本章介绍另一种内置类型--元组 , 并展示列表 , 字典和元组三者如何一起工作 .
我还会介绍一种很有用的可变长参数列表功能 : 收集操作符和分散操作符 .
请注意 : 元组 ( tuple ) 这个词的读音并没有统一的标准 .
有些人会读成 'tuh-ple' , 与 'supple' 同音 ,
但在程序设计界 , 大多数人都读作 'too-ple' , 与 'quadruple' 同音 .
元组是值的一个序列 . 其中的值是可以任意类型 , 并且按照整数下标索引 , 所以从这方面看 , 元组和列表很像 .
元组和列表之间的重要区别是 , 元组是不可变的 .
语法上 , 元组就是用逗号分隔的一列值 :
>> > t = 'a' , 'b' , 'c' , 'd' , 'e'
>> > t
( 'a' , 'b' , 'c' , 'd' , 'e' )
虽然并不需要 , 但元组常常用括号括起来 :
>> > t = '(a' , 'b' , 'c' , 'd' , 'e' )
>> > t
( 'a' , 'b' , 'c' , 'd' , 'e' )
若要新建只包含一个元素的元组 , 需要在后面添加一个逗号 :
>> > t1 = 'a' ,
>> > type ( t1)
< class 'tuple' >
而用括号括起来的单独的值并不是元组 :
>> > t2 = ( 'a' )
>> > type ( t2)
< class 'str' >
新建元组的另一种形式是使用内置函数tuple . 不带参数时 , 它会新建一个空元组 :
>> > t = tuple ( )
>> > t
( )
如果参数是一个序列 ( 字符串 , 列表或者元组 ) , 结果就是一个包含序列的元素的元组 :
>> > t = tuple ( 'lupins' )
>> > t
( 'l' , 'u' , 'p' , 'i' , 'n' , 's' )
因为tuple是内置函数的名称 , 所以应当避免用它作为变量名称 .
大多数列表操作也可以用于元组 . 方括号操作符可以用下标取得元素 :
>> > t + ( 'a' , 'b' , 'c' , 'd' , 'e' )
>> > t[ 0 ]
'a'
而切片操作符选择一个范围内的元素 :
>> > t[ 1 : 3 ]
( 'b' , 'c' )
但如果尝试修改元组的元素 , 会得到错误 :
>> > t[ 0 ] = 'A'
Traceback ( most recent call last) :
File "<stdin>" , line 1 , in < module>
TypeError: 'tuple' object does not support item assignment
类型错误: 'tuple' 对象不支持项分配
由于元素是不可变的 , 所以不能修改它的元素 . 但是可以将一个元组替换为另一个 :
>> > t = ( 'A' , ) + t[ 1 : ]
>> > t
( 'A' , 'b' , 'c' , 'd' , 'e' )
这条语句生成新元组 , 然后使t引用它 .
关系运算符适用于元组和其他序列 . Python从比较两个序列的第一个原始 .
如果他们相等 , 它就继续比较下一个元素 , 以此类推 , 直到它找到不同的元素为止 .
子序列元素不在考虑之列 ( 尽管它们实际上很大 ) .
子序列 : 是指原序列中取出若干个元素 , 些元素在原序列中的相对顺序保持不变 .
换句话说 , 子序列是原序列中任意个连续元素的组合 , 不要求这些元素在原序列中是相邻的 .
例如 , 序列 [ 1 , 2 , 3 , 4 ] 的子序列包括 [ 1 , 2 ] , [ 1 , 3 ] , [ 2 , 4 ] , [ 1 , 2 , 3 ] , [ 2 , 3 , 4 ] 等等 .
在比较序列相等性时,子序列元素不会被考虑在内。例如,对于以下两个列表:
list1 = [ 1 , 2 , 3 , 4 , 5 ]
list2 = [ 1 , 2 , 7 , 8 , 9 ]
使用关系运算符比较list1和list2时m Python会从第一个元素开始比较 , 发现第一个元素相同 ,
然后继续比较第二个元素 , 发现也相同 , 但当比较第三个元素时 , 发现它们不同 ,
此时Python停止比较并返回False .
注意 , list1中的子序列 [ 3 , 4 , 5 ] 和list2中的子序列 [ 7 , 8 , 9 ] 并没有被比较 .
