






 本文详细解读了循环神经网络(RNN)、LSTM、双向循环神经网络(BRNN)和注意力模型在时间序列数据分析中的关键作用,探讨了BPTT在处理循环结构中的挑战,以及LSTM如何解决梯度消失问题。未来,深度RNN的发展方向也受到关注。
本文详细解读了循环神经网络(RNN)、LSTM、双向循环神经网络(BRNN)和注意力模型在时间序列数据分析中的关键作用,探讨了BPTT在处理循环结构中的挑战,以及LSTM如何解决梯度消失问题。未来,深度RNN的发展方向也受到关注。
论文的其他章节解读可以通过目录找到:On the origin of deep learning 文章解读系列目录表
本章将开始讨论一类新的深度学习模型,这些模型引起了许多关注,特别是在时间序列数据或序列数据上的任务。循环神经网络( Recurrent Neural Network,RNN )是一类单元连接形成有向循环的神经网络;这种性质赋予了其处理时态数据的能力。
目录
6.1 循环神经网络:Jordan Network and Elman Network
6.1 循环神经网络:Jordan Network and Elman Network
正如第四章内容所述:Hopfield网络被认为是一种循环神经网络,在hopfield中提到的循环其实指的是神经元之间的连接是双向的。(第四章:Hopfield网络概述)虽然这种形式和现在我们常提到的循环神经网络的定义有很大的不一样,但是它依旧被认为是循环神经网路的前身。
本章节介绍的Recurrent Neural Network是在1986年由Jordan提出:
如果一个网络有一个或多个循环,也就是说,如果有可能沿着一条从一个单元回到它本身的路径,那么这个网络就被称为循环网络。非循环网络没有循环。
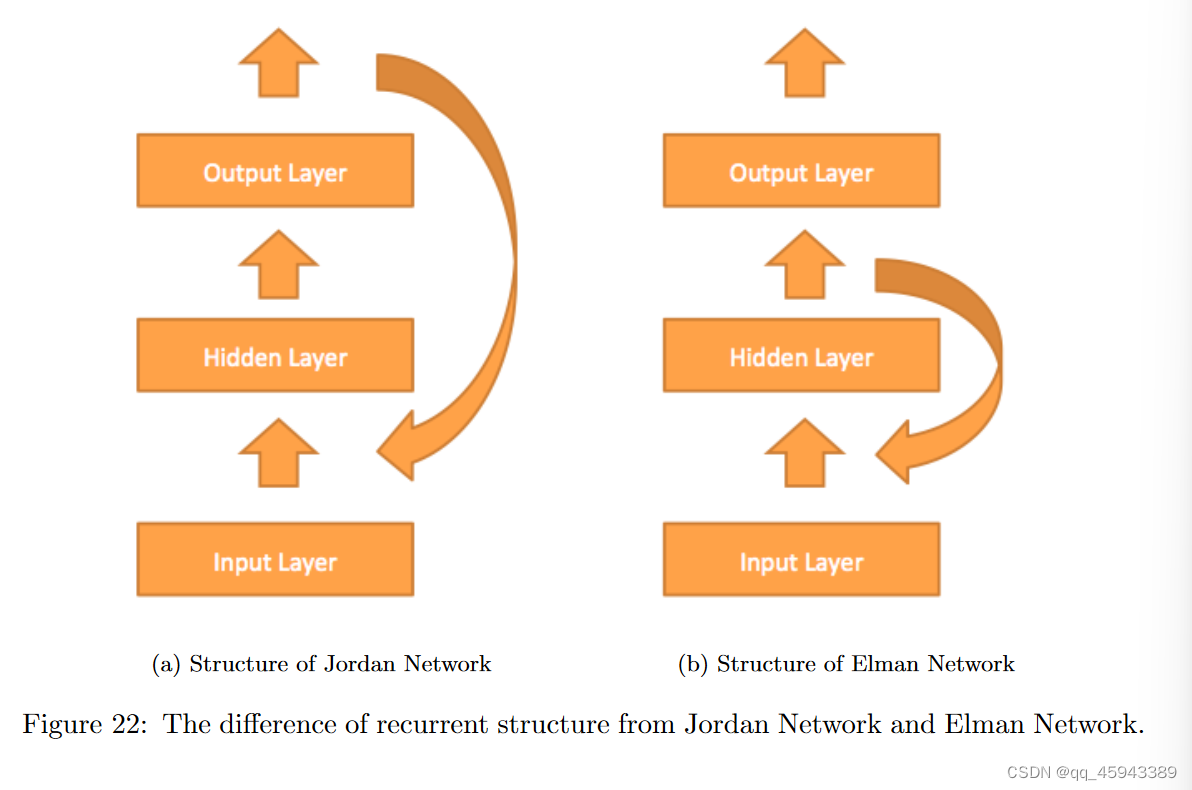
