







5. 堆
5.1 堆
以大顶堆为例,相对于之前的优先级队列,增加了堆化等方法
public class MaxHeap {
int[] array;
int size;
public MaxHeap(int capacity) {
this.array = new int[capacity];
}
/**
* 获取堆顶元素
*
* @return 堆顶元素
*/
public int peek() {
return array[0];
}
/**
* 删除堆顶元素
*
* @return 堆顶元素
*/
public int poll() {
int top = array[0];
swap(0, size - 1);
size--;
down(0);
return top;
}
/**
* 删除指定索引处元素
*
* @param index 索引
* @return 被删除元素
*/
public int poll(int index) {
int deleted = array[index];
swap(index, size - 1);
size--;
down(index);
return deleted;
}
/**
* 替换堆顶元素
* @param replaced 新元素
*/
public void replace(int replaced) {
array[0] = replaced;
down(0);
}
/**
* 堆的尾部添加元素
*
* @param offered 新元素
* @return 是否添加成功
*/
public boolean offer(int offered) {
if (size == array.length) {
return false;
}
up(offered);
size++;
return true;
}
// 将 offered 元素上浮: 直至 offered 小于父元素或到堆顶
private void up(int offered) {
int child = size;
while (child > 0) {
int parent = (child - 1) / 2;
if (offered > array[parent]) {
array[child] = array[parent];
} else {
break;
}
child = parent;
}
array[child] = offered;
}
public MaxHeap(int[] array) {
this.array = array;
this.size = array.length;
heapify();
}
// 建堆
private void heapify() {
// 如何找到最后这个非叶子节点 size / 2 - 1
for (int i = size / 2 - 1; i >= 0; i--) {
down(i);
}
}
// 将 parent 索引处的元素下潜: 与两个孩子较大者交换, 直至没孩子或孩子没它大
private void down(int parent) {
int left = parent * 2 + 1;
int right = left + 1;
int max = parent;
if (left < size && array[left] > array[max]) {
max = left;
}
if (right < size && array[right] > array[max]) {
max = right;
}
if (max != parent) { // 找到了更大的孩子
swap(max, parent);
down(max);
}
}
// 交换两个索引处的元素
private void swap(int i, int j) {
int t = array[i];
array[i] = array[j];
array[j] = t;
}
public static void main(String[] args) {
int[] array = {1, 2, 3, 4, 5, 6, 7};
MaxHeap maxHeap = new MaxHeap(array);
System.out.println(Arrays.toString(maxHeap.array));
}
}
建堆
