






一、连接autodl并下载ollama
创建如下配置的实例

使用该实例的登陆指令和密码连接到该实例(我使用的是VScode)
连接成功以后在终端使用以下命令开启学术加速(加速下载,否则网速会很慢)
source /etc/network_turbo开启后使用下面的命令下载ollama(服务器是Linux系统,此命令可以在ollama官网的Linux版本下载位置找到)
curl -fsSL https://ollama.com/install.sh | sh
从上图可以看出,有个依赖需要安装,这个要看部署的服务器情况,有时候缺少有时候又是ok的,缺少什么就安装什么,安装对应的依赖后重新安装ollama就好了。
分别执行下列两个命令安装lshw:
sudo apt-get updatesudo apt-get install lshw安装成功之后再次执行ollama安装命令

ollama安装成功!
ollama安装成功后默认以服务形式运行,运行命令检查状态:
systemctl status ollama.service
如果出现此问题,则systemctl 命令异常,需要安装 systemd和systemctl,分别执行下列两个命令:
apt-get install systemd -yapt-get install systemctl -y安装完成后,重新启动服务:
systemctl start ollama.service查看服务启动状态:
systemctl status ollama.service
此状态说明服务正常。
二、设置ollama的端口和模型保存地址
由于AutoDL只能开放6006端口,所以我们要想在本地电脑访问到Ollama接口,必须手动设置Ollama端口为6006;同时将Ollama的模型保存地址也修改到autodl-tmp文件夹下。
编辑/etc/profile文件
vim /etc/profile首先按G,然后再按o进入编辑模式,在文件底部加入以下内容。
export OLLAMA_HOST="0.0.0.0:6006"
export OLLAMA_MODELS=/root/autodl-tmp/models接下来按EXC退出编辑模式,输入:wq保存文件。
然后输入以下命令使得配置生效。
source /etc/profile检查配置是否生效。
echo $OLLAMA_HOST出现下列显示说明配置生效

三、下载模型并运行(终端运行)
使用以下命令拉取模型(我拉取的是llama3,可根据自己需要修改模型名称):
ollama pull llama3拉取成功显示如下:
 再执行以下命令运行模型(llama3为模型名称,同样根据自己需要修改),若还未下载对应模型,执行此命令后也会自动下载:
再执行以下命令运行模型(llama3为模型名称,同样根据自己需要修改),若还未下载对应模型,执行此命令后也会自动下载:
ollama run llama3运行成功后即可在终端与LLM对话聊天:
成功部署后使用下列命令取消学术加速,若需要下载新模型则再执行前面的命令开启:
unset http_proxy && unset https_proxy四、使用python脚本调用API执行
Ollama模型默认会开启两个API接口供用户访问。
想要访问AutoDL的6006端口,还需要在本地开启一个代理。
回到容器实例页面,然后点击自定义服务

