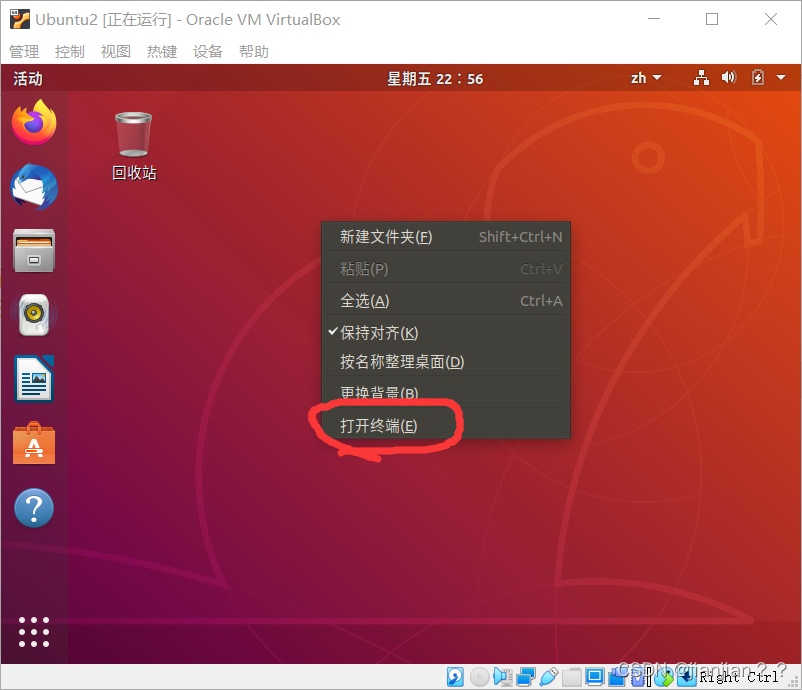
4.输入命令 ip a 可查看ip地址,记住此IP地址!连接XShell需要
ip a
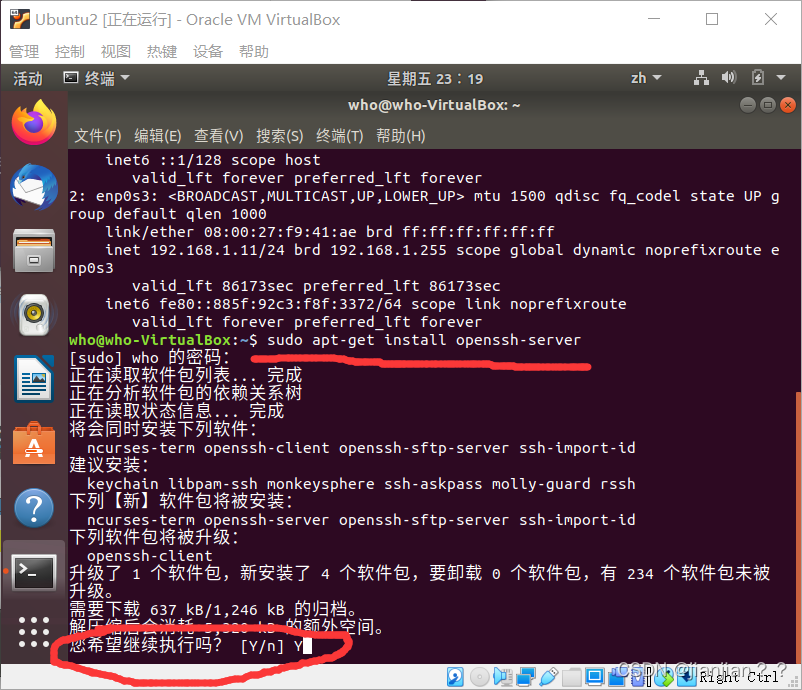
5.安装ssh 输入 sudo apt-get install openssh-server 即可,弹出是否继续执行时输入y。
sudo apt-get install openssh-server
6.配置ssh权限 照着输入就行
ssh localhost #生成~/.ssh/目录 需要输入 一次yes 和一次密码
cd ~/.ssh/ # 若没有该目录,请先执行一次ssh localhost
ssh-keygen -t rsa # 会有提示,都按回车就可以
cat ./id_rsa.pub >> ./authorized_keys # 加入授权
连接XShell
