






1. Abstract:
大型语言模型(LLM)在生成人类查询的事实上和连贯回答方面的能力,以及训练数据质量参差不齐导致的挑战。论文提出了对LLM进行对齐的不同方法,以增强其与人类期望的一致性,并指出之前缺乏对这些方法的全面分类和详细解释。本工作旨在通过分类和详细解释每种对齐方法,帮助读者全面了解该领域的当前状态。
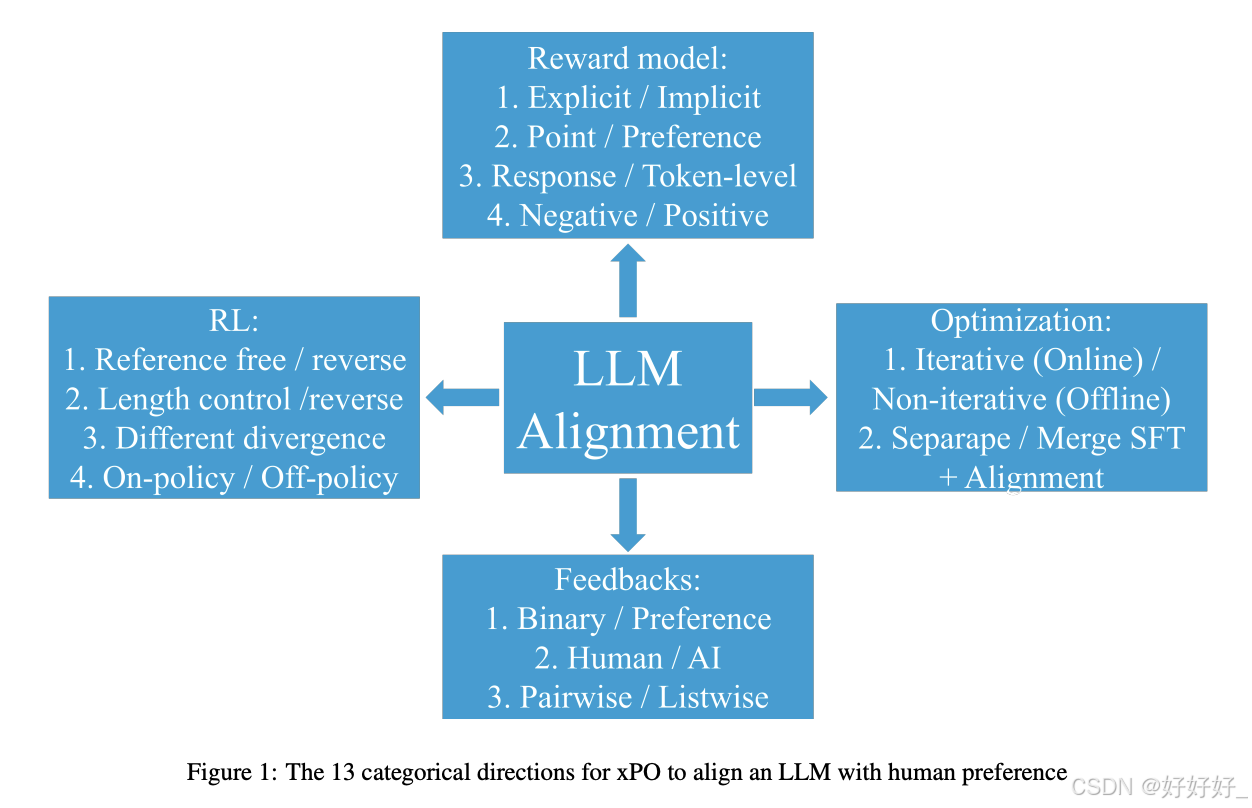
2. 分类大纲
提供了LLM对齐的关键元素的简洁介绍,包括四个主要方向:奖励模型、反馈、强化学习(RL)策略和优化。每个方向进一步细分为子主题,并提供了详细的讨论
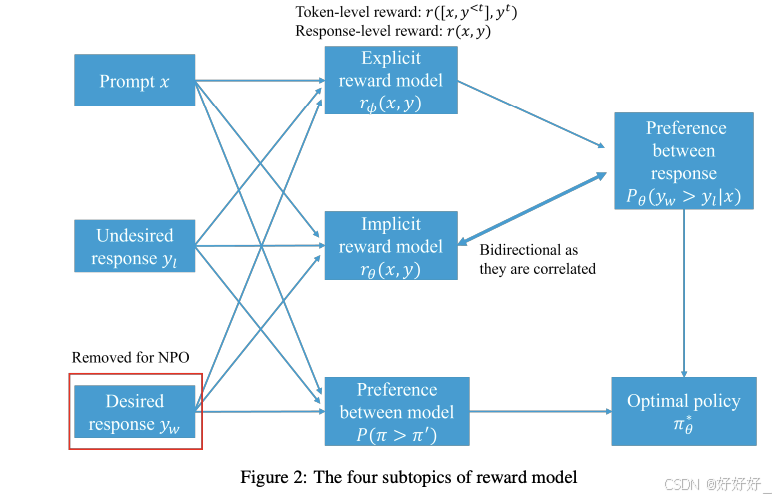
3. Reward model
显式奖励模型(Explicit Reward Model) vs. 隐式奖励模型(Implicit Reward Model)
显式奖励模型:通过在预训练的LLM上微调,基于提示和成对的响应(一个期望的响应和一个不期望的响应)来派生出明确奖励模型。这个模型随后用于RL设置中以对齐LLM策略。
隐式奖励模型:不经过训练显式奖励模型的过程。例如,在DPO(Direct Preference Optimization)中,建立了最优奖励模型和RL中最优策略之间的映射,允许在不直接派生奖励模型的情况下对齐LLM。
逐点奖励模型(Pointwise Reward Model) vs. 偏好模型(Preference Model)
逐点奖励模型:返回一个奖励分数,即给定提示x和响应y的r(x, y)。
偏好模型:直接模型P(yw > yl|x) = σ(r(x, yw) − r(x, yl)),基于Bradley–Terry (BT)模型,但这种方法不能直接获得成对偏好,并且不能容纳人类标记的不一致性。