下载桌面工具:
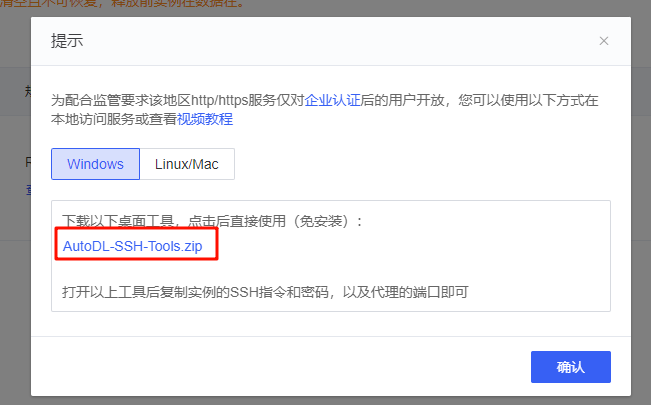
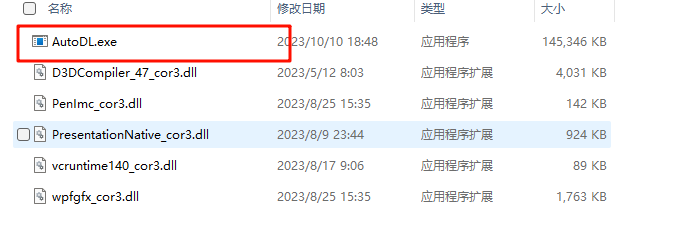
下载完成后自行解压,打开文件夹中的AutoDL.exe可执行文件。
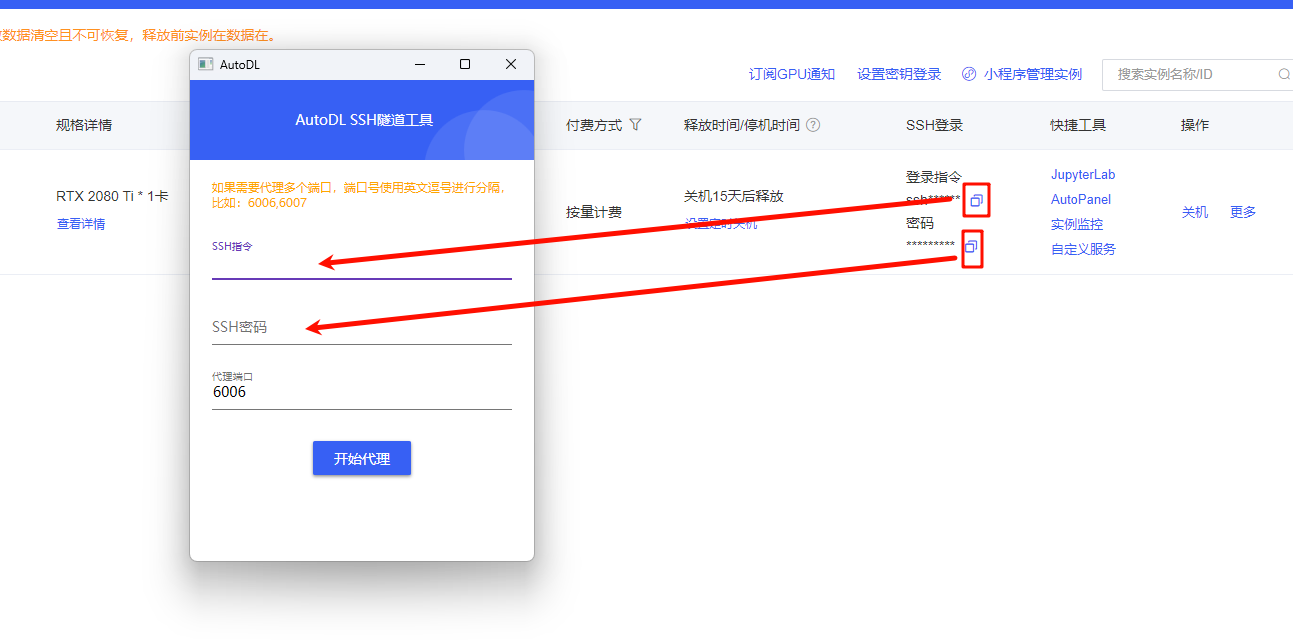
然后,输入SSH指令和SSH密码,点击开始代理即可。
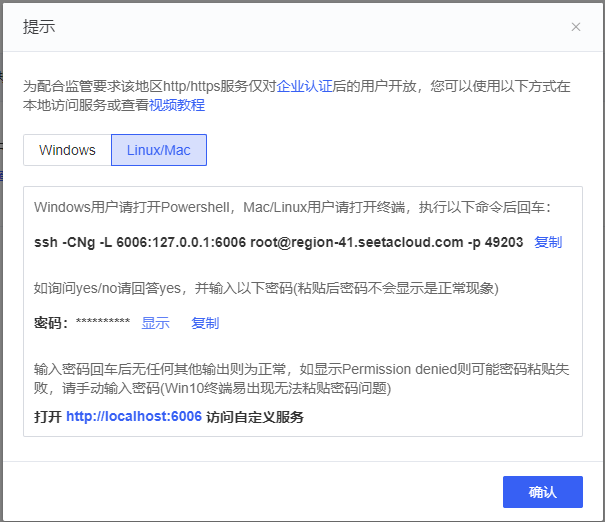
如果是
Linux或Mac系统选择后面的版本,安装提示操作即可。
使用以下测试脚本:
url='http://localhost:6006/api/chat'
import requests
import json
def send_post_request(url, data):
try:
headers = {'Content-type': 'application/json'}
response = requests.post(url, data=json.dumps(data))
if response.status_code == 200:
return response.json()
else:
print(f"Request failed with status code: {response.status_code}")
return None
except requests.exceptions.RequestException as e:
print(f"Request failed: {e}")
return None
# 请求参数
data = {
"model": "llama3",
"messages": [
{
"role": "user",
"content":"who are you?"
}
],
"stream": False
}
# 发送 POST 请求并获取响应数据
response_data = send_post_request(url, data)
if response_data:
# print("Response data:")
# 提取 content 字段的值
content = response_data["message"]["content"]
print(content)
运行后得到回复,则说明API调用成功!
参考博客:
【AI基础】租用云GPU之autoDL部署大模型ollama+llama3_autodl ollama-优快云博客



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