>> > ( 0 , 1 , 2 ) < ( 0 , 3 , 4 )
True
>> > ( 0 , 1 , 2000 ) < ( 0 , 3 , 4 )
True
交换两个变量的值常常很有用 . 使用传统的赋值方式 , 需要使用一个临时变量 .
例如 , 要交换a和b :
>> > temp = a
>> > a = b
>> > b = temp
这汇总解决方案很笨拙 , 而 '元组赋值' 则更优雅 :
>> > a, b = b, a
左边是一个变量的元组 , 右边是表达式的元组 . 每个值会被赋值给相应的变量 .
右边所以的表达式 , 都会在任何赋值操作进行之前完成求值 .
左边变量的个数和右边值的个数必须相同 :
>> > a, b = 1 , 2 , 3
. . .
ValueError: too many values to unpack ( expected 2 )
更通用地 , 右边可以是任意类型的序列 ( 字符串 , 列表或元组 ) .
例如 , 想要将电子邮件地址拆分成用户和域名 , 可以这么写 :
>> > addr = 'monty@python.org'
>> > uname, domain = addr. split( '@' )
split返回两个元素的列表 ; 第一个元素被赋值到uname , 第二个到domain上 .
>> > uname
'monty'
>> > domain
'python.org'
严格地说 , 函数只返回一个值 , 但如果返回值是元组的话 , 效果和返回值差不多 .
例如 , 如果将两个整数相除 , 得到商和余数 , 那么先计算x / y再计算x % y并不高效 .
更好地方法是同时计算它们 . 内置函数divmod接收两个参数 , 并返回两个值的元组 , 即商和余数 .
可以将结果存为一个元组 :
>> > t = divmod ( 7 , 3 )
>> > t
( 2 , 1 )
或者可以使用元组赋值来分别存储结果中的元素 :
>> > quot, rem = divmod ( 7 , 3 )
>> > quot
2
>> > rem
1
下面是返回一个元组的函数的示例 :
def min_max ( t) :
return min ( t) , max ( t)
max和min都是内置函数 , 分别返回一个序列的最大值和最小值 .
min_max_计算这两个值并将它们作为一个元组返回 .
函数可以接收不定个数的参数 .
以 * 开头的参数名会 '收集' ( gather ) 所有的参数 ( 位置实参 ) 到一个元组上 .
例如 , printall接收任意个数的参数并打印它们 :
def printall ( * args) :
print ( args)
可变长参数元组是指在函数定义时 , 使用 * args这样的语法 ,
表示接受任意数量的位置参数 , 并将它们收集成一个元组 .
收集参数可以使用任何你想要的名称 , 但按照惯例通常使用args .
下面是函数如何工作的一个例子 :
>> > printall( 1 , 2.0 , '3' )
( 1 , 2.0 , '3' )
收集的反面是 '分散' ( scatter ) .
如果有一个序列的值 , 而想将它们作为可变长参数传入到函数中 , 可以使用 * 操作符 .
例如 , divmod正好接收两个参数 , 但它不接收元组 :
>> > t = ( 7 , 2 )
>> > divmod ( t)
. . .
TypeError: divmod expected 2 arguments, got 1
类型错误:divmod 需要2 个参数,得到1 个
但如果将元组分散 , 就可以使用了 :
>> > divmod ( * t)
( 2 , 1 )
在函数调用中使用 * t将元组分散成单独的元素 7 , 3 , 然后作为可变长参数传递给divmod函数 .
很多内置函数使用可变长参数元组 .
例如 , max和min都可以接收任意个数的参数 :
>> > max ( 1 , 2 , 2 )
3
但是sum并不是这样 :
>> > sum ( 1 , 2 , 3 )
. . .
TypeError: sum ( ) takes at most 2 arguments ( 3 given)
类型错误: sum ( ) 最多接受2 个参数( 给定3 个)
作为练习 , 编写一个函数sumall , 接收任意个数的参数并返回它们的和 .
将多个参数作为可变长参数 , 可以将它们作为一个元组传递给函数 .