他提出的模型被称为:Jordan Network。 用公式语言来描述的话,Jordan Network可以写成如下的形式:其中输入为X,隐藏层的权重表示为Wh,输出层的权重表示为Wy,循环计算的权重为Wr,h指的是 隐藏的表示(hidden representation),最后的输出为y
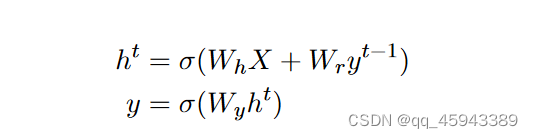
(注意:这里第t个时间的隐藏表示h 是对 上一时间的输出 进行循环计算的加权。之后对隐藏表示进行加权激活可以得到第t个时间的输出。
其实在这里可以多想一步:是否可以直接用上一个时间的隐藏表示来计算第t时间的隐藏表示,这样似乎更利于计算?
没错!在1990年就有Elman提出了另一种RNN,这种网络的公式化表示如下:
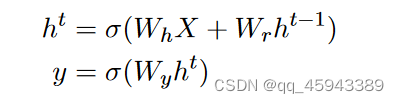
正如我们之前提到的!他们之间唯一不同的是,前一时间步的信息是由前一输出层提供变成了由前一隐含层提供。
作者也给出了这两种网络结构的形象化表示:
6.1.1 BPTT(随时间反向传播)
循环结构使得传统的反向传播不可行,因为在循环结构下,并不存在反向传播可以停止的终点。
一种解决方法是将循环结构展开(也就是如今我们常看到的循环神经网络的结构图.类似:O->O->O),并将其扩展为具有一定时间步长的前馈神经网络,然后将传统的反向传播应用到这个展开的神经网络上。这种方法就称为BackPropagation Trough Time(BPTT)
具体的公式展开的讲解可以看这个视频介绍:
6.2 双向循环神经网络(BRNN)
如果我们展开一个RNN,那么我们就可以得到一个具有无限深度的前馈神经网络的结构。因此,我们可以在RNN和具有无限层的前馈网络之间建立概念联系。那么,从神经网络的历史来看,双向神经网络一直扮演着重要的角色(如Hopfield网络、RBM、DBM等),随之而来的一个问题是,与双向模型的无限层相对应的循环结构是什么。答案是双向循环神经网络。
BRNN的目的是引入一种结构,使其展开为一个双向神经网络。因此,将其应用于时间序列数据时,不仅可以沿自然时间序列传递信息,而且进一步传递的信息还可以反向提供给前一时间步的知识。因此可以构造出下图的BRNN结构:
