






优秀是一种习惯
- 知识点01:回顾
- 知识点02:目标
- 知识点03:MR的功能及应用场景
- 知识点04:MR的运行阶段:Input与Output
- 知识点05:MR的运行阶段:Map
- 知识点06:MR的运行阶段:Shuffle
- 知识点07:MR的运行阶段:Reduce
- 知识点08:WordCount的实现过程解析
- 知识点09:MR的编程规则:类与方法
- 知识点10:MR的编程规则:数据结构与类型
- 知识点11:MR的编程模板:Driver
- 知识点12:MR的编程规则:Mapper与Reducer
- 知识点13:WordCount开发:Driver
- 知识点14:WordCount开发:Mapper与Reducer
- 知识点15:WordCount开发:集群运行及本地运行
- 知识点16:MR实现二手房个数统计
- 练习:使用MR统计各个地区二手房的平均单价
- 附录一:MapReduce编程依赖
知识点01:回顾
-
如果NN只修改内存元数据,NN一旦故障重启,内存元数据丢失?
- 通过记录操作日志的方式来解决
- 将内存中的变化写入edits文件中
- NameNode启动时候,会将fsimage与edits文件进行合并
-
SecondaryNameNode的功能是什么?
- 功能:周期性将edits与fsimage文件进行合并生成最新的元数据文件
- NameNode每次启动加载最新的fsimage与最新的edits
- 功能:周期性将edits与fsimage文件进行合并生成最新的元数据文件
-
如何通过Java API构建HDFS连接?如何创建目录、删除文件?如何打开文件和创建文件?
- 类
- FileSystem:文件系统类
- Configuration:配置文件管理
- 方法
- mkdir(path,recursive)
- delete
- open(path) => InputStream
- create(path) => OutputStream
- 类
-
Hadoop主节点单点故障问题怎么解决?单个NameNode负载较高怎么解决?
- HA高可用机制:多个主节点,但只有一个是Active工作状态的
- 联盟机制:多个主节点,多个主节点一起工作
-
两个NameNode,如何决定谁是Active,谁是Standby,如何实现的?
- 进程:ZKFC
- 功能:监听每个NameNode的状态,实现辅助NameNode的状态向ZK进行注册或者监听
- 实现:每个ZKFC会根据NameNode状态在ZK中创建临时节点,谁创建成功,谁就是Active,Standby要监听这个临时节点
-
只有元数据一致,Active宕机或者故障,Standby才能完整的接替原来的Active,如何保证两个NameNode的内存元数据是一致的?
- 进程:JournalNode集群
- 设计:类似于ZK,可以实现大文件的存储
-
什么是脑裂问题,Hadoop如何解决的?
-
现象:出现两个Active的NameNode
-
原因:Active的ZKFC故障或者因为网络问题
-

-
解决
-
zkfc创建节点:临时节点file1,永久节点file2
-
如果active的zkfc1故障,file1自动删除,file2还在
-
zkfc2发现file2还在,就知道NameNode1可能还是Active状态
-
zkfc2会让NameNode2成为Active,通过隔离机制将NameNode1强制转换为Standby或者强制下线
-

知识点02:目标
- MapReduce介绍
- 功能
- 应用场景
- 运行阶段【核心】
- ||
- 决定了代码的处理逻辑
- MapReduce编程规则
- 本质:一套分布式编程的API
- 类和方法
- 数据结构和数据类型
- ||
- 决定了代码的开发规范
- 案例的开发
- WordCount
- 二手房分析统计
知识点03:MR的功能及应用场景
- 目标:掌握MapReduce的功能及应用场景
- 什么是MapReduce?
- 工作中什么场景下需要使用MapReduce?