使用 * args来定义可变长参数 , 这意味着你可以将任意数量的参数收集为一个元组 , 再传递给函数 .
def sumall ( * args) :
count = 0
for i in args:
count += i
return count
print ( sumall( 1 , 2 , 3 , 4 ) )
list1 = [ 1 , 2 , 3 , 4 ]
print ( sumall( * list1) )
zip是一个内置函数 , 接收两个或多个序列 , 并返回一个元组列表 ( 列表的元素全是元组 ) .
每个元组包含来自每个序列中的一个元素 .
这个函数的名字取自拉链 ( zipper ) , 它可以将两行链牙交替连起来 .
下面的例子将字符串和一个列表 '拉' 到一起 :
>> > s = 'abc'
>> > t = [ 0 , 1 , 2 ]
>> > zip ( s, t)
< zip object at 0x00000149FD7D72C0 >
结果是一个zip对象 , 它知道如何遍历每个元素对 . 使用zip最常用的方式是在for循环中 :
>> > for pair in zip ( s, t) :
. . . print ( pair)
. . .
( 'a' , 0 )
( 'b' , 1 )
( 'c' , 2 )
zip对象是一种迭代器 , 即用来迭代访问一个序列的对象 .
迭代器与列表有些方面相似 , 但与列表不同的是 , 迭代器不能使用下标来选择对象 .
如果需要使用列表的操作符和方法 , 可以利用zip对象制作一个列表 :
>> > list ( zip ( s, t) )
[ ( 'a' , 0 ) , ( 'b' , 1 ) , ( 'c' , 2 ) ]
结果是一个由元组组成的列表 .
在本例中 , 每个元组包含字符串中的一个字符 , 以及列表中对应的资格元素 .
如果序列之间的长度不同 , 则结果的长度是多有序列中最短的那个 :
>> > list ( zip ( 'Anne' , Elk) )
[ ( 'A' , 'E' ) , ( 'n' , 'l' ) , ( 'n' , 'k' ) ]
可以在for循环中使用元组赋值来访问元组的列表 ( 确切说是值 ) :
t = [ ( 'a' , 0 ) , ( 'b' , 1 ) , ( 'c' , 2 ) ]
for letter, number in t:
print ( number, letter)
每次循环中 , Python选择列表中的下一个元组 , 并将其元素赋值给letter和number变量 .
这个循环的输出如下 :
0 a
1 b
2 c
如果组合使用zip , for循环以及元组赋值 , 可以得到一种有用的模式 , 用于同时遍历两个或更多的序列 .
例如 , has_match函数接收两个序列 , t1和t2 , 并当存在一个下标i保证t1 [ i ] = = t2 [ i ] 时返回True :
def has_match ( t1, t2) :
for x, y in zip ( t1, t2) :
if x == y:
return True
return False
如果需要遍历列表中的元素以及他们的下标 , 可以使用内置函数enumerate :
for index, element in enumerate ( 'abc' ) :
print ( index, element)
这个枚举的结果是一个枚举对象 , 这个对象迭代一个对序列 ,
在这个例子中 , 每个对都含一个下标 ( 从 0 开始 ) 和一个来自给定序列的元素 , 输出结果还是 :
0 a
1 b
2 c
字典有一个items方法可以返回一个元组的序列 , 其中每个元组是一个键值对 :
>> > d = { 'a' : 0 , 'b' : 1 , 'c' : 2 }
>> > t = d. items( )
>> > t
dict_items( [ ( 'a' , 0 ) , ( 'b' , 1 ) , ( 'c' , 2 ) ] )
结果是一个dict_item对象 , 它是一个迭代器 , 可以迭代访问每一个键值对 .
可以使用for循环来访问 :
>> > for key, value in d. items( ) :
. . . print ( key, value)
. . .
0 a
1 b
2 c
和预料中一样 , 字典中的项是没有特定顺序的 .
从反方向出发 , 可以使用一个元组列表来初始化一个新的字典 :
>> > t = [ ( 'a' , 0 ) , ( 'b' , 1 ) , ( 'c' , 2 ) ]
>> > d = dict ( t)
>> > d
{ 'a' : 0 , 'b' : 1 , 'c' : 2 }
组合使用dict和zip可以得到一个简洁的创建字典的方法 :
>> > d = dict ( zip ( 'abc' , range ( 3 ) ) )
>> > d
{ 'a' : 0 , 'b' : 1 , 'c' : 2 }
字典方法update也接收一个元组列表 , 并将它们作为键值对添加到一个已有的字典中 .