为什么要连接XShell?最主要的原因是笔者的主机和虚拟机之间无法复制粘贴,而XShell可以!当然XShell也还有很多其他的妙用
1.启动XShell,选择文件–新建
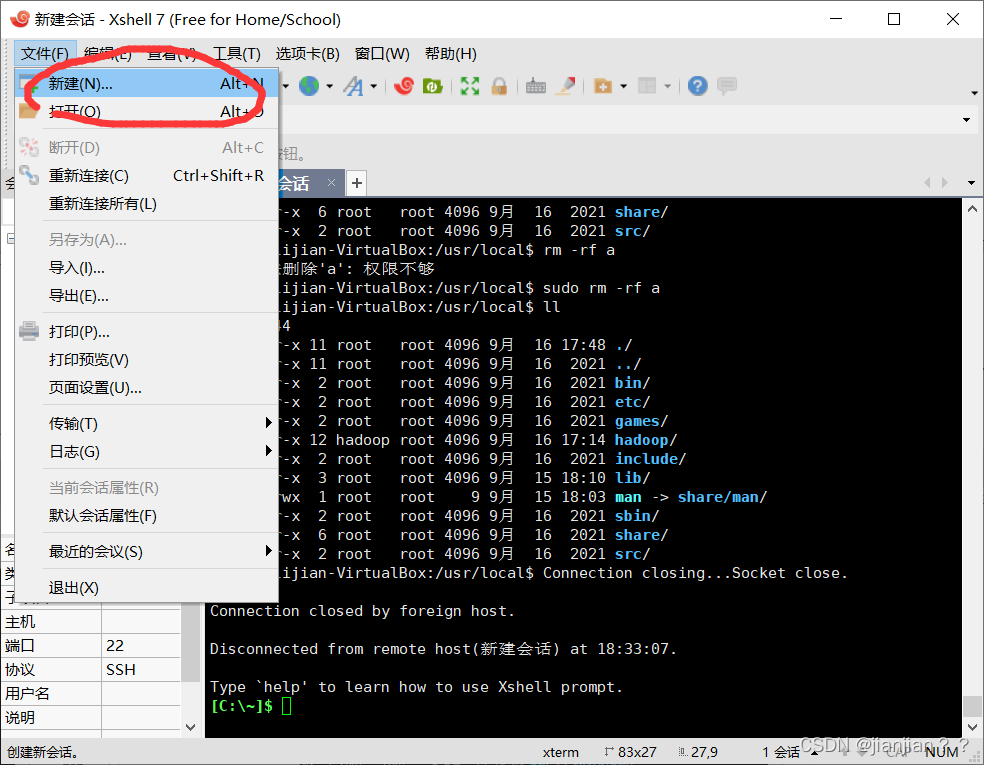
2.设置如下,设置完后点击连接即可
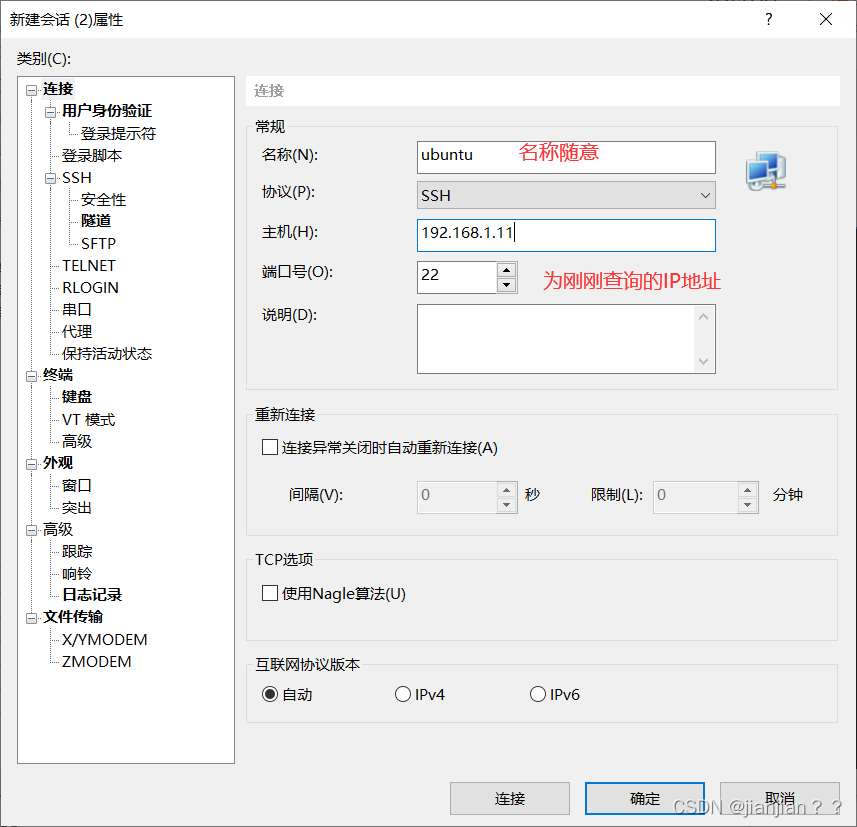
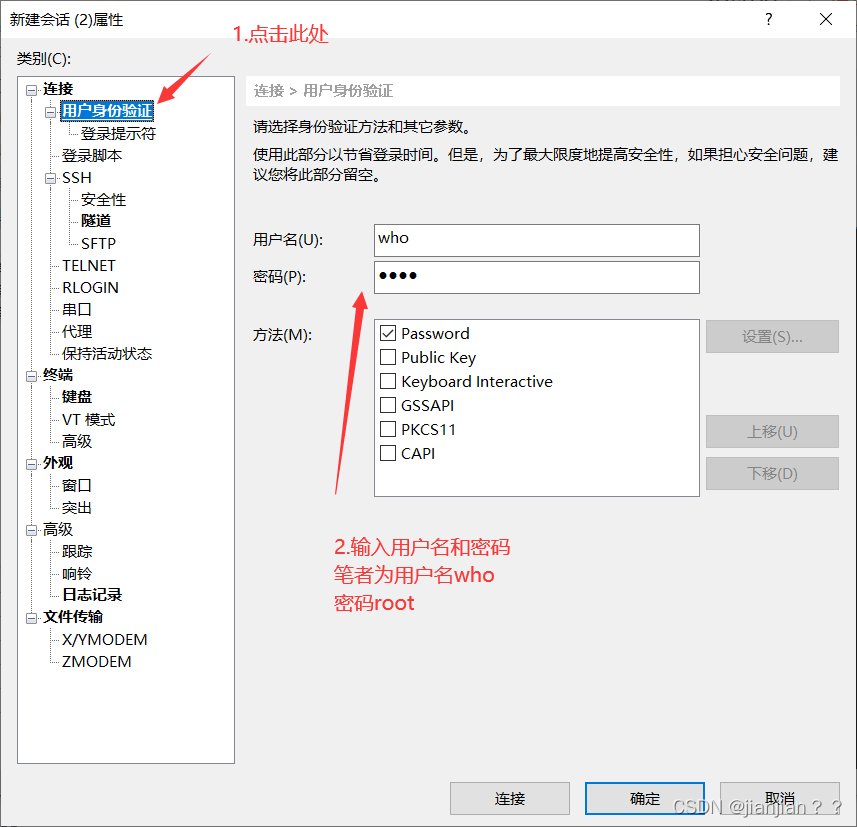
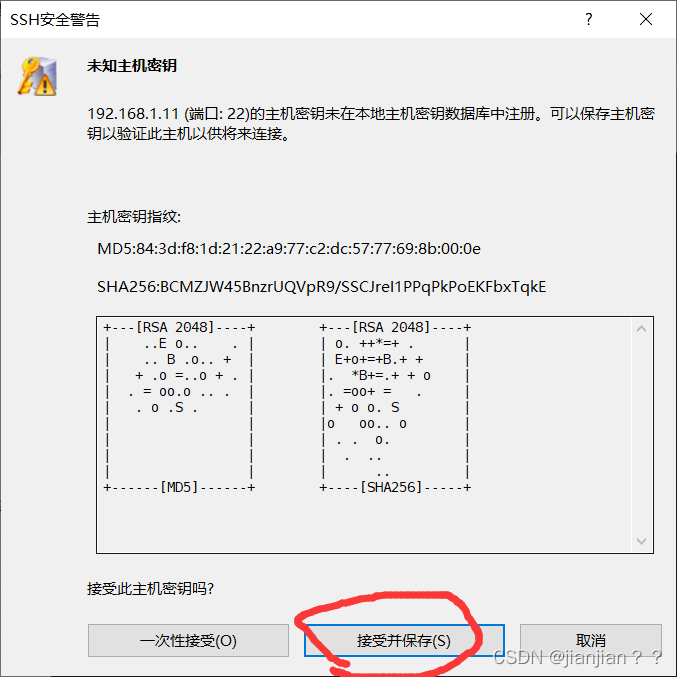
3.接受并保存
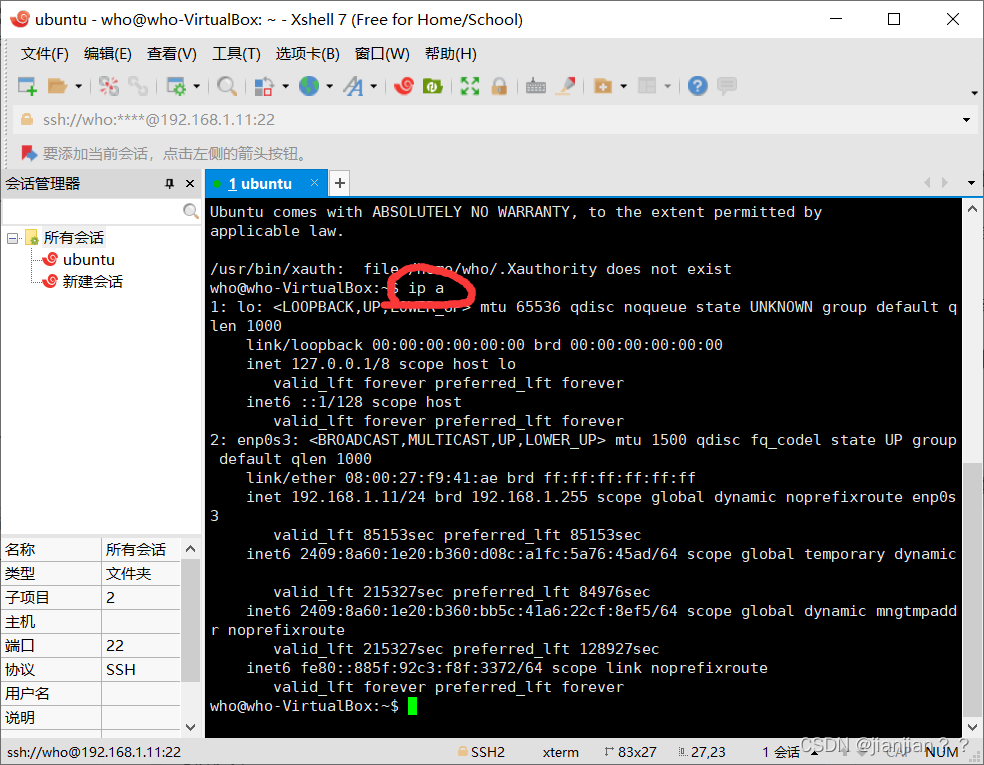
4.现在在XShell中随便输入一条命令,输出结果正确代表连接成功。
环境安装
系统vim安装及其包的上传
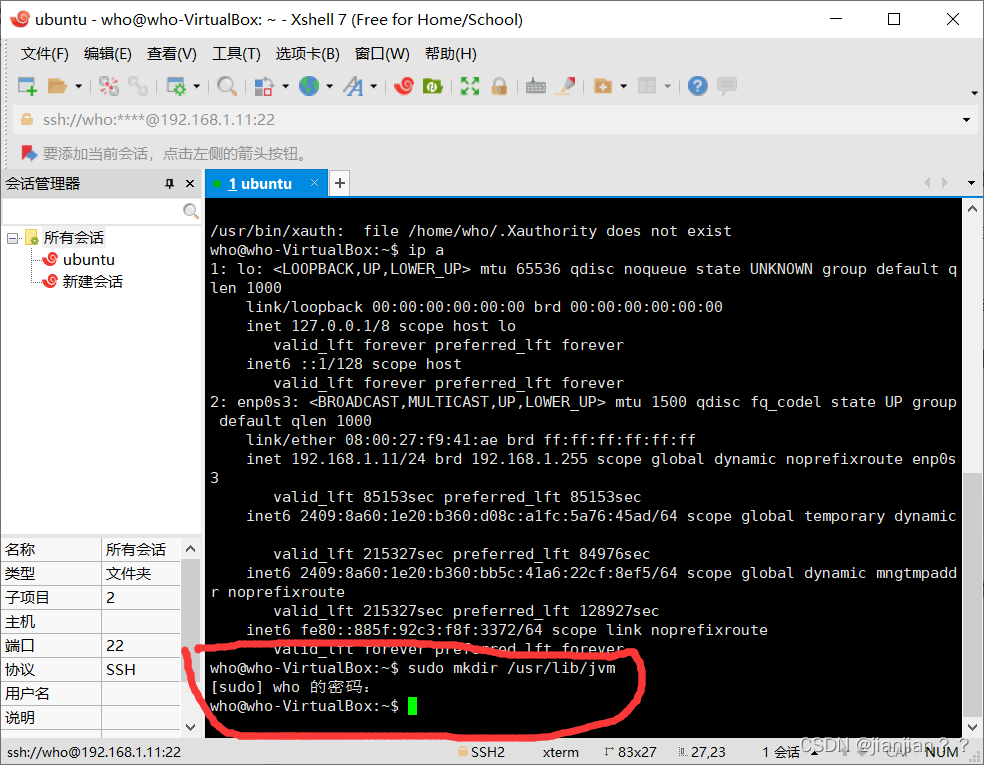
1.先在XShell中建立/usr/lib/jvm目录,用于存放java环境
