






各种状态解释
同步异步、阻塞非阻塞

Linux下的几种IO模型
阻塞和非阻塞设置的是文件描述符fd的属性
阻塞模型
进程在IO未准备好时被挂起,直到准备好
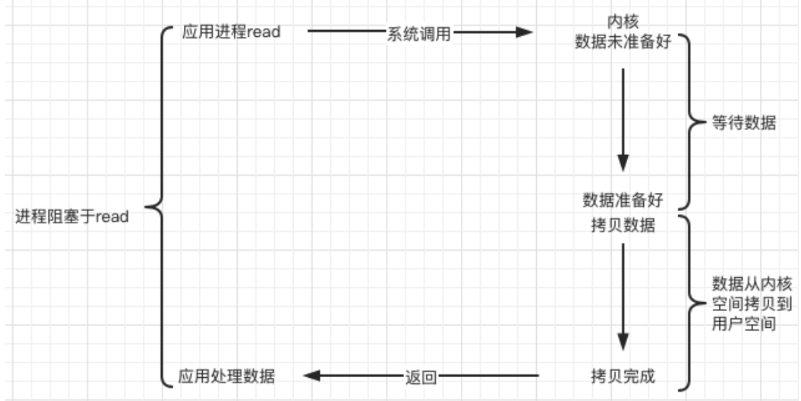
非阻塞模型
进程不会被挂起,而是根据返回值区分当前IO状态
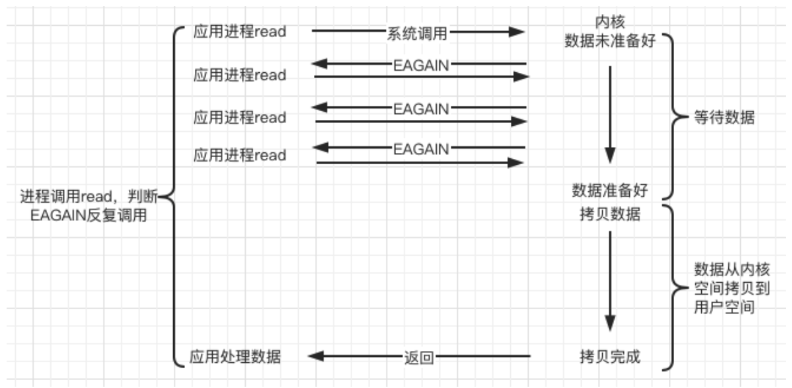
IO复用
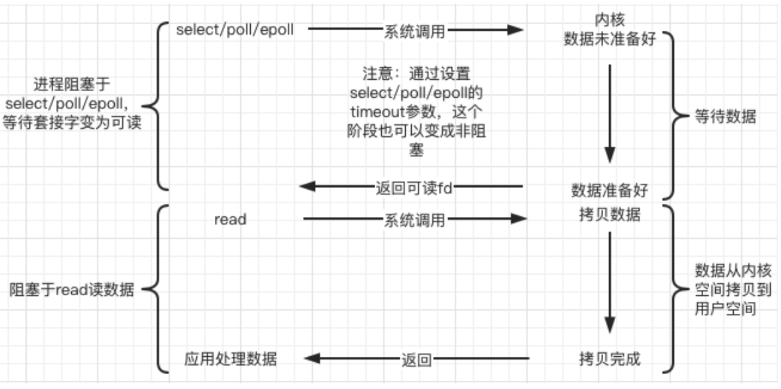
信号驱动
通过信号处理函数进行处理
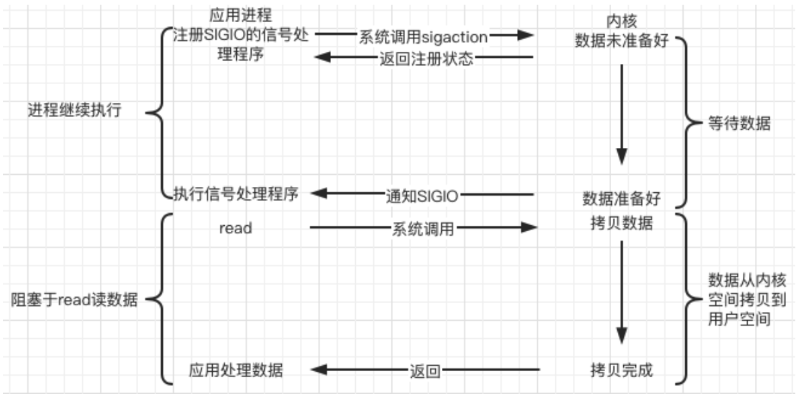
异步
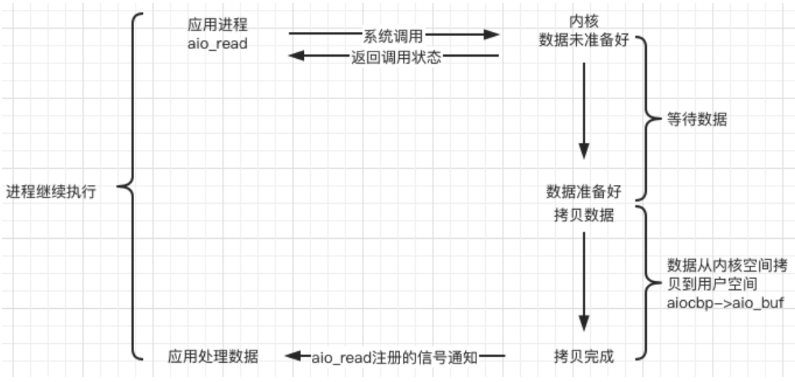
异步使用的结构体
/* Asynchronous I/O control block. */
struct aiocb
{
int aio_fildes; /* File desriptor. */
int aio_lio_opcode; /* Operation to be performed. */
int aio_reqprio; /* Request priority offset. */
volatile void *aio_buf; /* Location of buffer. */
size_t aio_nbytes; /* Length of transfer. */
struct sigevent aio_sigevent; /* Signal number and value. */
/* Internal members. */
struct aiocb *__next_prio;
int __abs_prio;
int __policy;
int __error_code;
__ssize_t __return_value;
#ifndef __USE_FILE_OFFSET64
__off_t aio_offset; /* File offset. */
char __pad[sizeof (__off64_t) - sizeof (__off_t)];
#else
__off64_t aio_offset; /* File offset. */
#endif
char __glibc_reserved[32];
};
Reactor模型
为什么提出reactor:
- 单线程模型:单个线程处理一个链接,线程调用read,此时不可读,阻塞到直到可读:效率低下
- 多线程模型:多个线程处理多个链接,每个线程依旧使用阻塞的方式进行读写,如果线程被占用,那么其他链接无法进入