- 路径
- step1:MapReduce的功能
- step2:MapReduce的设计思想
- step3:MapReduce的应用场景
- 实施
- MapReduce的功能
- 官方:基于yarn之上的大数据并行计算的框架
- 理解:这是一套分布式编程的API,制定了分布式计算的规则,定义了程序应该怎么分布式运行
- 不用自己写分布式程序,只要调用MapReduce的API写出来的程序就是分布式程序
- 举例
- 需求:1加到9
- |
- 通过MapReduce的API实现处理逻辑:1 +…… + 9
- |
- Mapreduce自动变成分布式程序
- |
- Map阶段
- MapTask1:1+2+3
- MapTask2:4+5+6
- MapTask3:7+8+9
- Reduce阶段
- ReduceTask = MapTask1 + MapTask2 + MapTask3
- MapReduce的设计思想
- 分布式分而治之的思想
- 分:Map阶段
- 合:Reduce阶段
- MapReduce的应用场景
- 适合:离线大数据的分布式计算
- 不适合:实时的高性能的分布式计算场景
- 实际工作中:现在很少使用MapReduce了,都使用Spark来替代了MapReduce
- 哪怕用,也不是直接写代码,一般都是通过SQL自动转换为MapReduce
- 学习MapReduce核心
- 不在于整个MapReduce代码
- 在MapReduce设计思想和实现过程
- MapReduce的功能
- 小结
- 什么是MapReduce?
- MapReduce就是一套分布式编程的API
- 工作中什么场景下需要使用MapReduce?
- 一般不写代码,通过SQL来转换为MapReduce,重点掌握MapReduce的设计思想
- 什么是MapReduce?
知识点04:MR的运行阶段:Input与Output
-
目标:掌握MapReduce中Input与Output的功能
- MapReduce运行一共几个阶段?
- MapReduce是如何读取数据的?
- MapReduce是如何保存结果的?
-
路径
- step1:MapReduce的五大阶段
- step2:Input的功能及实现
- step3:Output的功能及实现
-
实施
-
MapReduce的五大阶段
- 大的分:Map阶段、Reduce阶段
- 细的分:五大阶段
- Input:负责读取程序中的数据
- Map、Shuffle、Reduce:负责数据的处理
- Output:负责保存计算的结果
-
Input的功能及实现
-
功能:负责读取整个程序的输入
- 将文件、数据库中的数据读取到程序中
-
实现:InputFormat
- step1:将读取到的数据进行分片,切分为多个Split
-
-

-
step2:将每个分片中每一条数据转换为KV结构,返回每条数据
-
不同的实现类返回的KV不一样
-
默认的类:TextInputFormat extends FIleInputFormat extends InputFormat
-
功能:读文件
-
返回
-
K:Long:这一行的偏移量
-
V:String:这一行的内容
-
-
-
-
-
Output的功能及实现
- 功能:将上一步处理的结果【Map/Reduce】进行保存输出
- 文件、数据库
- 实现:OutputFormat
- step1:调用对应输出类的方法将结果进行方法
- 默认:TextOutputFormat extends FileOutputFormat extends OutputFormat
- 功能:将K和V写入文件中,K和V在文件中用制表符分隔
- 功能:将上一步处理的结果【Map/Reduce】进行保存输出
-
小结
- MapReduce是如何读取数据的?
- 输入类:InputFormat
- 实现功能一:将读取到的数据进行分片
- 实现功能二:将每一条转换为键值对KV结构
- 默认:TextInputFormat
- K:行的偏移量
- V:行的内容
- MapReduce是如何保存结果的?
- 输出类:OutputFormat
- 实现功能:将上一步处理的结果KV结构进行保存
- 默认:TextOutputFormat
- 将结果的KV写入文件
- K与V用制表符分隔
- MapReduce是如何读取数据的?
知识点05:MR的运行阶段:Map
- 目标:掌握MapReduce中Map的功能
- Map的功能是什么?
- Map过程是如何实现的?
