






二叉树所有路径

因为要从根节点到叶子节点,所以使用前序遍历(中左右)
这道题目涉及到回溯问题,因为需要把路径记下来,需要回溯来回退一个路径再进入另一个路径
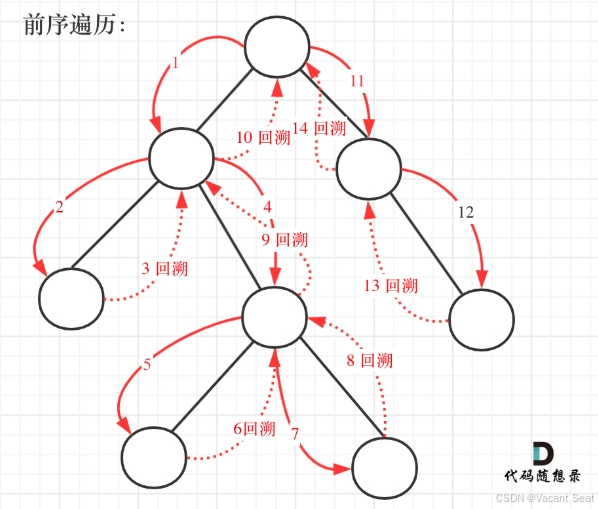
先使用递归的方式,来做前序遍历。递归三部曲:
- 递归函数的参数和返回值
要传入根节点,记录每一条路径的path,和存放结果集的result,不需要返回值 - 确定递归终止条件
遇到叶子节点就返回,所以
if (cur.left == null && cur.right == null) {
终止处理逻辑
}
为什么不用判断cur是否为空节点呢,因为下面的逻辑可以控制空节点不进入循环
3. 确定单层递归的逻辑
- 因为是前序遍历,需要处理中间节点,中间节点就是我们要记录路径上的节点,先放进path中。
- 然后判断如果左右节点不为空,再进行递归操作,
- 递归完了之后,还要进行回溯啊,因为path不能一直加入节点,还要删除节点,然后才能加入新的节点,回溯和递归是一一对应的,所以每一次递归都要有一个回溯。
class Solution {
public List<String> binaryTreePaths(TreeNode root) {
//定义res链表来存放结果
List<String> res = new ArrayList<>();
//如果root为空,则直接返回res
if(root == null){
return res;
}
//定义paths链表存储中间路径
List<Integer> paths = new ArrayList<>();
//递归入口
traversal(root,paths,res);
return res;
}
public void traversal(TreeNode root,List<Integer> paths,List<String> res){
//先将root加入paths
paths.add(root.val);
//碰到叶子节点返回
if(root.left == null && root.right == null){
StringBuilder sb = new StringBuilder();
for(int i = 0;i < paths.size() - 1;i++){
sb.append(paths.get(i)).append("->");
}
//处理最后一个元素
sb.append(paths.get(paths.size()-1));
res.add(sb.toString());
return;
}
//处理左边子树
if(root.left != null){
traversal(root.left,paths,res);
//回溯
paths.remove(paths.size() - 1);
}
//处理右边子树
if(root.right != null){
traversal(root.right,paths,res);
//回溯
paths.remove(paths.size() - 1);
}
}
}
class Solution {
//定义结果链表,用于返回结果
List<String> result = new ArrayList<>();
public List<String> binaryTreePaths(TreeNode root) {
//使用隐式回溯法,采用递归时每次传入的参数是之前传入的参数,参数是按值进行传递的
deal(root,"");
return result;
}
//定义函数来处理
public void deal(TreeNode node,String s){
//处理空节点
if(node == null){
return;
}
//当遇上叶子节点时,添加值和字符
if(node.left == null && node.right == null){
result.add(new StringBuilder(s).append(node.val).toString());
return;
}
//如果不是叶子节点,则定义String变量存储相应的值,并处理每次后面的->
String tmp = new StringBuilder(s).append(node.val).append("->").toString();
//然后递归调用左边和右边节点
deal(node.left,tmp);
deal(node.right,tmp);
}
}
在代码中,选择使用 StringBuilder 而不是直接操作字符串变量 s,主要是为了性能优化和代码的可读性。以下是具体原因:
-
性能优化:字符串拼接的开销
在 Java 中,字符串(String)是不可变对象。这意味着每次对字符串进行拼接操作时,都会创建一个新的字符串对象,而不是直接修改原字符串。例如:s = s + node.val + "->";
如果直接使用这种方式拼接字符串,每次拼接都会:
创建一个新的字符串对象。
复制原字符串的内容。
添加新的内容。
这种操作的复杂度是 O(n),其中 n 是字符串的长度。如果在递归中频繁进行字符串拼接,性能会显著下降。
而 StringBuilder 是可变对象,它内部维护一个字符数组,可以高效地进行字符拼接操作,而不需要每次都创建新的对象。因此,使用 StringBuilder 的复杂度接近 O(1),性能更高。 -
代码可读性
使用 StringBuilder 的 append 方法可以更清晰地表达代码的意图。例如:
StringBuilder sb = new StringBuilder(s);
sb.append(node.val).append("->");
String tmp = sb.toString();
这种方式比直接拼接字符串更直观,也更容易维护。同时,StringBuilder 提供了链式调用的能力(append 方法返回 StringBuilder 对象本身),使得代码更加简洁。
-
避免不必要的字符串复制
在递归中,如果直接使用字符串变量 s,每次递归调用都需要传递一个新的字符串对象,这会导致大量的内存分配和复制操作。而 StringBuilder 可以在同一个对象上进行多次修改,避免了不必要的对象创建和复制。 -
总结:为什么不能直接使用 s?
直接使用字符串变量 s 进行拼接操作会导致:
性能问题:字符串拼接频繁创建新对象,效率低下。
内存浪费:每次拼接都会产生新的字符串对象,占用更多内存。
代码复杂性:递归中传递字符串变量会增加代码的复杂性。
因此,作者选择使用 StringBuilder 来优化性能和提高代码的可读性。 -
扩展:如果一定要使用字符串变量
如果确实需要直接使用字符串变量 s,可以通过以下方式实现:
s = s + node.val + "->";
但这会带来性能问题。如果需要优化,可以使用 StringBuffer(线程安全)或 StringBuilder(非线程安全,性能更高)来替代直接的字符串拼接。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