- 异步模型:异步IO,非阻塞,但是无法当场知道处理结果,同步要求高的线程没法用
- IO多路复用思想:添加一个中间件,将多个事件全部注册到一个loop(循环)上,循环持续检查事件,谁好了就处理谁,这样不存在当前线程一直阻塞的问题
- muduo的实现思路:one loop per thread,一个线程管理一个循环
- 一个线程管理多个循环:多个死循环没法在一起
- 一个循环被多个线程管理:容易发生多个线程都被唤醒或争用问题(所有线程都想操作这个循环里的东西)
Reactor和主从Reactor的
- Reactor 模式:它只有一个 Reactor 线程。这个线程承担着多重任务,既需要监听所有的 I/O 事件,像客户端的连接请求、读写操作等,又要处理这些事件。当有新的事件发生时,Reactor 线程会调用相应的处理函数来处理事件。处理事务多,容易卡顿。
- 主从 Reactor 模式:该模式有主 Reactor 线程和多个从 Reactor 线程。主 Reactor 线程专门负责监听客户端的连接请求,一旦接收到连接请求,就会将新建立的连接分配给从 Reactor 线程。而从 Reactor 线程则负责处理这些连接上的读写事件。处理事务少,可发挥多核优势。
Proactor和主从reactor的区别:
- Proactor 模式
Proactor 模式属于异步 I/O 模式。在该模式里,当应用程序发起 I/O 操作时,会立即返回,由操作系统负责完成实际的 I/O 操作。操作完成后,操作系统会通过回调函数通知应用程序。像 Windows 下的 IOCP(Input/Output Completion Ports)就是典型的 Proactor 实现。 - 主从 Reactor 模式
主从 Reactor 模式属于同步 I/O 模式。它包含一个主 Reactor 和多个从 Reactor。主 Reactor 负责接收客户端的连接请求(listenFD),然后将连接分配给从 Reactor(clientFD)。从 Reactor 负责处理已建立连接上的读写操作。这种模式能够充分利用多核 CPU 的性能,提升系统的并发处理能力。
线程池
是已经被创建好的线程资源的集合。无需创建和删除操作,节约时间。
用空间换时间
条件变量
条件变量的条件在判断的时候必须先让信号量上锁,以防判断条件的同时另一个线程把条件改变了
传入后解锁是为了条件能够被改变
编写步骤
先写基础轮子:线程池和锁
确定要用什么模式:Proactor模式
然后创建监听描述符
epoll的创建和修改等操作
EPOLLONESHOT 是一个特殊的事件标志。当一个文件描述符被设置为 EPOLLONESHOT 时,在该文件描述符上触发一次事件后,epoll 会自动将其从监控列表中移除,即使该文件描述符上仍然有未处理的事件。这样可以确保一个文件描述符上的事件只被一个线程处理一次,避免多个线程同时处理同一个文件描述符上的事件而导致的数据竞争问题。
