




 该博客深入探讨了GBDT(梯度提升决策树)中的CART树构造过程,包括在回归和分类问题中的应用。对于回归问题,GBDT通过拟合残差来构建树;而在分类问题中,利用Softmax处理概率映射,迭代拟合概率差值。内容涉及特征选择、损失函数最小化和树的构建策略,并阐述了预测阶段的实现。
该博客深入探讨了GBDT(梯度提升决策树)中的CART树构造过程,包括在回归和分类问题中的应用。对于回归问题,GBDT通过拟合残差来构建树;而在分类问题中,利用Softmax处理概率映射,迭代拟合概率差值。内容涉及特征选择、损失函数最小化和树的构建策略,并阐述了预测阶段的实现。
多分类实例
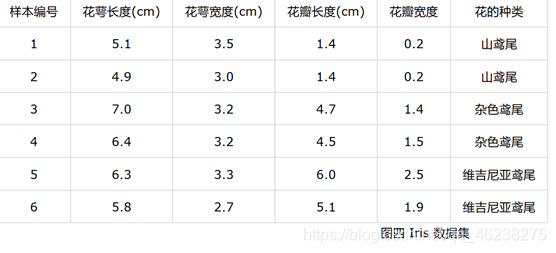
[1,0,0] 表示样本属于山鸢尾,[0,1,0] 表示样本属于杂色鸢尾,[0,0,1] 表示属于维吉尼亚鸢尾。
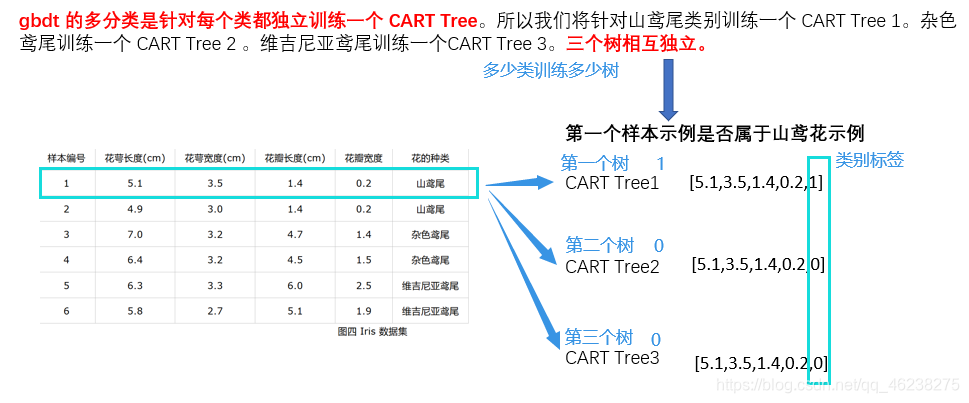
Cart Tree1生成过程
遍历所有样本对应的所有特征,找其最好的切分条件给其分成树
考虑问题:
1.是哪个特征最合适? 2.是这个特征的什么特征值作为切分点?