响应级奖励(Response-Level Reward) vs. 令牌级奖励(Token-Level Reward)
响应级奖励:在原始数据集中,以三元组形式收集的数据,即{x, yw, yl},奖励是针对整个响应给出的。
**令牌级奖励:**在马尔可夫决策过程(MDP)中,每个动作后都会给出奖励,导致状态的改变。为了在每个动作后实现对齐,引入了令牌级奖励模型。
负偏好优化(Negative Preference Optimization)
在RLHF数据集中,人类标记了期望的和不期望的响应。随着LLM能力的提高,一些研究人员提出LLM可以生成比人类标记者更高质量的期望响应。因此,他们选择只使用数据集中的提示和不期望的响应,使用LLM生成期望的响应。
这些类别涵盖了奖励模型的不同方面,包括如何派生奖励、奖励的粒度(响应级或令牌级),以及如何处理正负反馈。通过这些不同的方法,研究人员可以更有效地对齐LLM,使其生成的响应符合人类的期望和价值观。
4. Feedback
偏好反馈(Preference Feedback) vs. 二进制反馈(Binary Feedback)
偏好反馈:涉及到比较和选择多个响应中的偏好,例如在RLHF中收集的“更好”或“更差”的反馈。
二进制反馈:是一种更简单的反馈形式,通常涉及正面(如“点赞”)或负面(如“不点赞”)的直接评价。
成对反馈(Pairwise Feedback) vs. 列表反馈(Listwise Feedback)
成对反馈:涉及到将两个响应进行比较,以确定哪一个更受偏好。
列表反馈:涉及到对一组响应进行排名或评分,这可以加快标签过程,因为可以一次性为一个提示收集多个响应。