使用元组作为字典的键很常见 ( 主要是因为不能使用列表 ) .
例如 , 一个电话号码簿可能需要将姓名对映射到电话号码 .
假设定义last , first和number , 可以这么写 :
directory = [ last, first] = number
在方括号中表达式是一个元组 . 我们也可以使用元组赋值来遍历这个字典 :
for last, first in directory:
print ( first, last, directory[ first, last] )
这个循环遍历字典directory的所有键 , 它们都是元组 .
它将每一个元组的元素赋值给last和first , 接着打出名字以及对应的电话号码 .
在状态图中有两种方法可以表达元组 . 更详细的版本和列表一样 , 显示索引和元素 .
例如 , 元组 ( 'clesse' , 'john' ) 可以如下图所示 .
但是在更大的图中你可能希望省略掉细节 . 例如 , 整个电话薄的图如下所示 .
这里元组使用Python的语法最为图形化的简写展示 .
这张图里的电话号码是BBC的投诉热线 , 所以请不要真去拨打它 .
我一直在聚焦于元组和列表 , 但本章中几乎所有的示例都可以对列表的列表 , 元组的元组 , 以及列表的元组使用 .
为了避免枚举所有的可能组合 , 有时候直接说序列的序列更简单 .
很多环境中 , 不同类型的序列 ( 字符串 , 列表 , 元组 ) 都可以互换使用 . 应当如何使用哪个呢?
从最明显的一个开始 , 字符比其他序列有更多的限制 , 因为它的元素必须是字符 . 它们也是不可变的 .
如果你需要修改一个字符串中的字符 ( 而不是新建一个字符串 ) , 可能需要使用字符的列表 .
列表比元组更加通用 , 只要因为它是可变的 . 但也有一些情况下你可能会优先选择元组 .
* 1. 在有些环境中 , 如返回语句中 , 创建元组不创建列表从语法上说更容易 .
( 使用逗号分隔即可创建一个元组 . )
* 2. 如果需要用序列作为字典的键 , 则必须使用不可变类型 , 如元组或字符串 .
* 3. 如果你要向函数传入一个序列作为参数 , 使用元组会减少潜在的由假名导致的不可预知行为 .
( 不推荐使用列表作为函数的参数 . )
因为元组是不可变的 , 它们不提供类似sort和reverse之类的方法 , 这些方法修改现有的序列 .
但Python也提供了内置函数sorter , 可以接收任意序列作为参数 ,
并按排好的顺序返回带有同样元素的新列表 .
Python还提供了reverse , 可以接收序列作为参数 , 并返回一个以相反顺序遍历列表的迭代器 .
列表 , 字典和元组都被统一看作是一种数据结构 .
本章中我们开始看到符合数据结构 , 像元组的列表 , 或者用元组做件 , 用列表做值的字典等 .
复合数据结构横有用 , 但它容易导致我称为的 '结构错误' ,
也就是说 , 数据结构因为错的类型 , 大小或结果导致的错误 .
例如 , 如果你期望得到一个包含单个整数的列表 , 而我给你一个单个整数 ( 而不是在列表中 ) , 就是出错 .
为了帮助调试这种问题 , 我写了一个模块structshape , 提供一个也叫structshape函数 ,
接收任何数据类型作为参数 , 并返回一个描述它的形状的字符串 .
你可以从下面↓这个地址下载它 .
https : / / raw . githubusercontent . com / AllenDowney / ThinkPython2 / master / code / structshape . py
下面是一个简单列表的结果 :
>> > form structshape import structshape
>> > t = [ 1 , 2 , 3 ]
>> > structshape( t)
'list of 3 int'
更好看的程序可能会输出 'list of 3 ints' , 但不需要处理复数更加容易 .
下面是列表的列表 :
>> > t2 = [ [ 1 , 2 ] , [ 3 , 4 ] , [ 5 , 6 ] ]
>> > structshape( t2)
>> > 'list of 3 list of 2 int'
如果列表的元素不是同一种类型 , structshape会根据它们的类型按顺序分组 :
>> > t3 = [ 1 , 2 , 3 , 4.0 , '5' , '6' , [ 7 ] , [ 8 ] , 9 ]
>> > structshape( t3)
'list of (3 int, float, 2 str, 2 list, int)'
下面是元组的列表 :
s = 'abc'
lt = list ( zip ( t, s) )
>> > structshape( lt)
'list of 3 tuple of (int, str)'
下面是一个字典 , 有 3 个从整数映射到字符串的项 :
>> > d = dict ( lt)
>> > structshape( d)
'dict of 3 int->str'
如果你发现要记住数据结构有困难 , structshape可以帮忙 .