- 路径
- step1:Map的功能
- step2:Map实现的过程
- 实施
-
Map的功能
- 功能:实现分布式计算的分
-
Map实现的过程
- step1:根据Input阶段划分的Split,每个Split会启动一个MapTask进程来处理对应Split的数据
- MapTask处理每个分片中的KV结构的数据
- step2:每个MapTask进程会构建一个Mapper类实例,调用Mapper类中的map方法对每个分片的数据进行处理
- 处理逻辑:Mapper类的map方法决定,每一条KV会调用一次map方法
- 参数:KV
- 处理逻辑:Mapper类的map方法决定,每一条KV会调用一次map方法
- step1:根据Input阶段划分的Split,每个Split会启动一个MapTask进程来处理对应Split的数据
-

- 小结
- Map阶段的功能是什么?
- 实现分布式的分
- Map过程是如何实现的?
- 每个Split会启动一个MapTask进行处理
- 每个MapTask进程会实例化一个Mapper类的对象,代用Mapper类的map方法对分片中的每一条数据进行处理
- Map阶段的功能是什么?
知识点06:MR的运行阶段:Shuffle
-
目标:了解MapReduce中Shuffle的功能
-
实施
-
功能:对Map以后的数据进行分组处理,MapReduce中定死的过程
- 分区
- 排序
- 分组
-
实现目的:分布式的分组
-
前面的过程
- Input
- 读取数据,返回KV
- K1V1
- Map
- 输入:K1V1
- 输出:K2V2
- Input
-
排序:默认按照K2进行升序排序
-
排序是为了加快分组的效率
-
不排序
1 2 3 4 1 2 3 4 -
排序
1 1 2 2 3 3 4 4
-
-
-
分组:默认按照K2进行分组
- 相同K2 的所有V2在逻辑上属于同一组
-
-
-
小结
- Shuffle的功能是什么?
- 功能:分区、排序、分组
- 排序:按照K2升序排序
- 分组:按照K2分组
- Shuffle的功能是什么?
知识点07:MR的运行阶段:Reduce
- 目标:掌握MapReduce中Reduce的功能
- Reduce的功能是什么?
- Reduce过程是如何实现的?
- 路径
- step1:Reduce的功能
- step2:Reduce实现的过程
- 实施
- Reduce的功能
- 实现分布式的合的
- 理解:Reduce就是一个没有定义的功能的聚合函数,将所有Map的数据的进行聚合
- Reduce实现的过程
- step1:默认情况会启动1个ReduceTask进程对Shuffle逻辑分组以后的结果进行聚合
- step2:ReduceTask会实例化一个Reducer的类的对象,调用reduce方法对每一组数据进行聚合
- 聚合的逻辑:由reduce方法决定
- Reduce的功能
- 小结
- Reduce的功能是什么?
- 实现分布式的合,将所有Map的数据进行聚合
- Reduce过程是如何实现的?
- 启动ReduceTask进程,默认只启动1个
- 实例化Reducer类的对象,调用reduce方法实现聚合,每一组调用一次
- Reduce的功能是什么?