人类反馈(Human Feedback) vs. AI反馈(AI Feedback)
人类反馈:直接从人类评估者那里获得的反馈,他们被要求对多个响应进行比较和评价。
AI反馈:随着LLM的发展,现在可以使用AI系统来收集对齐LLM的反馈,这可以减少人类评估的劳动强度和成本。
这些反馈类别提供了不同的方式来收集和利用评价信息,以改进LLM的性能。偏好反馈和成对反馈更侧重于比较和选择,而二进制反馈和列表反馈则提供了更简单或更批量的评价方式。人类反馈和AI反馈则涉及到反馈来源的不同,人类反馈通常更可靠但成本更高,而AI反馈则可能更便宜但可能存在准确性问题。通过这些不同的反馈方法,研究人员可以更灵活地调整和优化LLM,以更好地满足特定的应用需求和性能目标。
5. RL策略
基于参考的RL(Reference-Based RL) vs. 无参考的RL(Reference-Free RL)
基于参考的RL:在RLHF中,目标是最小化当前策略(πθ)和参考策略(πref)之间的距离。这种方法侧重于保持与初始SFT模型的一致性。
无参考的RL:一些方法提出了避免使用参考策略的方法,以减少内存负担和计算复杂性。例如,SimPO提出了一种不需要参考策略的目标函数。
长度控制RL(Length-Control RL)
当使用LLM作为评估器时,观察到它们倾向于偏好冗长的回答。为了解决这个问题,一些工作如R-DPO和SimPO在RL目标中加入了对输出长度的考虑。
RL中的不同散度(Different Divergences in RL)
在RLHF中,通常使用反向Kullback-Leibler (KL) 散度来衡量当前策略和参考策略之间的距离。然而,KL散度可能导致回答的多样性降低。因此,研究者探索了不同的散度度量,如Jensen-Shannon散度。