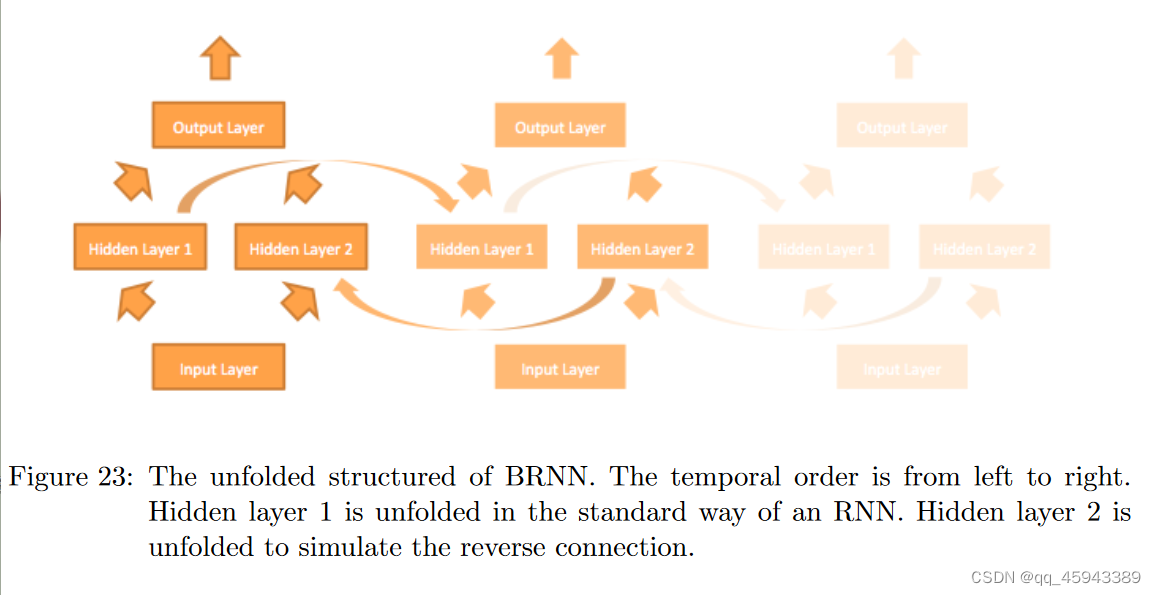
该图的时间顺序为从左到右,隐藏层1以RNN的标准方式展开(也就是当前隐藏层的输入中包含上一个时间的隐藏层输出。)隐藏层2展开后可以发现是为了进行反向传播。这里强调展开一个RNN只是一个概念,用于说明目的。实际BRNN模型采用同一单一模型处理不同时间步的数据。BRNN的形式化描述如下:
这里的1,2指的是隐藏层1,2。
随着从未来回溯的"循环"连接的引入,直接的BPTT也不再直接可行。解决方案是将该模型视为两个RNN的组合:一个标准的RNN和一个反向的RNN,然后将BPTT应用于其中的每个RNN。一旦计算两个梯度,权重将同时更新。
6.3 LSTM
RNN家族的另一个突破是在同年推出的BRNN——LSTM(long short-Term Memory)这个算法被提出来的时候是用于解决梯度消失的问题的。现在," LSTM "被广泛用于表示任何具有该记忆单元的循环网络,现将其称为LSTM单元。
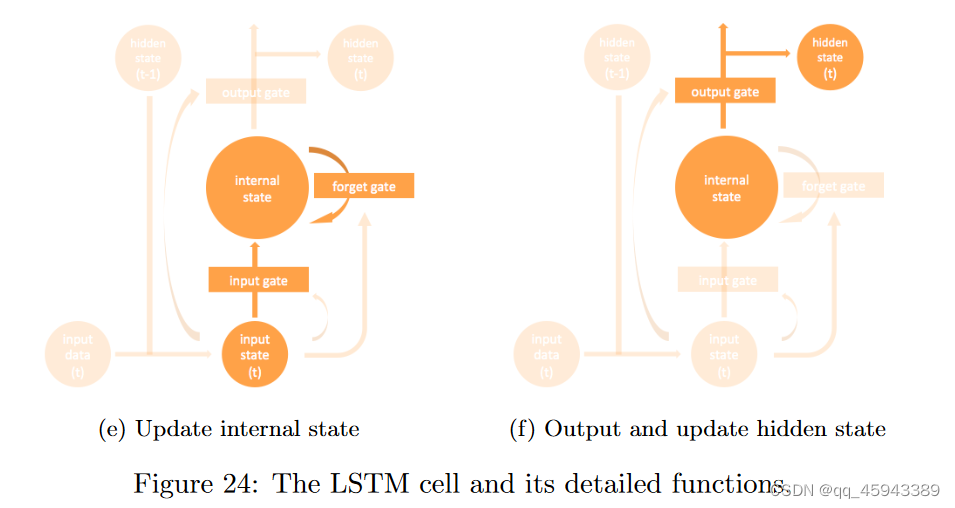
引入LSTM来克服RNNs无法长期依赖的问题。为了克服这个问题,它需要特别设计的存储单元,如图
LSTM中包含了几个重要的组件:
states:用于提供输出信息的值
输入数据:x
隐藏状态:前一个隐藏层的值。这与传统的RNN相同。记为h
输入状态:该值是隐藏状态和当前时间步输入的(线性)组合。记为i,则有:
在(a)图中对应的部分为:
内部状态:作为"记忆"的值。记为m
gates:用于决定状态信息流的值
输入门:它决定输入状态是否进入内部状态。记为g,则有
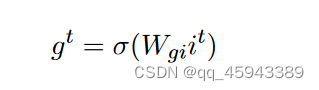
遗忘门:它决定内部状态是否遗忘先前的内部状态。记为f,则有:
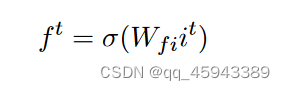