知识点08:WordCount的实现过程解析
-
目标:掌握MR计算WordCount的实现过程
-
实施
-
HDFS输入文件:wordcount.txt
hadoop hive spark hbase hadoop hadoop spark hive hbase hadoop spark -
Input
-
默认:TextInputFormat
-
step1:将数据分片
-
split1
hadoop hive spark hbase hadoop hadoop -
split2
spark hive hbase hadoop spark
-
-
step2:转换为K1V1
-
split1
K V 0 hadoop hive spark 33 hbase hadoop hadoop -
split2
K V 0 spark hive 20 hbase hadoop spark
-
-
-
Map
-
读取K1V1
-
处理
-
MapTask1 => Split1
-
MapTask2 => Split2
-
对每条数据调用map方法
public void map(Long K1,String V1){ String[] words = V1.split(" ") for(word:words){ output(word,1) } }
-
-
输出K2V2
-
MapTask1
K2 V2 hadoop 1 hive 1 spark 1 hbase 1 hadoop 1 hadoop 1 -
MapTask2
spark 1 hive 1 hbase 1 hadoop 1 spark 1
-
-
-
Shuffle
-
排序:按照K2排序
hadoop 1 hadoop 1 hadoop 1 hadoop 1 hbase 1 hbase 1 hive 1 hive 1 spark 1 spark 1 spark 1 -
分组:按照K2分组,结果是按照单词分组,所以K2是单词
hadoop <1,1,1,1> hbase <1,1> hive <1,1> spark <1,1,1>
-
-
Reduce
-
读取分组的K2V2
-
聚合处理:reduce
public void reduce(String k2,Iter<V2> value){ sum = 0 for(int v : value){ sum += v } output(K2,sum) } -
输出K3V3
K3 V3 hadoop 4 hbase 2 hive 2 spark 3
-
-
Output
-
默认:TextOutputFormat
-
将K3V3保存
-
-
HDFS结果文件:part-r-00000
hadoop 4 hbase 2 hive 2 spark 3
-
-
小结
-
掌握每个过程中的每个阶段的功能与结果

-



知识点09:MR的编程规则:类与方法
- 目标:掌握MR编程规则中的类与方法
- MapReduce的API中会用到哪些类和方法?
- 路径
- step1:Driver类
- step2:Input类
- step3:Mapper类
- step4:Reducer类
- step5:Output类
- 实施
- Driver类
- 驱动类:作为程序运行的入口类
- 规则:推荐extends Configured implement Tool
- 方法
- main:作为程序的运行入口
- run:用于构建、配置、提交MapReduce Job
- 要自己开发
- Input类
- 输入:InputFormat
- 默认:TextInputFormat,读文件,K1是行的偏移量,V1是行的内容
- 其他
- DBInputFormat:读数据库的
- TableInputFormatFormat:读Hbase
- 不用自己开发
- Mapper类
- 功能:在Map阶段,构建实例化,调用map方法对数据进行处理
- 规则:必须 extends Mapper
- 方法:重写map方法
- 要自己开发
- Reducer类
- 功能:在Reduce阶段,构建实例化,调用reduce方法对数据进行处理
- 规则:必须 extends Reducer
- 方法:重写reduce方法
- 要自己开发
- Output类
- 输出:OutputFormat
- 默认:TextOutputFormat,写文件,将K3和V3保存到文件中
- 其他
- DBOutputFormat:写数据库
- TableOutputFormat:写Hbase
- 不要自己写
- Driver类
- 小结
- MapReduce的API中会用到哪些类和方法?
知识点10:MR的编程规则:数据结构与类型
- 目标:掌握MR编程规则中的数据结构与数据类型
- MapReduce中的数据以什么结构存在?
- MapReduce中的数据以什么类型存储?
- 路径
- step1:MR中的数据结构
- step2:MR中的数据类型
- 实施
- MR中的数据结构
- 键值对:所有的数据都以KV形式存在
- Input:将各种数据变成K1V1
- Map:读K1V1输出K2V2
- Reduce:读K2V2输出K3V3
- Output:保存K3V3
- MR中的数据类型
- Hadoop中使用的类型不能使用Java中原生的基本类型和引用类型,因为Hadoop中的类型必须支持序列化
- 分布式计算:对象的网络传递,必须支持序列化
- Hadoop中自带了很多的序列化类型,用于提供
- Java:int、String、long、double、Boolean、null
- Hadoop
- IntWritable
- Text
- LongWritable
- DouleWritable
- BooleanWritable
- NullWritable
- MR中的数据结构
- 小结
- MapReduce中的数据以什么结构存在?
- KV结构
- MapReduce中的数据以什么类型存储?
- 所有KV必须使用Hadoop中的序列化类型
- MapReduce中的数据以什么结构存在?