元组 ( tuple ) : 一个不可变的元素序列 .
元组赋值 ( tuple assignment ) : 一个赋值语句 , 右侧是一个序列 , 左侧是一个变量的元组 .
右边的序列会被求值 , 它的元素依次赋值给左侧元组中的变量 .
收集 ( gather ) : 组装可变长参数元组的操作 .
分散 ( scatter ) : 把一个序列当作参数列表的操作 .
zip对象 ( zip object ) : 调用内置函数zip的结果 , 它是一个迭代访问有元组组成的序列的对象 .
迭代器 ( iterator ) : 可以遍历序列的对象 , 但它不提供列表的操作和方法 .
数据结构 ( data structure ) : 相关的值的集合 , 通常组织成列表 , 字典 , 元组等 .
结构错误 ( shape error ) : 某个值由于其结构不对导致的错误 , 即它的类型或尺寸不对 .
编写一个函数most_frequent , 接收一个字符串并按照频率的降序打印字母 .
从不同语言中查找文本样例并查看不同语言中的单词频率如何变化 .
将你的结果和 : http : / / en . wikipedia . org / wiki / Letter_frequencies 上的列表进行对比 .
解答 : ( 提示 , 先使用字典统计频率 , 在将键值对转为元组列表 , [ ( val , 'letter' ) , . . . ] , 最后排序 )
https : / / raw . githubusercontent . com / AllenDowney / ThinkPython2 / master / code / most_frequent . py
需要使用emma . txt文件 , 下载地址 :
https : / / github . com / AllenDowney / ThinkPython2 / blob / master / code / emma . txt
list1 = [ ( 'b' , 5 ) , ( 'c' , 3 ) , ( 'a' , 10 ) ]
list1. sort( )
print ( list1)
list2 = [ ( 10 , 'a' ) , ( 5 , 'b' ) , ( 3 , 'c' ) ]
list2. sort( )
print ( list2)
def make_dict ( name= r'C:\Users\13600\Desktop\emma.txt' ) :
fin = open ( name, encoding= 'utf8' )
words_str = fin. read( )
frequency_count = { }
for letter in words_str:
frequency_count[ letter] = frequency_count. get( letter, 0 ) + 1
return frequency_count
def frequency_sorting ( ) :
letter_frequency_dict = make_dict( )
frequency_list = [ ]
for letter, freq_num in letter_frequency_dict. items( ) :
frequency_list. append( ( freq_num, letter) )
frequency_list. sort( reverse= True )
for freq_num, letter in frequency_list:
print ( letter, freq_num)
frequency_sorting( )
更多回文 .
1. 编写一个程序从文件中读入一个单词列表 ( 参见 9.1 节 ) 并打印出所有是回文的单词集合 .
下面是输出的样子的示例 :
[ 'deltas' , 'desalt' , 'lasted' , 'salted' , 'slated' , 'staled' ]
[ 'retainers' , 'ternaries' ]
[ 'generating' , 'greatening' ] # 这个单词怎么都不会回文 . . .
[ 'resmrlts' , 'smelters' , 'termless' ]
提示 : 你可能需要构建一个字典将字母的集合映射到可以用这些字母构成的单词的列表上 .
问题是 , 如何你表达字母的集合 , 才能让它可以用作字典的键?
它的意思是 , 使用这些字母可以组成的单词 . 第一个程序是没错的 , 并不涉及到回文的判断 !