输出门:决定内部状态是否将其值传递给下一时间步的输出和隐藏状态。记为o,我们有:
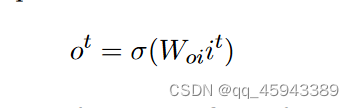
在(a)中对应的部分为:
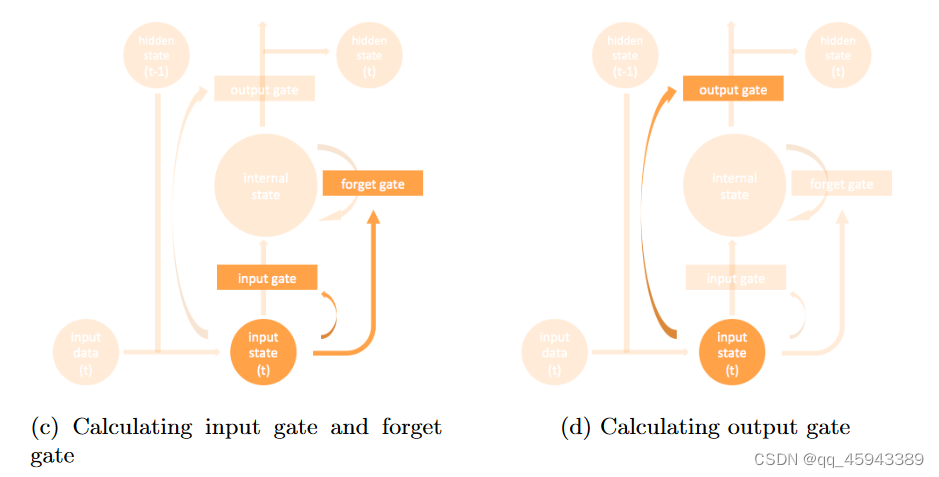
最后,考虑到门如何决定状态的信息流,我们有最后两个方程来完成LSTM的制定:
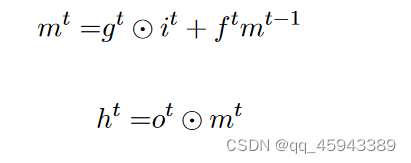
这里的![]() 代表element-wise product
代表element-wise product
所有的权重都是在训练过程中需要学习的参数。因此,从理论上讲,LSTM可以在必要时学习记忆长时间的依赖关系,在必要时可以学习遗忘过去,使其成为一个强大的模型。
在这一重要的理论保证下,许多工作尝试对LSTM进行改进。例如,增加一个窥视孔连接,允许门使用来自内部状态的信息。引入门控循环单元( Gated Recurrent Unit,GRU ),通过将内部状态和隐藏状态合并为一个状态,并将遗忘门和输入门合并为一个简单的更新门来简化LSTM。
有趣的是,尽管新的LSTM变体不断涌现,Greff等人( 2015 )对LSTM的性能进行了大规模的实验研究,得出的结论是没有一种变体可以显著地改进标准的LSTM结构。可能LSTM的改进是在另一个方向上,而不是更新细胞内部的结构。注意力模型似乎是一个需要努力的方向
6.4 Attention Models
注意力模型基于一种仿生设计来模拟人类视觉注意机制的行为:当人类注视一幅图像时,我们不是逐点扫描,也不是盯着整幅图像,而是关注其中的某个主要部分,并在抓住主旨后逐步构建上下文。注意机制最早是由拉罗谢勒和Hinton ( 2010 )以及Denil et al ( 2012 )讨论的。注意力模型主要是指( Bahdanau et al , 2014)中引入的用于机器翻译的模型,并很快应用于许多不同的领域,如用于语音识别的( Chorowski et al , 2015)和用于图像描述生成的( Xu et al . , 2015)。