知识点11:MR的编程模板:Driver
-
目标:实现MR编程模板中Driver类的开发
-
实施
package bigdata.itcast.cn.hadoop.mr.mode; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * @ClassName MRDriverMode * @Description TODO MapReduce编程模板,Driver类 * @Date 2021/4/26 14:31 * @Create By Frank */ public class MRDriverMode extends Configured implements Tool { //构建、配置、提交Job public int run(String[] args) throws Exception { /** * step1:构建Job */ //实例化一个MapReduce的Job对象 Job job = Job.getInstance(this.getConf(),"mode"); //指定允许jar包运行的类 job.setJarByClass(MRDriverMode.class); /** * step2:配置Job */ //Input:配置输入 //指定输入类的类型 job.setInputFormatClass(TextInputFormat.class);//可以不指定,默认就是TextInputFormat //指定输入源 Path inputPath = new Path(args[0]);//使用第一个参数作为程序的输入 TextInputFormat.setInputPaths(job,inputPath); //Map:配置Map job.setMapperClass(MRMapperMode.class); //设置调用的Mapper类 job.setMapOutputKeyClass(Text.class); //设置K2的类型 job.setMapOutputValueClass(Text.class); //设置V2的类型 //Shuffle:配置Shuffle // job.setPartitionerClass(null); //设置分区器 // job.setSortComparatorClass(null); //设置排序器 // job.setGroupingComparatorClass(null); //设置分组器 // job.setCombinerClass(null); //设置Map端聚合 //Reduce:配置Reduce job.setReducerClass(MRReducerMode.class); //设置调用reduce的类 job.setOutputKeyClass(Text.class); //设置K3的类型 job.setOutputValueClass(Text.class); //设置V3的类型 // job.setNumReduceTasks(1); //设置ReduceTask的个数,默认为1 //Output:配置输出 //指定输出类的类型 job.setOutputFormatClass(TextOutputFormat.class);//默认就是TextOutputFormat //设置输出的路径 Path outputPath = new Path(args[1]); //判断输出是否存在,存在就删除 FileSystem fs = FileSystem.get(this.getConf()); if(fs.exists(outputPath)){ fs.delete(outputPath,true); } TextOutputFormat.setOutputPath(job,outputPath); /** * step3:提交Job */ return job.waitForCompletion(true) ? 0 : -1; } //程序的入口方法 public static void main(String[] args) throws Exception { //构建配置管理对象 Configuration conf = new Configuration(); //通过工具类的run方法调用当前类的实例的run方法 int status = ToolRunner.run(conf, new MRDriverMode(), args); //退出程序 System.exit(status); } } -
小结
- Driver类的开发规则是什么?
- 继承Configured
- 实现Tool
- 需要实现哪些方法?
- main:程序入口,调用run方法
- run:构建、配置、提交Job
- Driver类的开发规则是什么?
知识点12:MR的编程规则:Mapper与Reducer
-
目标:实现MR编程模板中Mapper类和Reducer类的开发
-
实施
-
Mapper类
package bigdata.itcast.cn.hadoop.mr.mode; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * @ClassName MRMapperMode * @Description TODO MapReduce模板 - Mapper类 * Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> * 输入的KV类型:由输入类的类型决定 * KEYIN * VALUEIN * 输出的KV类型:由map方法 * KEYOUT * VALUEOUT * @Date 2021/4/26 15:08 * @Create By Frank */ public class MRMapperMode extends Mapper<LongWritable, Text,Text,Text> { /** * 每一条K1V1会调用一次map方法,实现处理,得到K2V2 * @param key:K1 * @param value:V1 * @param context:上下文对象,负责管理整个程序的数据传递等等 * @throws IOException * @throws InterruptedException */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //处理的逻辑由实际的需求决定 } } -
Reduce类
package bigdata.itcast.cn.hadoop.mr.mode; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * @ClassName MRMapperMode * @Description TODO MapReduce模板 - Mapper类 * Mapper<KEYIN, VALUEIN, KEYOUT, VALUEOUT> * 输入的KV类型:由输入类的类型决定 * KEYIN * VALUEIN * 输出的KV类型:由map方法 * KEYOUT * VALUEOUT * @Date 2021/4/26 15:08 * @Create By Frank */ public class MRMapperMode extends Mapper<LongWritable, Text,Text,Text> { /** * 每一条K1V1会调用一次map方法,实现处理,得到K2V2 * @param key:K1 * @param value:V1 * @param context:上下文对象,负责管理整个程序的数据传递等等 * @throws IOException * @throws InterruptedException */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //处理的逻辑由实际的需求决定 } }
-
-
小结
- Mapper类的规则是什么以及要实现什么方法?