举例:
构建第一棵树时,首先遍历到花萼长度,遍历到5.1,假如以5.1作为切分点,小于5.1为一类,大于等于5.1为一类
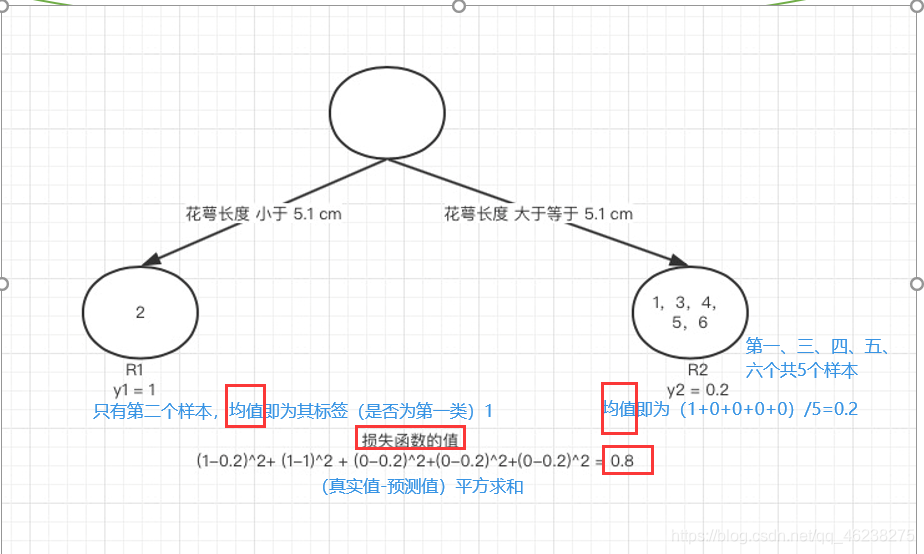 y1 为 R1 所有样本的label 的均值 1/1=1。y2 为 R2 所有样本的label 的均值(1+0+0+0+0)/5=0.2
y1 为 R1 所有样本的label 的均值 1/1=1。y2 为 R2 所有样本的label 的均值(1+0+0+0+0)/5=0.2
随后,遍历到花萼长度特征的第二个样本的值4.9
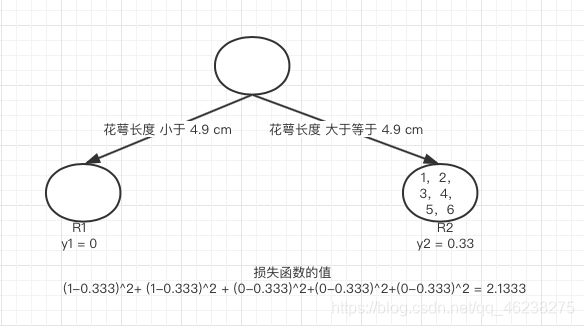
显然,以4.9切分,其损失值大于特征一的第一个特征值的损失值-舍弃;之后依次遍历,找出最小的损失值对应的切分方式来构建cart tree1,cart tree2、cart tree3 类同
Cart Tree的预测函数
GBDT累加时累加的是f(x),因此需要对每个树进行表达f(x) 举例
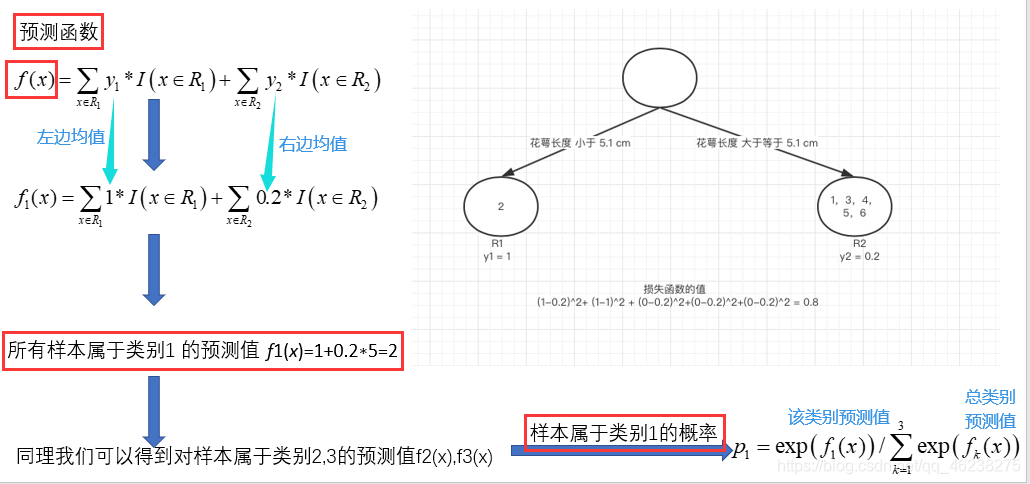
有了类别概率后即可进行迭代