sudo mkdir /usr/lib/jvm
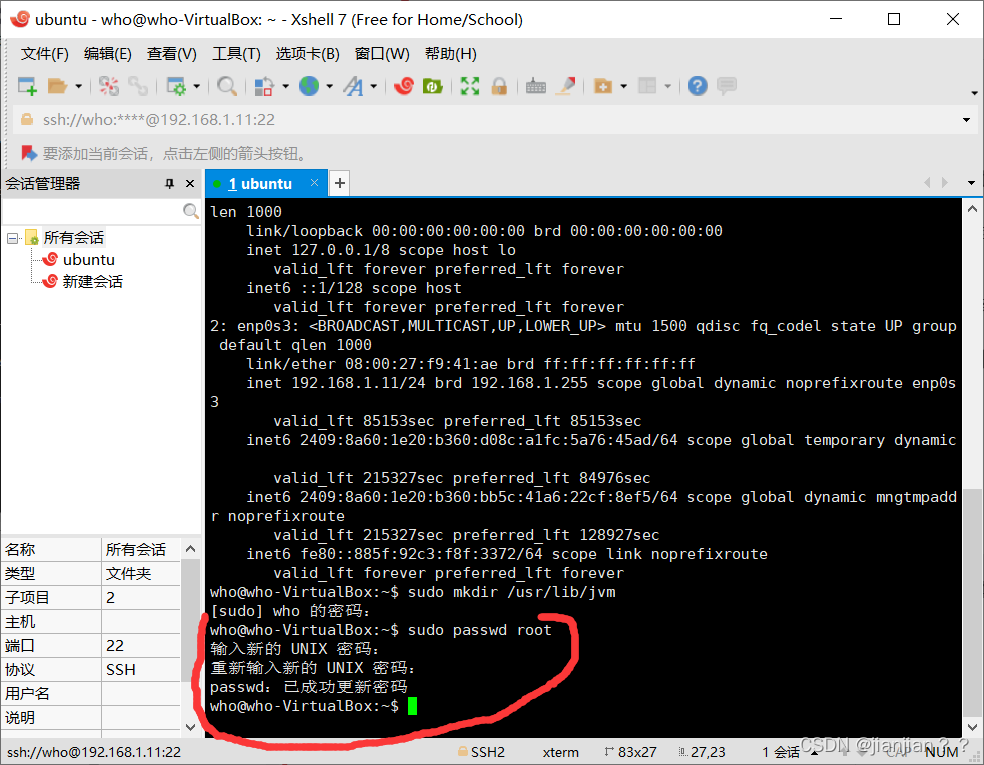
2.设置root账号的密码,笔者设置为的root
sudo passwd root
3.安装vim和更新apt 两行代码,安装vim的时候会有输入提示,输入yes即可
sudo apt-get update
sudo apt-get install vim
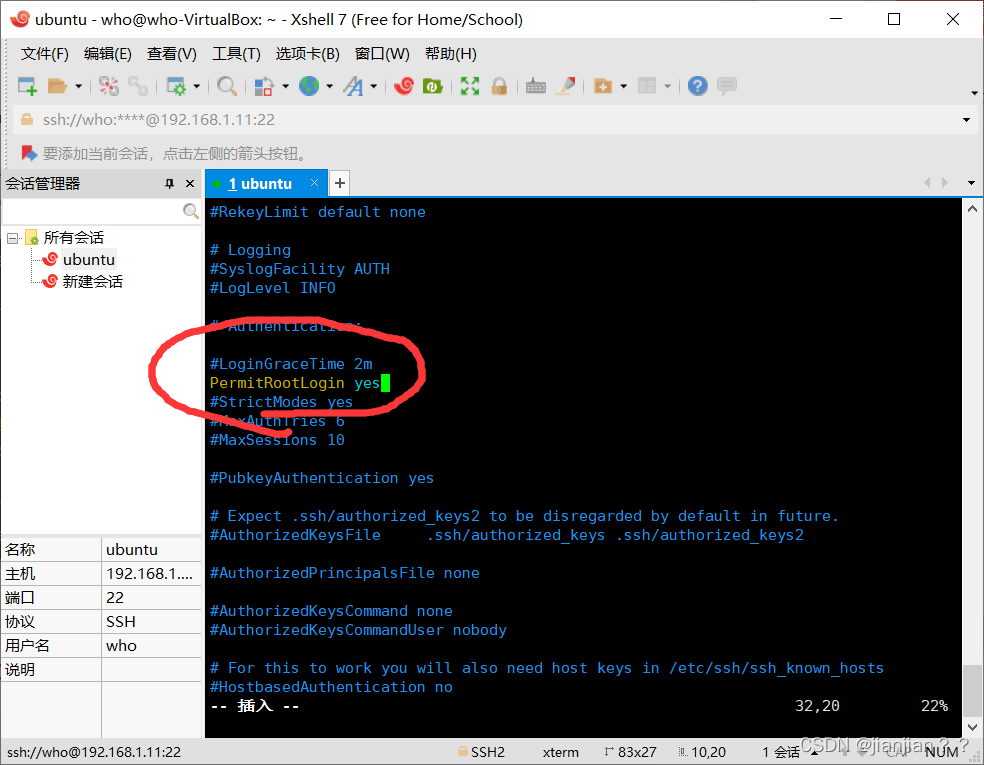
4.将PermitRootLogin 修改为yes,否则scp文件传输会遇到Permission denied, please try again.问题。
sudo vim /etc/ssh/sshd_config #修改sshd_config文件
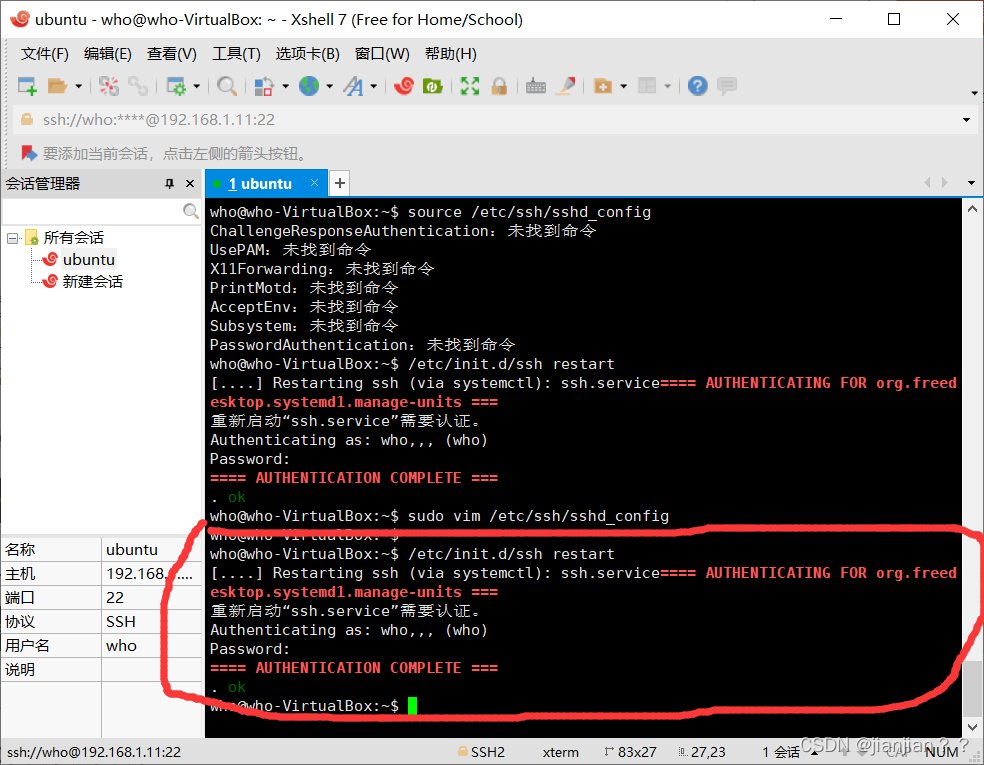