注意力模型多用于序列输出预测。在机器翻译或图像描述生成等任务中,模型需要对序列输入进行序列预测,而不是看到整个序列数据并进行单次预测(例如,语言模型)。因此,注意力模型多用于回答基于先前预测的标签或隐藏状态在哪里需要关注的问题。
输出序列可能不必与输入序列一一对应,输入数据甚至不一定是序列。因此,通常需要一个编码器-解码器框架( Cho et al , 2015)。编码器用于将数据编码成表示,解码器用于进行序列预测。注意力机制用于定位表示的一个区域,用于预测当前时间步的标签。
编码器-解码器网络结构下的基本注意力模型。表示编码器的编码都可用于注意力模型,注意力模型只选择一些区域传递到LSTM单元,以进一步用于预测
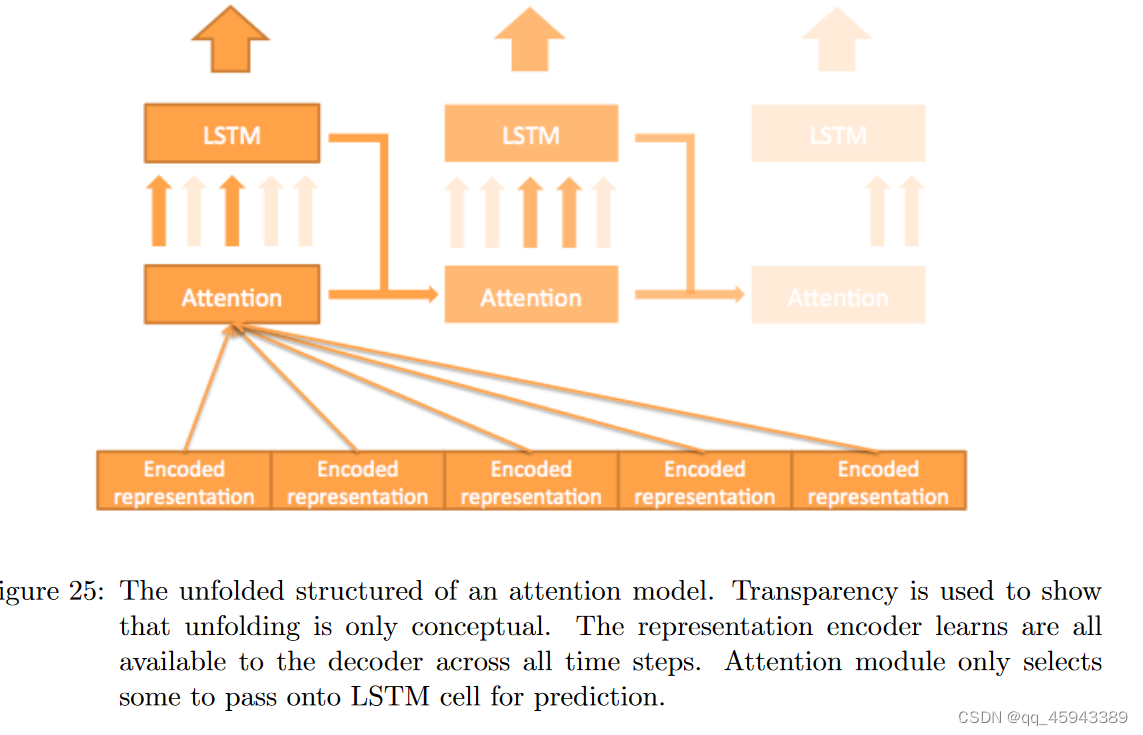
透明度被用来表明展开只是概念性的。编码器学习到的表示在所有时间步骤中都可供解码器使用。注意力模块只选择部分传递给LSTM单元进行预测。
因此,所有注意力模型的关键部分都是关于上图中的注意力模块如何有助于信息表示的本地化。为了形式化其工作原理,我们用r表示编码表示(共有M个代表性区域),用h表示LSTM单元的隐藏状态。然后,注意力模块可以为编码表示的第i个区域生成未缩放的权重为:(也就是接受编码表示,上一个时间的隐藏状态以及上一个时间的注意力权重,作为第t时刻的注意力模块
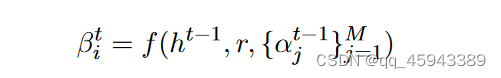

因此,我们可以进一步使用权重α对表示r进行重加权来进行预测。对表示进行重加权有两种方式:软注意力:结果是上下文向量的简单加权和,使得:
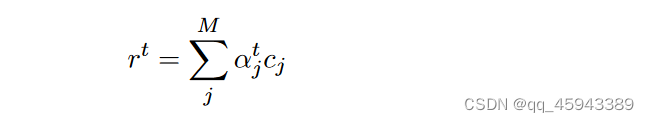
硬注意:模型被迫做出硬决策,只定位一个区域:将一个区域按照多核分布采样出来