解答 : https : / / raw . githubusercontent . com / AllenDowney / ThinkPython2 / master / code / anagram_sets . py
def make_words_dict ( ) :
fin = open ( r'C:\Users\13600\Desktop/words.txt' )
words_dict = { }
for line in fin:
word = line. strip( )
new_list = [ ]
for i in word:
new_list. append( i)
new_list. sort( )
sort_word = '' . join( new_list)
words_dict. setdefault( sort_word, [ ] ) . append( word)
return words_dict
d = make_words_dict( )
for key in d:
val = d. get( key)
if len ( val) > 1 :
print ( key, val)
2. 修改前面一个问题的程序 , 让它先打印出最大的回文列表 , 再打印第二大的回文列表 , 以此列推 .
def make_words_dict ( ) :
fin = open ( r'C:\Users\13600\Desktop/words.txt' )
words_dict = { }
for line in fin:
word = line. strip( )
new_list = [ ]
for i in word:
new_list. append( i)
new_list. sort( )
sort_word = '' . join( new_list)
words_dict. setdefault( sort_word, [ ] ) . append( word)
return words_dict
def filter_dict ( tem_d) :
filter_d = { }
for key in tem_d:
val = tem_d. get( key)
if len ( val) > 1 :
filter_d. setdefault( key, val)
return filter_d
def sort_list ( ) :
d = make_words_dict( )
filter_d = filter_dict( d)
count_dict = { }
for key in filter_d:
val = filter_d. get( key)
count_dict. setdefault( len ( val) , [ ] ) . append( val)
count_list = [ ]
for key, val in count_dict. items( ) :
count_list. append( ( key, val) )
count_list. sort( reverse= True )
for part1, li in count_list:
for i in li:
print ( part1, i)
sort_list( )
3. 在Scrabble拼字游戏中 ,
一个 'bingo' 代表你自己架子上全部 7 个字母 , 和盘上的一个字母组合成一个 8 字母单词 .
哪一个 8 个字母单词可以生成最后的bingo? 提示 : 一共有 7 个 .
( 读不懂 , 看他代码的意思是 , 在上一个练习的结果上 ,
过滤出 8 个字母组成的单词 , 看那些单词可以组成的单词最对多 . )
def make_words_dict ( ) :
fin = open ( r'C:\Users\13600\Desktop/words.txt' )
words_dict = { }
for line in fin:
word = line. strip( )
new_list = [ ]
for i in word:
new_list. append( i)
new_list. sort( )
sort_word = '' . join( new_list)
words_dict. setdefault( sort_word, [ ] ) . append( word)
return words_dict
def filter_dict ( tem_d) :
filter_d = { }
for key in tem_d:
val = tem_d. get( key)
if len ( val) > 1 :
filter_d. setdefault( key, val)
return filter_d
def sort_list ( ) :
d = make_words_dict( )
filter_d = filter_dict( d)
count_dict = { }
for key in filter_d:
if len ( key) == 8 :
val = filter_d. get( key)
count_dict. setdefault( len ( val) , [ ] ) . append( val)
count_list = [ ]
for key, val in count_dict. items( ) :
count_list. append( ( key, val) )
count_list. sort( reverse= True )
for part1, li in count_list:
for i in li:
print ( part1, i)
sort_list( )
两个单词 , 如果可以通过交换两个字母将一个单词转为另一个 , 就称为 '置换对' ;
例如 , 'converse' 和 'conserve' . 编写一个程序查找字典中所有的置换对 .
提示 : 不要测试所有的单词对 , 也不要测试所有所有可能的交换 .
解答 : http : / / metathesis . py
鸣谢 : 这个联系启发自http : / / puzzlers . org的示例 .
设计思路 : 比较两个单词 , 单词中只要有两位字母位置不一样即可 .
如 : vailing 和 vialing 进行比较 , 两个单词只有两个字母的位置不一样则这个单词就是置换对 .
def make_word_dict ( ) :
"""
组成单词的字母正序字符串作为键, 可以由这些字母组成的单词为值的一个元素, 值是一个列表.