/etc/init.d/ssh restart #重启ssh服务
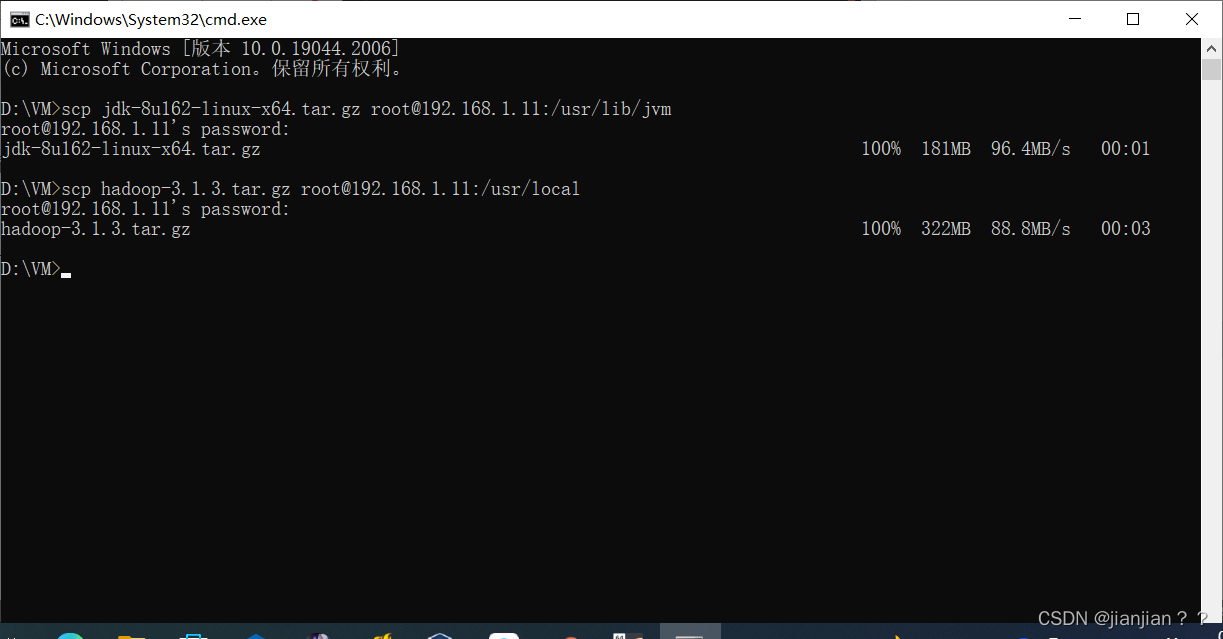
5.将jdk上传到/usr/lib/jvm目录下,将hadoop上传到/usr/local目录下
scp jdk-8u162-linux-x64.tar.gz root@192.168.1.11:/usr/lib/jvm
scp hadoop-3.1.3.tar.gz root@192.168.1.11:/usr/local
安装jdk
cd /usr/lib/jvm #进入jdk包的目录下
sudo tar -zxvf jdk-8u162-linux-x64.tar.gz #解压jdk

vim ~/.bashrc # 进入bashrc添加jdk环境变量
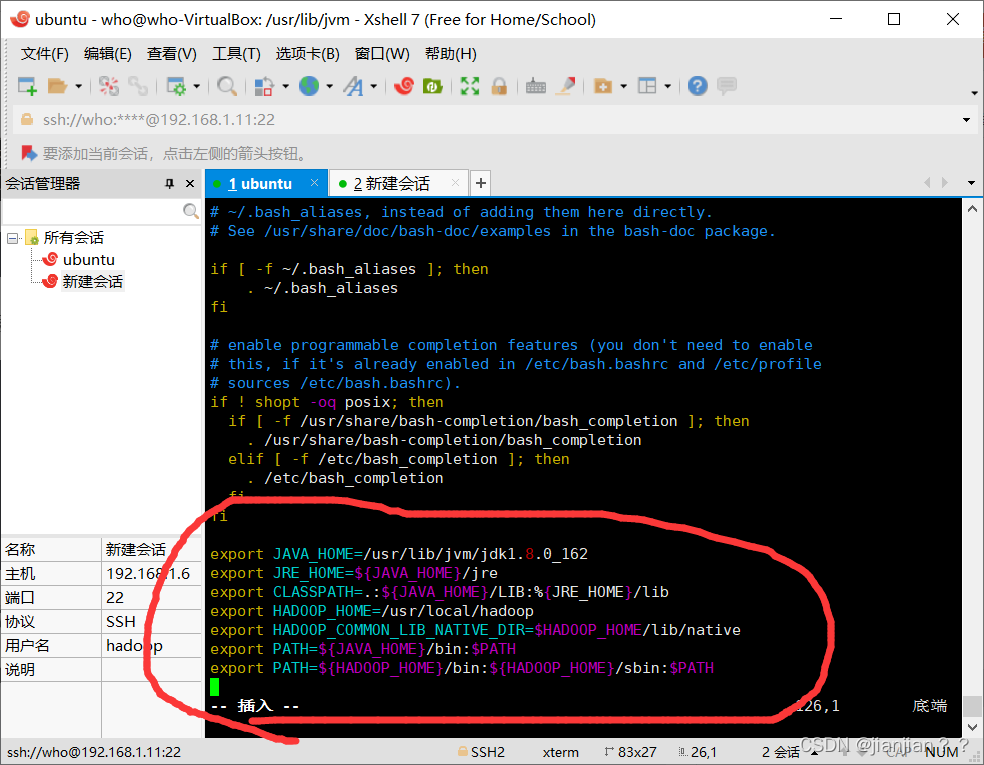
添加的环境变量如下(包含了jdk和hadoop两者的环境变量):