在线策略RL(On-policy RL) vs. 离线策略RL(Off-policy RL)
在线策略RL:在训练过程中,使用最新版本的策略来生成响应。这种方法可以实时采样响应,但可能需要更多的计算资源。
离线策略RL:依赖于之前生成的响应,这些响应可能与当前策略不一致,从而节省了在训练过程中生成新响应的时间。
6. 优化
- 迭代/在线偏好优化(Iterative/Online Preference Optimization)
当使用收集的数据集进行对齐时,这个过程被称为非迭代/离线偏好优化。而迭代/在线偏好优化在人类标记新数据或LLM同时生成和评估响应时变得可行。
- 合并SFT和对齐(Merging SFT and Alignment)
在RLHF中,SFT和对齐通常是顺序分离应用的,这可能导致灾难性遗忘。为了解决这个问题,一些研究如ORPO提出了将SFT与对齐集成到一个过程中,以简化微调。
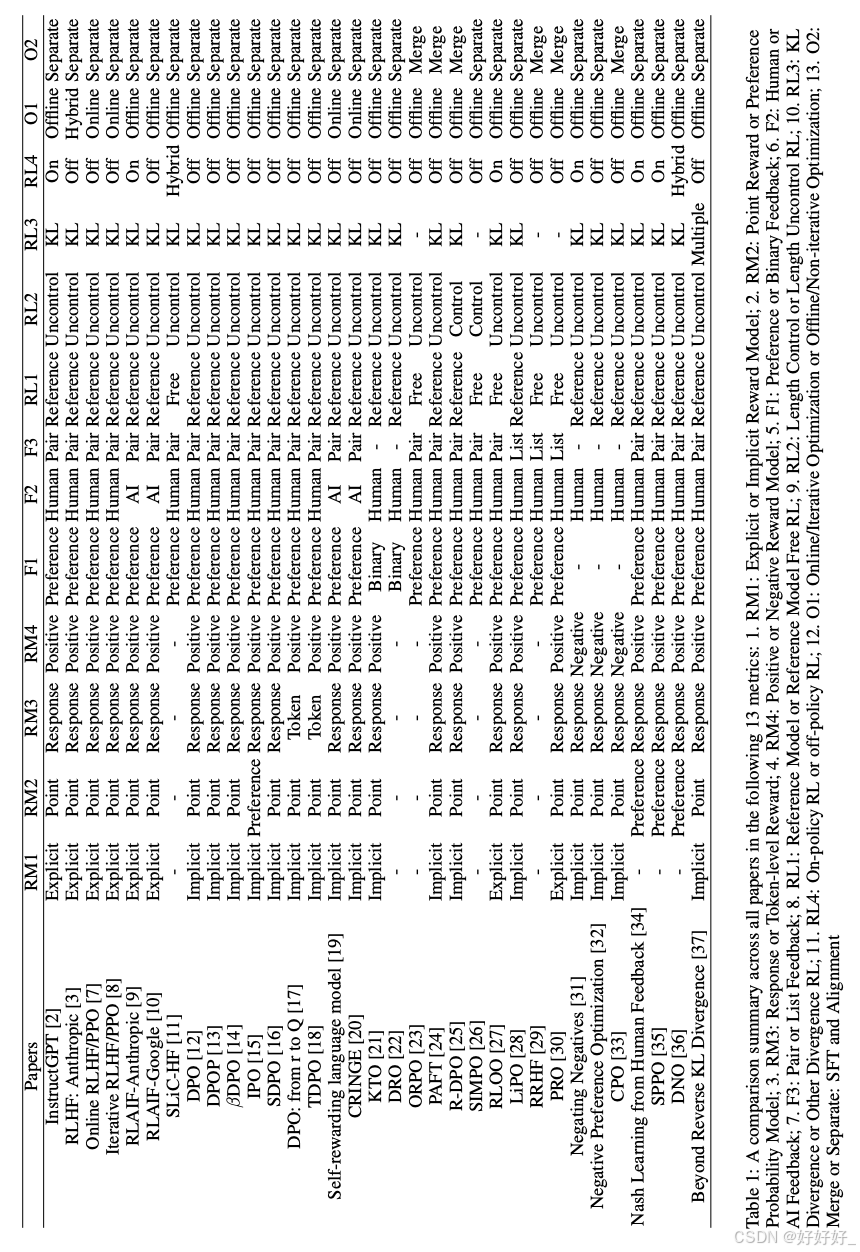
7. 具体方法
RLHF: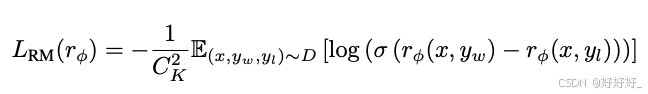
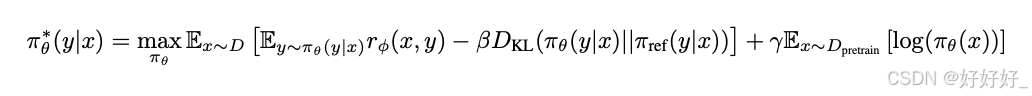
SliC-HF:
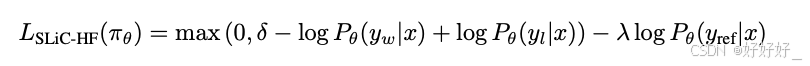
RSO

DPO
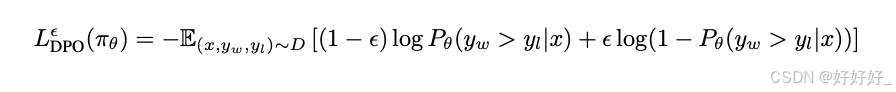
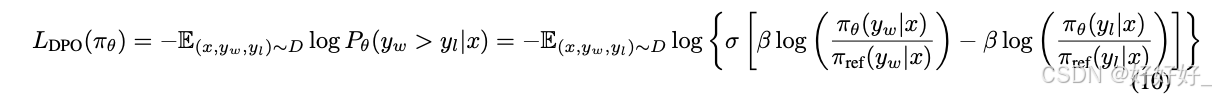
DPOP