GBDT用于回归时使用CART回归树,每次对残差(负梯度)进行拟合。而分类问题要怎么每次对残差拟合?
分类问题:类别相减没有意义。因此,可以用Softmax进行概率的映射,然后每轮拟合概率的残差,不断迭代。
如实际是A类,但构建树预测其是A类的概率为0.8,故下次要拟合概率差值0.2
回归案例
数据
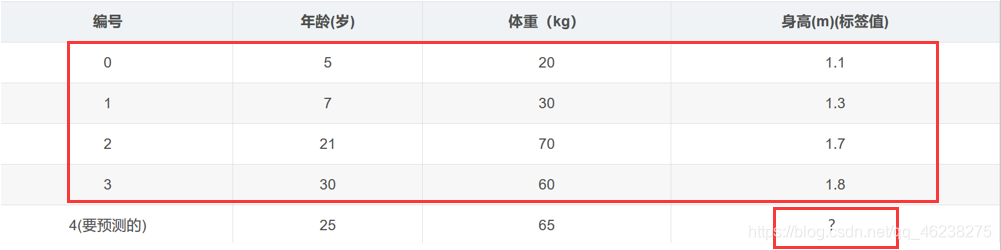
训练

1.初始化弱学习器

2.迭代轮数m=1,2…,M n_trees=5 所以M=5

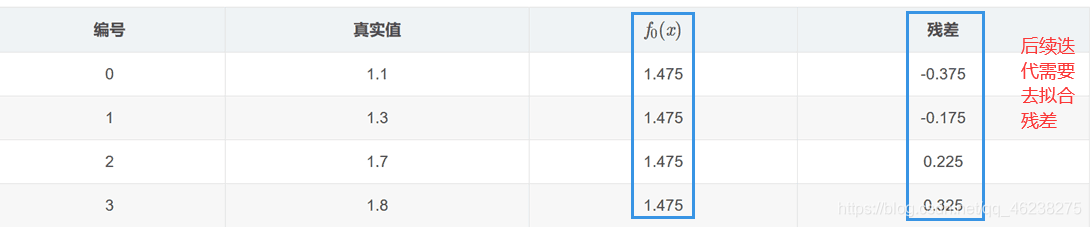
将残差作为样本的标签值来训练弱学习器f1(x)
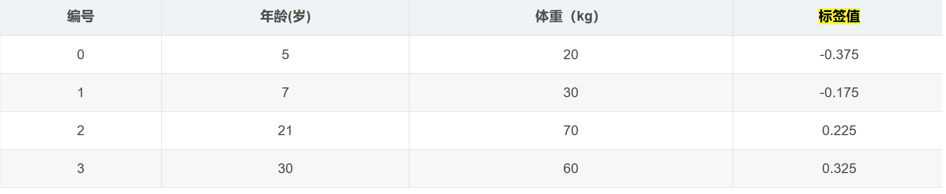
寻找回归树的最佳划分节点,遍历每个特征的每个可能取值,从年龄特征的5开始,到体重特征的70结束,分别计算分裂后两组数据的平方损失。
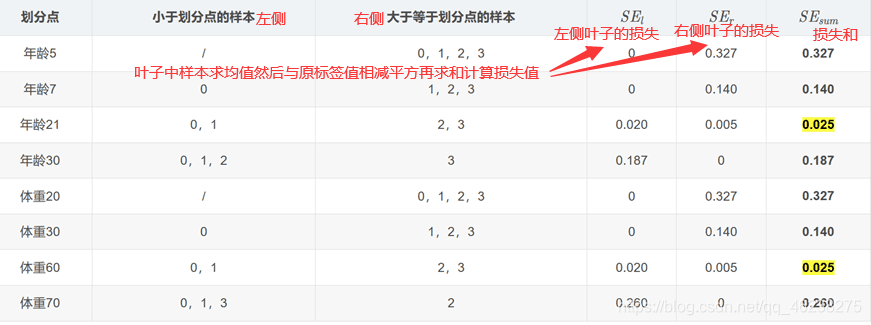
寻找总平方损失最小为0.025有两个划分点:年龄21和体重60,所以随机选一个作为划分点