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_162
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/LIB:%{JRE_HOME}/lib
export JAVA_LIBRARY_PATH=/usr/local/hadoop/lib/native
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=${JAVA_HOME}/bin:$PATH
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
退出文件,并重启配置文件
source ~/.bashrc #重启配置文件
输入java -version查看是否配置成功

安装Hadoop
1.进入Hadoop包的安装目录 cd /usr/local
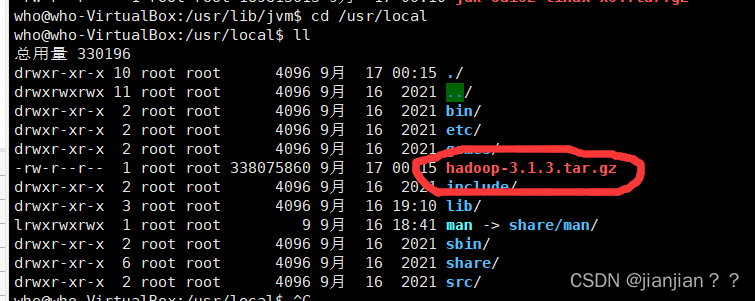
2.sudo tar -zxvf hadoop-3.1.3.tar.gz 进行解压
3.sudo mv hadoop-3.1.3 hadoop重命名hadoop文件名
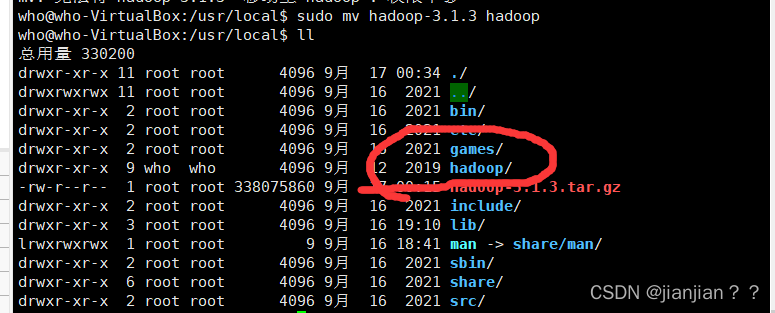
4.配置bashrc中的Hadoop环境变量,在配置jdk时已配置,不重复。未配置的可全局搜索jdk和hadoop两者关键字定位到配置处。
5.查看hadoop信息 如果配置了hadoop环境变量可直接通过./bin/hadoop version命令查询hadoop信息,如果没有配置hadoop环境变量,则需要到安装了hadoop的目录下去执行该命令。
cd /usr/local/hadoop #进入该目录
./bin/hadoop version #查看hadoop版本信息
此时可明确看见hadoop的信息,表示安装成功!