硬注意的一个问题是,从多元分布中采样是不可微的。因此,基于梯度的方法很难应用。可以考虑使用变分法( Ba et al , 2014)或基于政策梯度的方法( Sutton et al , 1999)。
6.5 Deep RNN 和RNN的未来
尽管循环神经网络由于其循环连接的特性而受到了深度神经网络的诸多问题的困扰,但与其他家族的模型相比,目前的循环神经网络仍然不是表示学习的深度模型、、图26展示了三个不同的方向来构建深度RNN,分别通过增加输入分量(图26 ( a )) )、循环分量(图26 ( b )) )和输出分量(图26 ( c )) )的层数来构建深度循环神经网络。
 训练RNNs最基本的问题之一是梯度消失/爆炸问题,在( Bengio et al , 1994)中有详细介绍。该问题基本指出,对于传统的激活函数,梯度是有界的。当按照链式规则反向传播计算梯度时,误差信号在BPTT可回溯的时间步长内呈指数衰减,因此失去了长期依赖性。LSTM和ReLU是已知的解决消失/爆炸梯度问题的好方法。然而,这些解决方案引入了通过巧妙设计绕过这个问题的方法,而不是从根本上解决这个问题。尽管这些方法在实际应用中效果良好,但一般RNN的基本问题仍有待解决。帕斯卡努等( 2013b )尝试了一些解决方法,但仍有许多工作要做。
训练RNNs最基本的问题之一是梯度消失/爆炸问题,在( Bengio et al , 1994)中有详细介绍。该问题基本指出,对于传统的激活函数,梯度是有界的。当按照链式规则反向传播计算梯度时,误差信号在BPTT可回溯的时间步长内呈指数衰减,因此失去了长期依赖性。LSTM和ReLU是已知的解决消失/爆炸梯度问题的好方法。然而,这些解决方案引入了通过巧妙设计绕过这个问题的方法,而不是从根本上解决这个问题。尽管这些方法在实际应用中效果良好,但一般RNN的基本问题仍有待解决。帕斯卡努等( 2013b )尝试了一些解决方法,但仍有许多工作要做。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