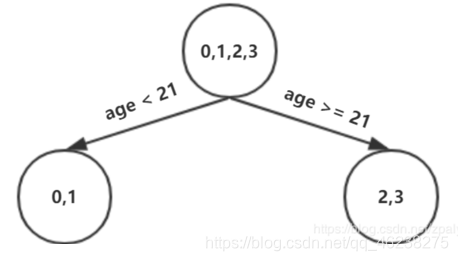
设置的参数中树的深度max_depth=3,现在树的深度只有2,需要再进行一次划分。这次划分要对左右两个节点分别进行划分:
即重复上述过程,对左节点中样本0,1继续划分;对右节点中样本2,3继续划分
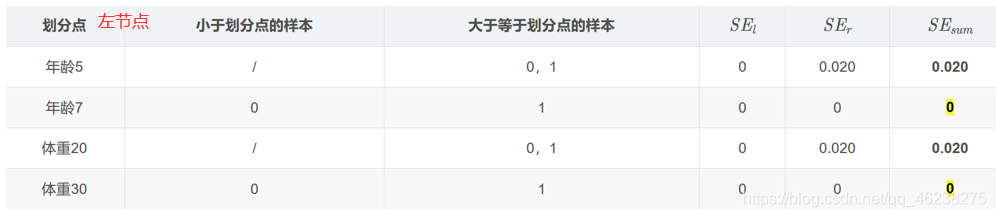
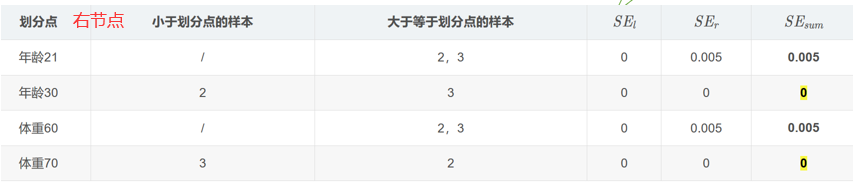
从而构造第一棵树
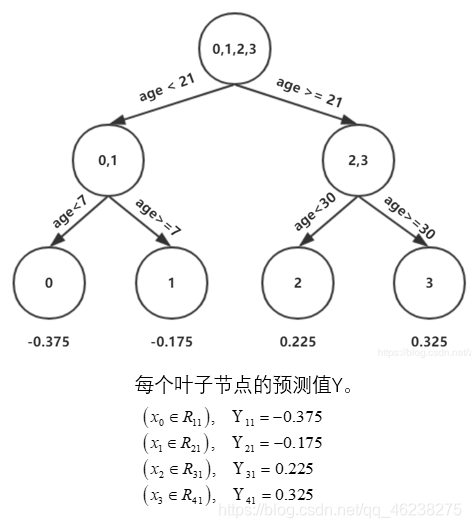
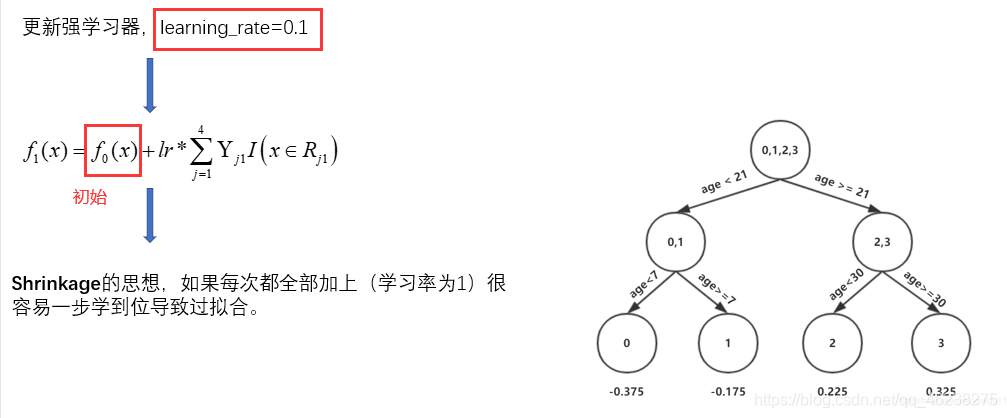
设置学习率-防止过拟合
迭代建树
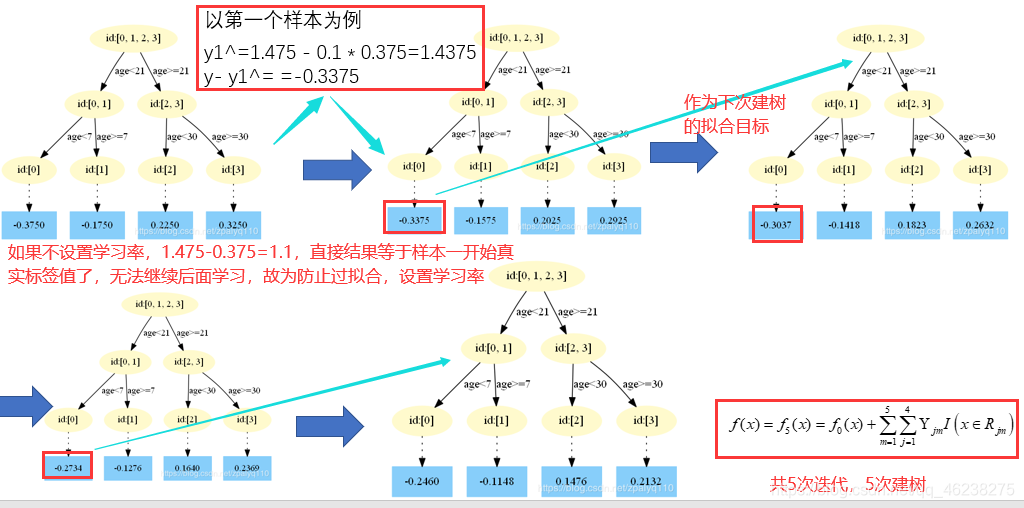
预测阶段

利用上面样本建立好的树来进行预测


















 695
695

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