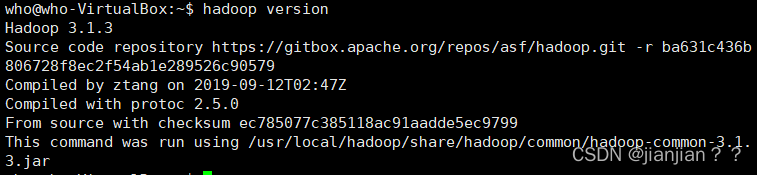
Hadoop单机配置(非分布式)
命令照着敲:
cd /usr/local/hadoop
mkdir ./input
cp ./etc/hadoop/*.xml ./input # 将配置文件作为输入文件
./bin/hadoop jar ./share/hadoop/mapreduce/hadoop-mapreduce-examples-3.1.3.jar grep ./input ./output 'dfs[a-z.]+' #此处为一行代码!!!单独提出来强调
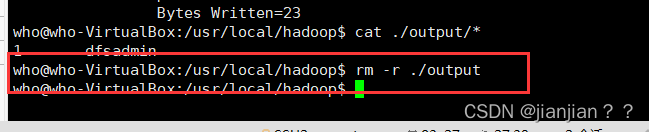
cat ./output/* # 查看运行结果
执行成功后如下所示,输出了作业的相关信息,输出的结果是符合正则的单词 dfsadmin 出现了1次,就代表成功了:
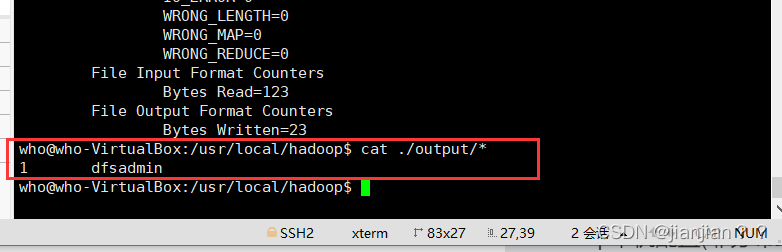
注意,Hadoop 默认不会覆盖结果文件,因此再次运行上面实例会提示出错,需要先执行rm -r ./output将 ./output 删除。
Hadoop伪分布式配置
# 编辑core-site.xml
vim /usr/local/hadoop/etc/hadoop/core-site.xml
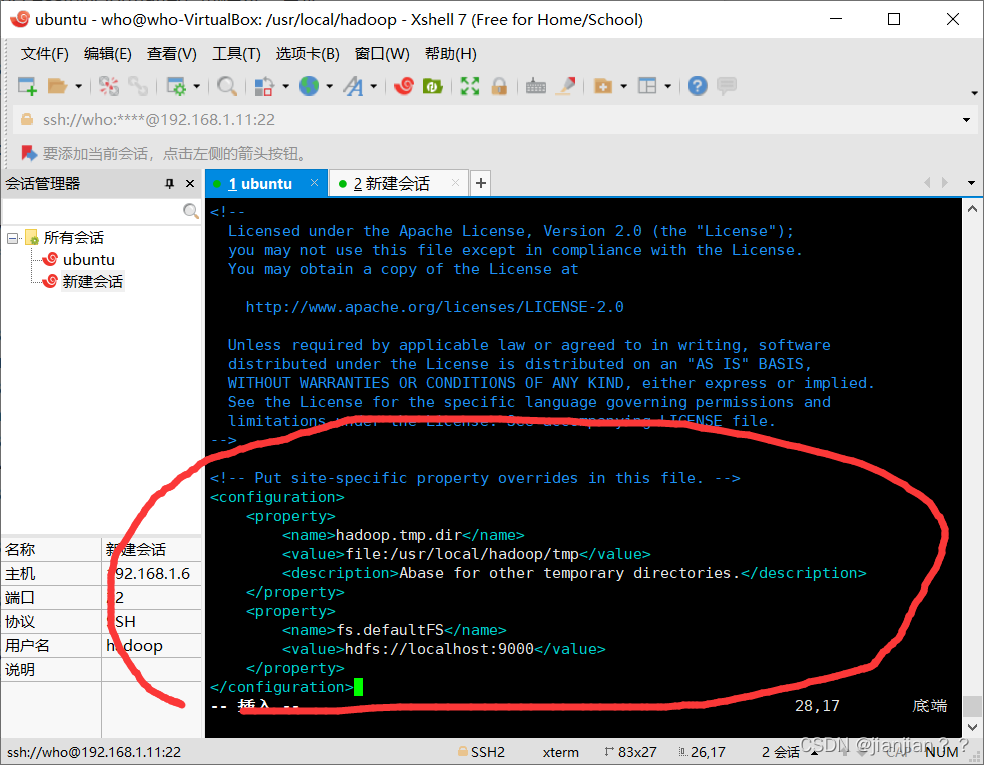
# 将以下的configuration替代掉原本的空configuration
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
替代后:
# 编辑hdfs-site.xml
vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
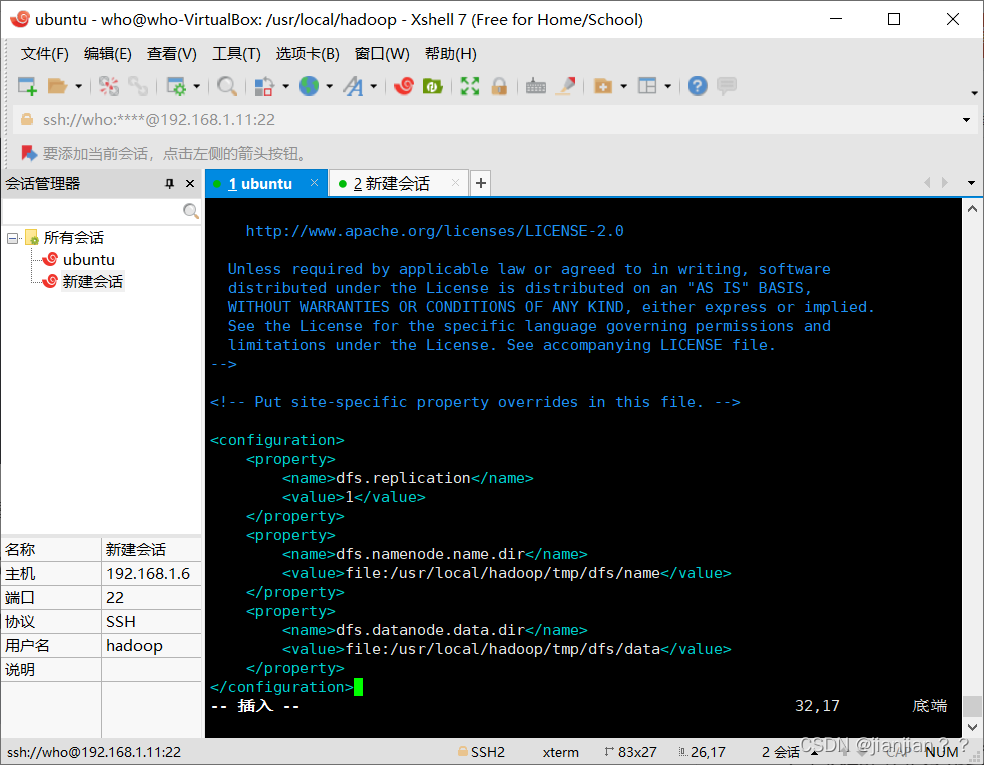