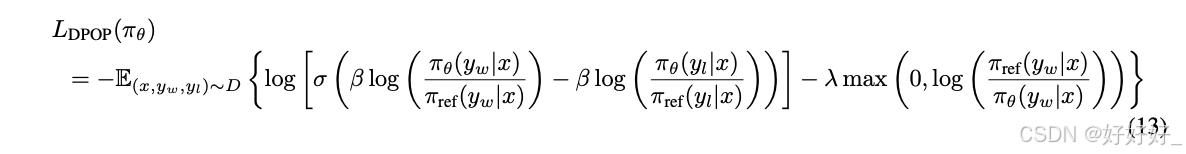
β
\beta
β-DPO:

IPO:
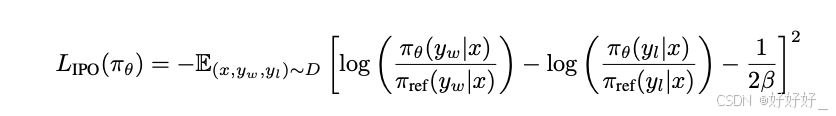
GPO:
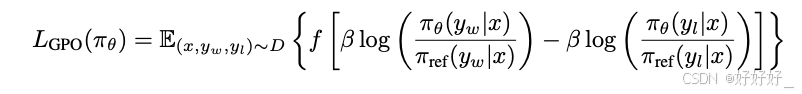
Token-level DPO:
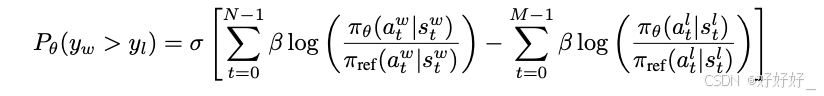
TDPO

**Iterative/online DPO: **
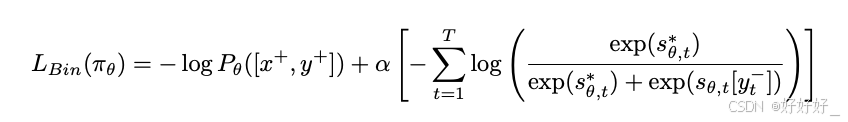
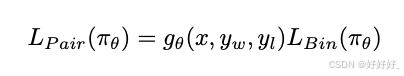
KTO:
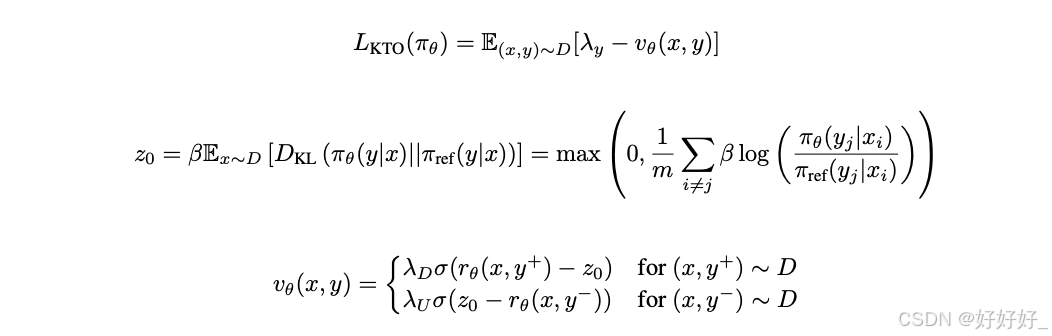 DRO:
DRO:

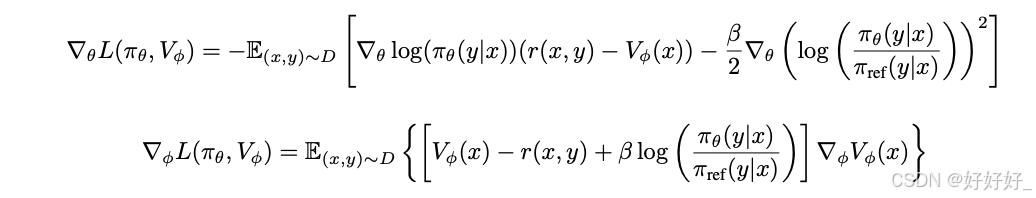
ORPO (merge DFT and alignment):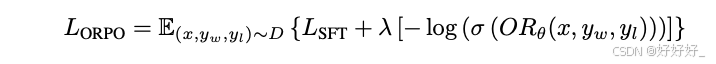
PAFT:
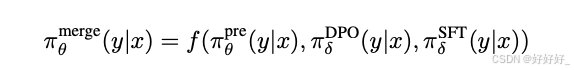
R-DPO:
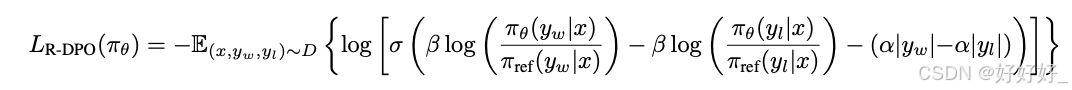
SimPO:
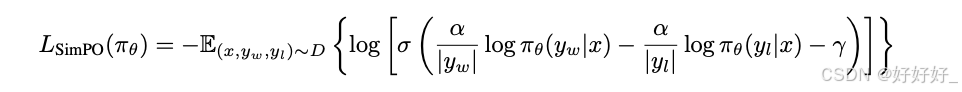
RLOO:
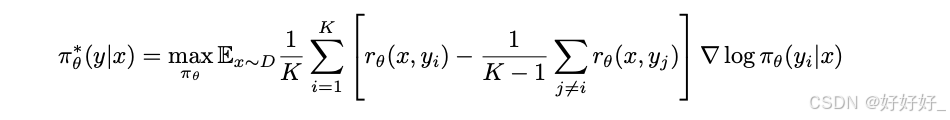
LiPO:
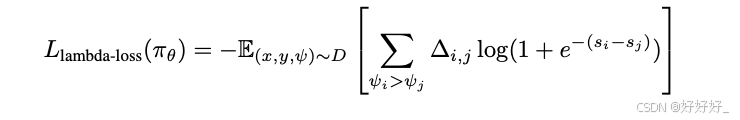
RRHF:
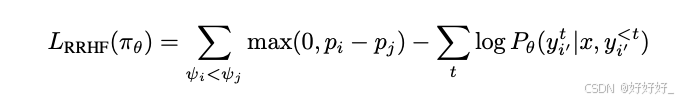