Floyd 建堆算法作者(也是之前龟兔赛跑判环作者):

- 找到最后一个非叶子节点
- 从后向前,对每个节点执行下潜
一些规律
- 一棵满二叉树节点个数为 2 h − 1 2^h-1 2h−1,如下例中高度 h = 3 h=3 h=3 节点数是 2 3 − 1 = 7 2^3-1=7 23−1=7
- 非叶子节点范围为 [ 0 , s i z e / 2 − 1 ] [0, size/2-1] [0,size/2−1]
算法时间复杂度分析
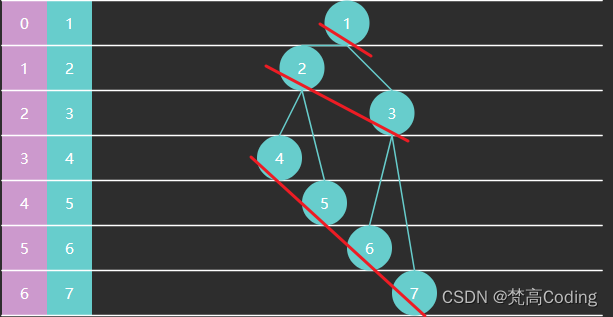
下面看交换次数的推导:设节点高度为 3
| 本层节点数 | 高度 | 下潜最多交换次数(高度-1) | |
|---|---|---|---|
| 4567 这层 | 4 | 1 | 0 |
| 23这层 | 2 | 2 | 1 |
| 1这层 | 1 | 3 | 2 |
每一层的交换次数为:
节点个数
∗
此节点交换次数
节点个数*此节点交换次数
节点个数∗此节点交换次数,总的交换次数为
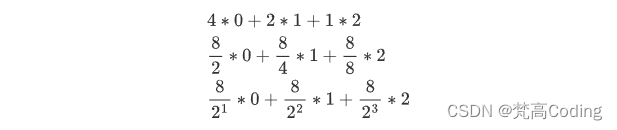
即
∑
i
=
1
h
(
2
h
2
i
∗
(
i
−
1
)
)
\sum_{i=1}^{h}(\frac{2^h}{2^i}*(i-1))
i=1∑h(2i2h∗(i−1))
在 https://www.wolframalpha.com/ 输入
Sum[\(40)Divide[Power[2,x],Power[2,i]]*\(40)i-1\(41)\(41),{i,1,x}]
推导出
2
h
−
h
−
1
2^h -h -1
2h−h−1
其中
2
h
≈
n
2^h \approx n
2h≈n,
h
≈
log
2
n
h \approx \log_2{n}
h≈log2n,因此有时间复杂度
O
(
n
)
O(n)
O(n)
5.2 二叉树
二叉树是这么一种树状结构:每个节点最多有两个孩子,左孩子和右孩子
重要的二叉树结构
- 完全二叉树(complete binary tree)是一种二叉树结构,除最后一层以外,每一层都必须填满,填充时要遵从先左后右
- 平衡二叉树(balance binary tree)是一种二叉树结构,其中每个节点的左右子树高度相差不超过 1
存储
存储方式分为两种
- 定义树节点与左、右孩子引用(TreeNode)
- 使用数组,前面讲堆时用过,若以 0 作为树的根,索引可以通过如下方式计算
- 父 = floor((子 - 1) / 2)
- 左孩子 = 父 * 2 + 1
- 右孩子 = 父 * 2 + 2
遍历
遍历也分为两种
- 广度优先遍历(Breadth-first order):尽可能先访问距离根最近的节点,也称为层序遍历
- 深度优先遍历(Depth-first order):对于二叉树,可以进一步分成三种(要深入到叶子节点)
- pre-order 前序遍历,对于每一棵子树,先访问该节点,然后是左子树,最后是右子树
- in-order 中序遍历,对于每一棵子树,先访问左子树,然后是该节点,最后是右子树
- post-order 后序遍历,对于每一棵子树,先访问左子树,然后是右子树,最后是该节点
广度优先
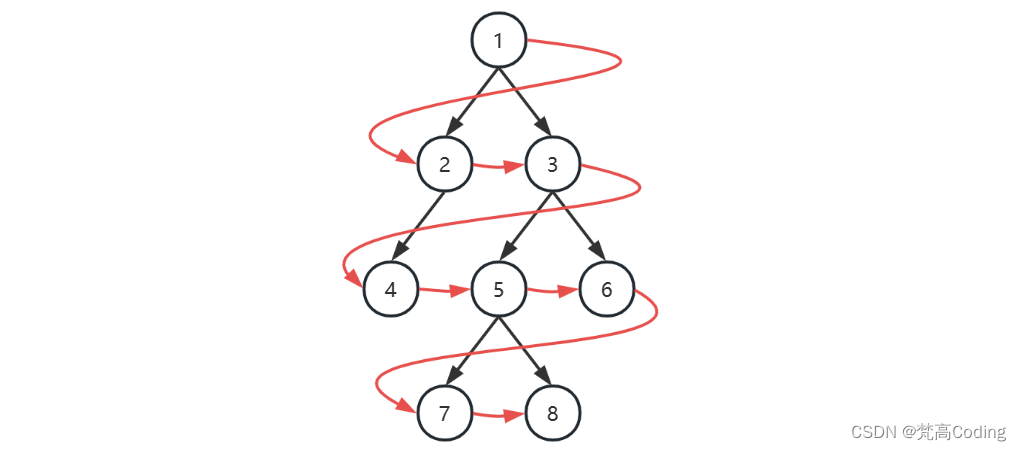
| 本轮开始时队列 | 本轮访问节点 |
|---|---|
| [1] | 1 |
| [2, 3] | 2 |
| [3, 4] | 3 |
| [4, 5, 6] | 4 |
| [5, 6] | 5 |
| [6, 7, 8] | 6 |
| [7, 8] | 7 |
| [8] | 8 |
| [] |
- 初始化,将根节点加入队列
- 循环处理队列中每个节点,直至队列为空
- 每次循环内处理节点后,将它的孩子节点(即下一层的节点)加入队列
注意
以上用队列来层序遍历是针对 TreeNode 这种方式表示的二叉树
对于数组表现的二叉树,则直接遍历数组即可,自然为层序遍历的顺序
深度优先
| 栈暂存 | 已处理 | 前序遍历 | 中序遍历 |
|---|---|---|---|
| [1] | 1 ✔️ 左💤 右💤 | 1 | |
| [1, 2] | 2✔️ 左💤 右💤 1✔️ 左💤 右💤 | 2 | |
| [1, 2, 4] | 4✔️ 左✔️ 右✔️ 2✔️ 左💤 右💤 1✔️ 左💤 右💤 | 4 | 4 |