:return: dict
"""
fin = open ( r'C:\Users\13600\Desktop\words.txt' )
word_dict = dict ( )
for line_rn in fin:
word = line_rn. strip( )
letter_list = [ ]
for i in word:
letter_list. append( i)
letter_list. sort( )
key = '' . join( letter_list)
word_dict. setdefault( key, [ ] ) . append( word)
return word_dict
def filter_dict ( ) :
d = make_word_dict( )
filter_word_dict = dict ( )
for key in d:
val = d. get( key)
if len ( val) >= 2 :
filter_word_dict. setdefault( key, val)
return filter_word_dict
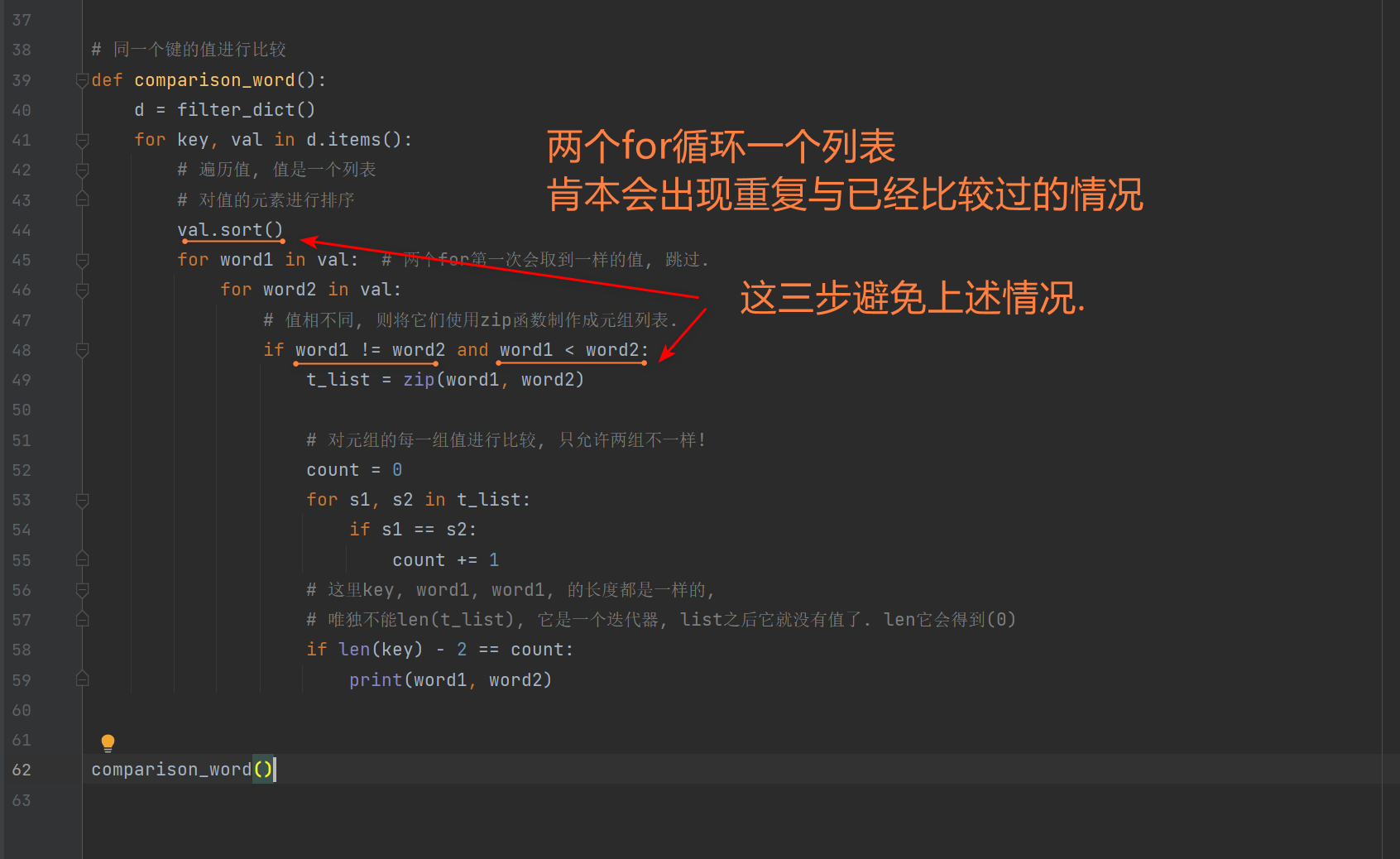
def comparison_word ( ) :
d = filter_dict( )
for key, val in d. items( ) :
val. sort( )
for word1 in val:
for word2 in val:
if word1 != word2 and word1 < word2:
t_list = zip ( word1, word2)
count = 0
for s1, s2 in t_list:
if s1 == s2:
count += 1
if len ( key) - 2 == count:
print ( word1, word2)
comparison_word( )
l1 = [ 1 , 3 , 2 , 6 ]
l1. sort( )
for i in l1:
for j in l1:
if i != j and i < j:
print ( i, j)
下面是 < < 车迷天下 > > 节目中的一个谜题 ( http : / / www . cartalk . com / content / puzzlers ) :
一个英文单词 , 当逐个删除它的字母时 , 任然是英文单词 . 这样的单词中最长的是什么?
