







 该专栏为热销专栏榜 第7名
该专栏为热销专栏榜 第7名一、本文介绍
🔥本文给大家介绍使用TSSA模块改进YOLOv13网络模型。它通过基于统计量的特征交互,而非计算token间的相似度,降低了计算复杂度至线性,从而使模型能够处理长序列或高分辨率图像而不增加计算负担。此外,TSSA提高了模型的可解释性,增强了多任务适应性,且在不牺牲精度的情况下,提升了检测效率,特别适用于实时目标检测任务。
展示部分YOLOv13改进后的网络结构图:
🚀 创新改进结构图: yolov13n_HyperACE_TSSA.yaml
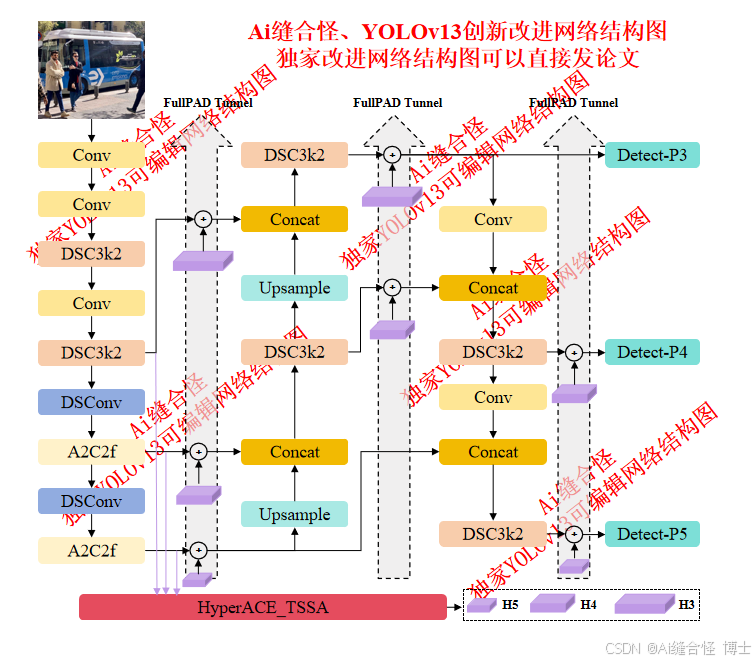
专栏改进目录:YOLOv13改进包含各种卷积、主干网络、各种注意力机制、检测头、损失函数、Neck改进、小目标检测、二次创新模块、HyperACE二次创新、独家创新等几百种创新点改进。
全新YOLOv13创新改进专栏链接:全新YOLOv13创新改进高效涨点+永久更新中(至少500+改进)+高效跑实验发论文
本文目录
1.首先在ultralytics/nn/newsAddmodules创建一个.py文件
2.在ultralytics/nn/newsAddmodules/__init__.py中引用
🚀 创新改进1 : yolov13n_HyperACE_TSSA.yaml
🚀 创新改进3 : yolov13n_DSC3k2_TSSA.yaml
二、TSSA模块介绍

摘要:注意力操作符无疑是Transformer架构的关键特征,Transformer在多种任务中展现了最先进的性能。然而,Transformer的注意力操作符通常会带来显著的计算负担,其计算复杂度随着token数量的增加呈二次增长。本文提出了一种新的Transformer注意力操作符,其计算复杂度随着token数量的增加呈线性增长。我们通过扩展先前的工作,推导出一种新的网络架构,这些工作表明,Transformer风格的架构自然通过“白盒”架构设计产生,其中网络的每一层都旨在实现最大化编码速率缩减目标(MCR2)的增量优化步骤。具体而言,我们推导出一种MCR2目标的变分形式,并展示了通过对这一变分目标进行展开梯度下降,得到了一种新的注意力模块,称为Token Statistics Self-Attention(TSSA)。TSSA具有线性计算和内存复杂度,并且与传统的计算token之间成对相似性的注意力架构有着根本性的不同。我们在视觉、语言和长序列任务上的实验表明,仅仅将TSSA替换为标准的自注意力操作符(我们称之为Token

 订阅专栏 解锁全文
订阅专栏 解锁全文

















 1484
1484

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