PRO:
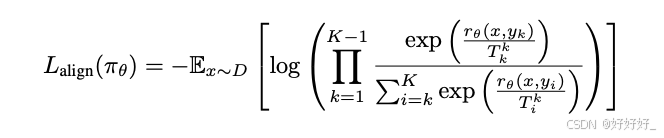
NN (Negating negatives:)
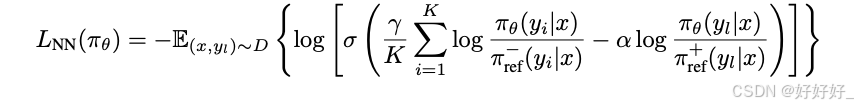
CPO:
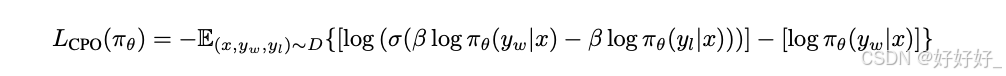
Nash Learning 是一种在大型语言模型(LLM)对齐中使用的策略,它基于博弈论中的Nash均衡概念。Nash Learning 的核心思想是直接对模型的偏好进行建模,而不是依赖于点式奖励或成对比较。这种方法试图通过考虑所有可能的模型策略来找到最优的策略,从而实现更好的对齐。以下是论文中提到的几种Nash Learning 方法:
Nash Learning from Human Feedback
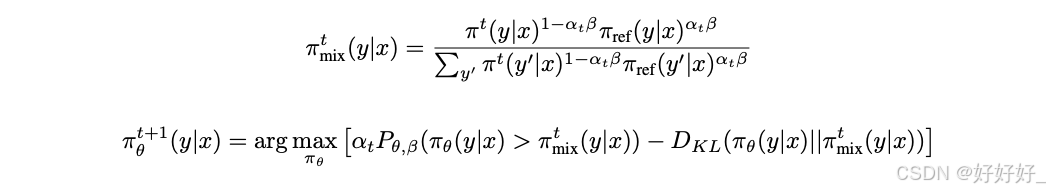
这种方法使用Nash均衡来处理人类反馈,而不是依赖于点式奖励模型。它通过直接建模两个策略之间的偏好概率来实现,从而避免了使用Bradley-Terry模型和点式奖励的需要。
Self-Play Preference Learning (SPPO)
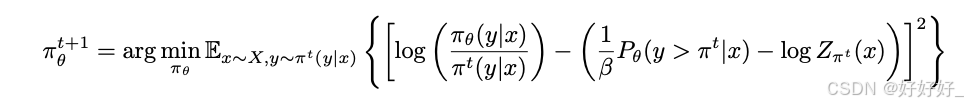
SPPO将RLHF重新解释为一个两玩家零和游戏,消除了对奖励模型的需求,使过程对噪声、非传递性和非马尔可夫偏好更加鲁棒。通过利用游戏的对称性,单个代理可以采样多个轨迹,然后使用胜率作为奖励来评估这些轨迹。
Direct Nash Optimization (DNO)
