




这个学期选了编译原理这门课,还附带一个课程设计,经过几天的鏖战,终于算是告一段落了,下面是我对词法分析器的一些设计,希望可以帮到和我有相同遭遇的博友们……
代码实现:
from tkinter import *
import threading
#预定义的可以分析的各种字符和关键字,依个人需求可进行修改
#运算符
a = ['*', '-', '/', '=', '>', '<', '>=', '=', '<=', '+','<>']
#界符
b = ['(', ')', '"', ';', '!']
#关键字
c = ['long','float','static',
'char','short','switch','int',
'const','if','then','else','for'
,'while','break']
#GUI的实现
def GUI():
root = Tk()
root.title("编译原理课程设计")
root.geometry("350x180+500+300")
lb = Label(root, text="请输入程序文件的绝对地址:")
lb.grid(row=0, column=0)
entry = Entry(root)
entry.grid(row=0, column=1)
btn = Button(root, text="开始分析", fg='black', relief="raised", bd="9")
btn.grid(row=1, column=1)
btn.bind("<Button-1>",
lambda x: xiancheng(entry))
root.mainloop()
#判断是否字符
def IsLetter(Char):
if ((Char >= 'a' and Char <= 'z') or (Char >= 'A' and Char <= 'Z')):
return True
else:
return False
#判断是否是数字
def IsDigit(Char):
if (Char <= '9' and Char >= '0'):
return True
else:
return False
#判断是否是空格
def IsSpace(Char):
if (Char == ' '):
return True
else:
return False
#词法分析的核心算法,将文件中代码按关键字,界符,运算符等进行分离,并把结果以列表形式返回
def fenli(List):
ResultList = []
for String in List:
Letter = ''
letter = ''
index = 0
for Char in String:
if (index < len(String) - 1):
index += 1
if (IsLetter(Char) or IsDigit(Char)):
if (IsLetter(String[index]) or IsDigit(String[index])):
Letter += Char
elif (IsSpace(String[index]) or (String[index] in b) or (
String[index] in a) or (String[index:index + 2] in a)):
Letter += Char
ResultList.append(Letter)
Letter = ''
elif Char in b:
ResultList.append(Char)
elif Char in a:
letter += Char
if (String[index] in a):
letter += String[index]
ResultList.append(letter)
letter = ''
else:
ResultList.append(letter)
letter = ''
elif IsSpace(Char):
pass
return ResultList
#对fenli()方法中返回的列表进行遍历判断,并输出所述类别
def panduan(char):
for i in char:
if i in a:
print("<运算符,"+i+">")
elif i in b:
print("<界符,"+i+">")
elif i in c:
print("<关键字,"+i+">")
elif i.isdigit():
print("<常数,"+i+">")
elif i.isalnum():
print("<标识符," + i + ">")
else:
print("语法错误:"+i+"不是合法字符!!!")
def center(entry):
p=[]
#打开代码文件
with open(entry.get(),'r') as f:
#按行进行读取
m=f.readlines()
#按行进行遍历
for i in m:
#消除每行两边的空格
n=i.strip()
#追加到预定义列表中
p.append(n)
#代码的所有内容传给fenli()方法进行分离
y=fenli(p)
panduan(y)
def xiancheng(entry):
# 创建一个线程
t = threading.Thread(
target=center, args=(entry,))
# 设置守护线程,主线程退出不用等待子线程完成
t.setDaemon(True)
# 开始
t.start()
if __name__=="__main__":
GUI()
运行效果图:
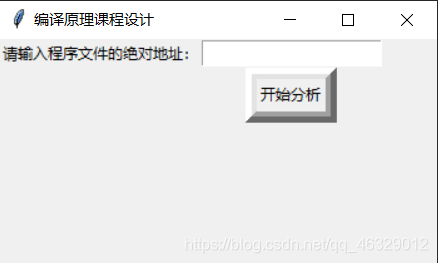
输出结果截图:
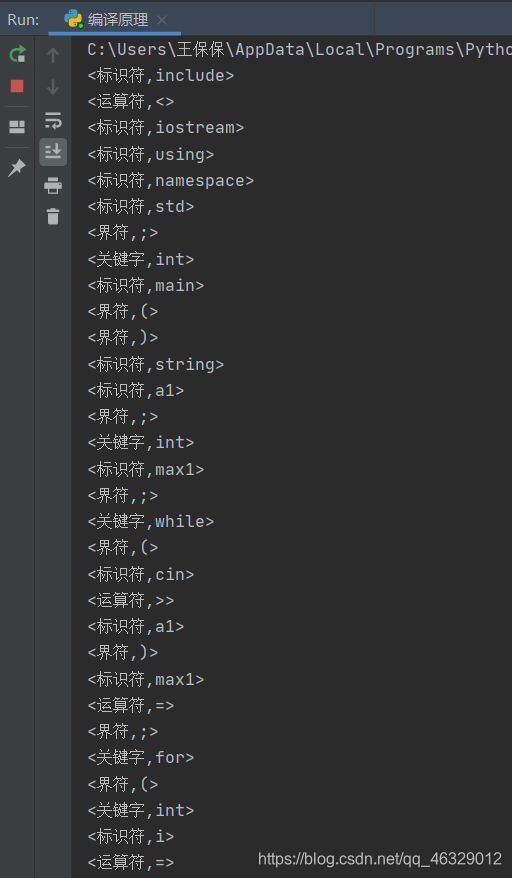
以上就是WBB对词法分析器的设计,如果有帮助到各位博友记的点赞加关注吧!!!



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