# 将以下的configuration替代掉原本的空configuration
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
替换后:
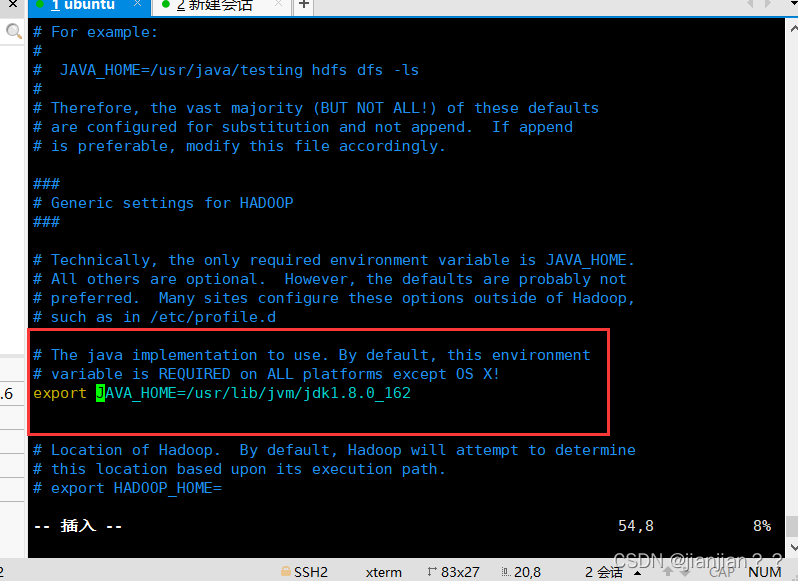
重点:将/usr/local/hadoop/etc/hadoop/hadoop-env.sh文件中的JAVA_HOME修改为绝对地址,否则可能会报JAVA_HOME is not set and could not be found. 的错误。
修改后:
执行 NameNode 的格式化:
cd /usr/local/hadoop #进入该目录
./bin/hdfs namenode -format #进行格式化
最后输入jps命令显示如下代表Hadoop启动成功:
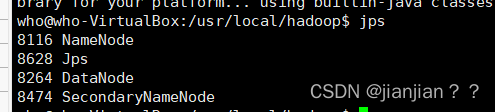
此外,若是 DataNode 没有启动,可尝试如下的方法(注意这会删除 HDFS 中原有的所有数据,如果原有的数据很重要请不要这样做):
# 针对 DataNode 没法启动的解决方法
cd /usr/local/hadoop
./sbin/stop-dfs.sh # 关闭
rm -r ./tmp # 删除 tmp 文件,注意这会删除 HDFS 中原有的所有数据
./bin/hdfs namenode -format # 重新格式化 NameNode
./sbin/start-dfs.sh # 重启
资源提取
链接:https://pan.baidu.com/s/1jM63ylV58Zfy980XUq2FaA?pwd=1111
提取码:1111



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