DNO采用了批量的在线策略算法,通过单时间尺度更新来简化问题,从而提高采样效率。这种方法试图通过回归内部奖励函数来简化Nash均衡的寻找过程。
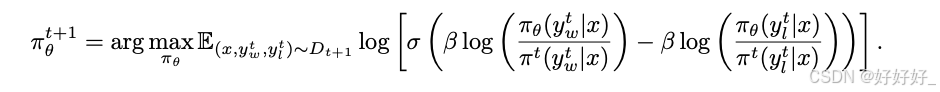

Future
- 通用任务用于对齐评估:开发和结合特定的任务,创建一个统一的排行榜,用于评估和比较不同对齐方法的性能。
- 将隐式奖励模型、列表偏好和Nash学习应用于更大规模的LLM:将这些方法扩展到更大的模型上,如GPT-4和Claude-3,以了解它们与RLHF/PPO相比的有效性。
- 在二进制反馈上进行实验:研究如何利用更容易收集的二进制反馈数据来对齐LLM,并探索如何有效过滤噪声数据。
- 使用AI反馈进行实验:使用LLM生成的帮助性反馈来进一步对齐LLM,使模型能够自我改进。
- 加速Nash学习:研究如何减少Nash学习方法所需的迭代次数,以加快对齐过程。
- 确定迭代/在线学习的终止点:研究如何确定合理的迭代终止点,以避免过拟合并保持模型在特定任务上的性能。
- 简化SFT和对齐的结合:探索如何有效地结合SFT和对齐,以实现高性能的同时保持训练过程的效率。
- 探索不同的散度度量:研究在对齐过程中使用不同的散度度量(如Jensen-Shannon散度)对模型性能的影响。
- 处理分布外数据:开发方法来提高LLM在处理分布外数据时的鲁棒性和性能。
- 提高对齐方法的可解释性:研究如何提高对齐方法的可解释性,以便更好地理解模型的决策过程。
- 跨领域和跨语言的对齐:探索对齐方法在不同领域和语言中的应用,以及如何适应不同的文化和语境

















 774
774

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