EPOLLRDHUP 是一个用于检测对端关闭连接的事件标志。当对端关闭连接(正常关闭或者异常关闭)时,epoll 会触发 EPOLLRDHUP 事件。在网络编程中,使用 EPOLLRDHUP 可以及时检测到对端的关闭操作,从而进行相应的处理,例如关闭本地的连接、释放资源等。
杂项
定时器
对于服务器的定时器功能,堆通常比升序链表效率更高,主要是插入删除操作与内存管理
(堆的根节点比左右子节点小)
- 插入和删除操作
- 升序链表:在升序链表中插入一个新的定时器节点时,需要遍历链表以找到合适的插入位置,平均时间复杂度为 O ( n ) O(n) O(n), n n n 为链表中节点的数量。删除操作同样可能需要遍历链表来找到要删除的节点,然后更新指针,时间复杂度也为 O ( n ) O(n) O(n)。
- 堆:对于堆来说,插入和删除操作的时间复杂度都是 O ( l o g n ) O(log n) O(logn)。当插入一个新的定时器时,将其添加到堆的末尾,然后通过上浮操作调整堆的结构以保持堆的性质;删除堆顶元素(即最早到期的定时器)后,通过下沉操作重新调整堆。由于堆的高度是 l o g n log n logn,所以这些操作的时间复杂度相对较低。
- 查找操作
- 升序链表:要查找最早到期的定时器(链表头部节点),时间复杂度为 O ( 1 ) O(1) O(1)。但是,如果需要查找特定时间之后到期的定时器,或者在链表中进行其他复杂的查找操作,通常需要遍历链表,时间复杂度会上升到 O ( n ) O(n) O(n)。
- 堆:堆可以在 O ( 1 ) O(1) O(1) 的时间内获取到最早到期的定时器(堆顶元素)。虽然在堆中进行其他类型的查找操作相对复杂,时间复杂度通常不是常数级,但对于定时器功能来说,快速获取最早到期的定时器是最关键的操作,而堆在这方面表现出色。
- 内存管理
- 升序链表:链表中的节点在内存中是分散存储的,每个节点除了存储数据本身外,还需要额外的指针来指向下一个节点,这会导致一定的内存碎片和额外的内存开销。
- 堆:通常使用数组来实现,内存空间是连续的,对于大规模的定时器管理,内存利用率较高,且在进行内存分配和释放时,相对链表来说更加简单和高效。
综上所述,在服务器定时器功能中,堆在插入、删除和查找最早到期定时器等操作上具有更高的效率,同时在内存管理方面也有一定优势,因此通常是比升序链表更优的选择。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