首先 , 字母可以从两头从两头或者中间删除 , 但你不能重排字母 .
每次你去掉一个字母 , 则得到另一个英文单词 .
如果一直这么做 , 最终会得到一个字母 , 它本身也是一个英文单词--可以从字典上找到的 .
我想知道这样的最长单词是什么 , 它有多少个字母?
我会给你一个普通的例子 : Sprite .
你从sprite开始 , 取出一个字母 , 从单词内部取 , 取走r , 这样我们就剩下单词spite ,
接下我们取走结尾的e , 剩下spit , 接着取取走s , 我们剩下pit , it和i .
* 取走字母后的单词存在 , 才对这个单词才继续取字母 .
编写一个程序来找到所有可以这样缩减的单词 , 然后找到最长的一个 .
这个练习比大部分练习都更有挑战 , 所有下面有一些建议 .
1. 你可能需要编写一个程序接收一个单词 , 并计算出所有通过从它取出一个字母得到的单词的列表 .
它们是这个单词的 '子' 单词 .
2. 递归地 , 只有当一个单词的字单词中有一个可缩减时 , 它才可缩减 .
作为一个基准情形 , 你可以认为空字符串可缩减 .
3. 我提供的单词表 , words . txt , 并不存在单个字母的单词 .
所有你可能需要加上 'i' , 'a' 和空字符串 .
4. 为了提高程序的效率 , 你可能需要记住已知的可缩减的单词 .
解答 : https : / / raw . githubusercontent . com / AllenDowney / ThinkPython2 / master / code / reducible . py
解题思路 :
一个单词 hello , 从头到尾移除一次会得到 : ello , hllo , helo , helo , hell .
在将第一个单词移除 , 剩下 : ello , 从头到尾移除一次会得到 : llo , elo , elo , ell
. . . 依次删除到为空字符串为止 .
将每个单词可拆分的单词保存到备忘字典中 , 提高递归地效率 .
def make_words_dict ( ) :
words_dict = { '' : '' }
for i in range ( 97 , 123 ) :
words_dict. setdefault( chr ( i) , '' )
fin = open ( 'C:/Users/13600/Desktop/words.txt' )
for line in fin:
word = line. strip( )
words_dict. setdefault( word, '' )
return words_dict
def split_letter ( word, words_dict) :
words_list = [ ]
for i in range ( len ( word) ) :
split_word = word[ : i] + word[ i + 1 : ]
if split_word in words_dict:
words_list. append( split_word)
return words_list
memory_dict = { '' : [ '' ] }
def recursion ( word, words_dict) :
if word in memory_dict:
return memory_dict[ word]
memory_list = [ ]
for sub_word in split_letter( word, words_dict) :
if recursion( sub_word, words_dict) :
memory_list. append( sub_word)
memory_dict[ word] = memory_list
return memory_list
def analyze_dict ( words_dict) :
separable_word_list = [ ]
for word in words_dict:
separable_word = recursion( word, words_dict)
if separable_word:
separable_word_list. append( word)
return separable_word_list
def longest ( separable_word) :
longest_list = [ ]
for word in separable_word:
longest_list. append( ( len ( word) , word) )
longest_list. sort( reverse= True )
return longest_list[ 0 : 5 ]
def recursive_printing ( word, words_dict) :
if word:
res = recursion( word, words_dict)
print ( res[ 0 ] , end= ' ' )
recursive_printing( res[ 0 ] , words_dict)
def print_word ( longest_word, words_dict) :
for _, word in longest_word:
recursive_printing( word, words_dict)
print ( )
def main ( ) :
words_dict = make_words_dict( )
separable_word = analyze_dict( words_dict)
longest_word = longest( separable_word)
print_word( longest_word, words_dict)
main( )




























 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