| [1, 2] | 2✔️ 左✔️ 右✔️ 1✔️ 左💤 右💤 | 2 | |
| [1] | 1✔️ 左✔️ 右💤 | 1 | |
| [1, 3] | 3✔️ 左💤 右💤 1✔️ 左✔️ 右💤 | 3 | |
| [1, 3, 5] | 5✔️ 左✔️ 右✔️ 3✔️ 左💤 右💤 1✔️ 左✔️ 右💤 | 5 | 5 |
| [1, 3] | 3✔️ 左✔️ 右💤 1✔️ 左✔️ 右💤 | 3 | |
| [1, 3, 6] | 6✔️ 左✔️ 右✔️ 3✔️ 左✔️ 右💤 1✔️ 左✔️ 右💤 | 6 | 6 |
| [1, 3] | 3✔️ 左✔️ 右✔️ 1✔️ 左✔️ 右💤 | ||
| [1] | 1✔️ 左✔️ 右✔️ | ||
| [] |
递归实现
/**
* <h3>前序遍历</h3>
* @param node 节点
*/
static void preOrder(TreeNode node) {
if (node == null) {
return;
}
System.out.print(node.val + "\t"); // 值
preOrder(node.left); // 左
preOrder(node.right); // 右
}
/**
* <h3>中序遍历</h3>
* @param node 节点
*/
static void inOrder(TreeNode node) {
if (node == null) {
return;
}
inOrder(node.left); // 左
System.out.print(node.val + "\t"); // 值
inOrder(node.right); // 右
}
/**
* <h3>后序遍历</h3>
* @param node 节点
*/
static void postOrder(TreeNode node) {
if (node == null) {
return;
}
postOrder(node.left); // 左
postOrder(node.right); // 右
System.out.print(node.val + "\t"); // 值
}
非递归实现
前序遍历
LinkedListStack<TreeNode> stack = new LinkedListStack<>();
TreeNode curr = root;
while (!stack.isEmpty() || curr != null) {
if (curr != null) {
stack.push(curr);
System.out.println(curr);
curr = curr.left;
} else {
TreeNode pop = stack.pop();
curr = pop.right;
}
}
中序遍历
LinkedListStack<TreeNode> stack = new LinkedListStack<>();
TreeNode curr = root;
while (!stack.isEmpty() || curr != null) {
if (curr != null) {
stack.push(curr);
curr = curr.left;
} else {
TreeNode pop = stack.pop();
System.out.println(pop);
curr = pop.right;
}
}
后序遍历
LinkedListStack<TreeNode> stack = new LinkedListStack<>();
TreeNode curr = root;
TreeNode pop = null;
while (!stack.isEmpty() || curr != null) {
if (curr != null) {
stack.push(curr);
curr = curr.left;
} else {
TreeNode peek = stack.peek();
if (peek.right == null || peek.right == pop) {
pop = stack.pop();
System.out.println(pop);
} else {
curr = peek.right;
}
}
}
对于后序遍历,向回走时,需要处理完右子树才能 pop 出栈。如何知道右子树处理完成呢?
-
如果栈顶元素的 r i g h t ≡ n u l l right \equiv null right≡null 表示没啥可处理的,可以出栈
-
如果栈顶元素的 r i g h t ≠ n u l l right \neq null right=null,
- 那么使用 lastPop 记录最近出栈的节点,即表示从这个节点向回走
- 如果栈顶元素的 r i g h t = = l a s t P o p right==lastPop right==lastPop 此时应当出栈
对于前、中两种遍历,实际以上代码从右子树向回走时,并未走完全程(stack 提前出栈了)后序遍历以上代码是走完全程了
统一写法
下面是一种统一的写法,依据后序遍历修改
LinkedList<TreeNode> stack = new LinkedList<>();
TreeNode curr = root; // 代表当前节点
TreeNode pop = null; // 最近一次弹栈的元素
while (curr != null || !stack.isEmpty()) {
if (curr != null) {
colorPrintln("前: " + curr.val, 31);
stack.push(curr); // 压入栈,为了记住回来的路
curr = curr.left;
} else {
TreeNode peek = stack.peek();
// 右子树可以不处理, 对中序来说, 要在右子树处理之前打印
if (peek.right == null) {
colorPrintln("中: " + peek.val, 36);
pop = stack.pop();
colorPrintln("后: " + pop.val, 34);
}
// 右子树处理完成, 对中序来说, 无需打印
else if (peek.right == pop) {
pop = stack.pop();
colorPrintln("后: " + pop.val, 34);
}
// 右子树待处理, 对中序来说, 要在右子树处理之前打印
else {
colorPrintln("中: " + peek.val, 36);
curr = peek.right;
}
}
}
public static void colorPrintln(String origin, int color) {
System.out.printf("\033[%dm%s\033[0m%n", color, origin);
}
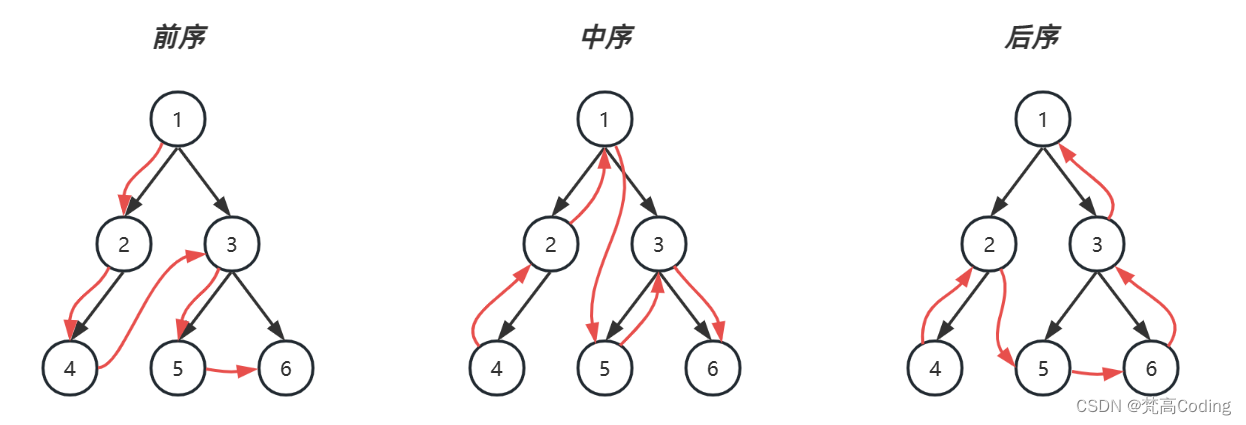
一张图演示三种遍历
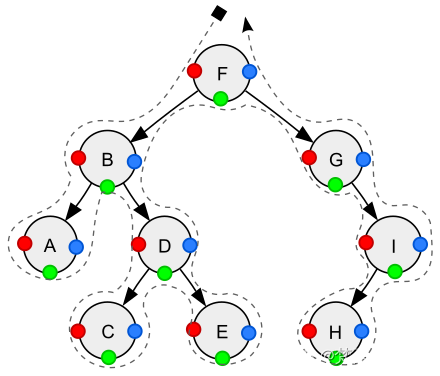
- 红色:前序遍历顺序
- 绿色:中序遍历顺序
- 蓝色:后续遍历顺序
5.3 Java中的堆
初始化
//小顶堆
PriorityQueue<Integer> queue = new PriorityQueue<>();
//大顶堆
PriorityQueue<Integer> queue = new PriorityQueue<>((a,b)->b-a);
入队列
queue.add(1) queue.offer(1)
出队列
queue.remove() queue.poll()


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