- 继承Mapper类,重写map(k1,v1,context)方法
- Reducer类的规则是什么以及要实现什么方法?
- 继承Reduce类,重写reduce(k2,Iter,context)方法
- Mapper类的规则是什么以及要实现什么方法?
知识点13:WordCount开发:Driver
-
目标:实现WordCount程序中Driver类的开发
-
实施
package bigdata.itcast.cn.hadoop.mr.wordcount; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; /** * @ClassName WordCountDriver * @Description TODO 自定义开发程序实现Wordcount词频统计 * @Date 2021/4/26 15:33 * @Create By Frank */ public class WordCountDriver extends Configured implements Tool { public int run(String[] args) throws Exception { //构建 Job job = Job.getInstance(this.getConf(),"userwc"); job.setJarByClass(WordCountDriver.class); //配置 job.setInputFormatClass(TextInputFormat.class); //使用程序的第一个参数作为输入 TextInputFormat.setInputPaths(job,new Path(args[0])); job.setMapperClass(WordCountMapper.class); job.setMapOutputKeyClass(Text.class); job.setMapOutputValueClass(IntWritable.class); job.setReducerClass(WordCountReducer.class); job.setOutputKeyClass(Text.class); job.setOutputValueClass(IntWritable.class); job.setOutputFormatClass(TextOutputFormat.class); //使用程序的第二个参数作为输出路径 Path outputPath = new Path(args[1]); FileSystem fs = FileSystem.get(this.getConf()); if(fs.exists(outputPath)){ fs.delete(outputPath,true); } TextOutputFormat.setOutputPath(job,outputPath); //提交 return job.waitForCompletion(true) ? 0 : -1; } public static void main(String[] args) throws Exception { Configuration conf = new Configuration(); int status = ToolRunner.run(conf, new WordCountDriver(), args); System.exit(status); } } -
小结
- 参考代码实现即可
知识点14:WordCount开发:Mapper与Reducer
-
目标:实现WordCount程序中Mapper类和Reducer类的开发
-
实施
-
Mapper类
package bigdata.itcast.cn.hadoop.mr.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Mapper; import java.io.IOException; /** * @ClassName WordCountMapper * @Description TODO Wordcount Mapper类 * @Date 2021/4/26 15:44 * @Create By Frank */ public class WordCountMapper extends Mapper<LongWritable, Text,Text, IntWritable> { //输出的K2 Text outputKey = new Text(); //输出的V2 IntWritable outputValue = new IntWritable(1); /** * 每条KV调用一次map * @param key:行的偏移量 * @param value:行的内容 * @param context * @throws IOException * @throws InterruptedException */ @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //将每行的内容分割得到每个单词 String[] words = value.toString().split("\\s+"); //迭代取出每个单词作为K2 for (String word : words) { //将当前的单词作为K2 this.outputKey.set(word); //将K2和V2传递到下一步 context.write(outputKey,outputValue); } } } -
Reducer类
package bigdata.itcast.cn.hadoop.mr.wordcount; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Reducer; import java.io.IOException; /** * @ClassName WordCountReducer * @Description TODO 自定义开发WordCount -Reducer * @Date 2021/4/26 15:52 * @Create By Frank */ public class WordCountReducer extends Reducer<Text, IntWritable,Text, IntWritable> { //输出K3 // Text outputKey = new Text(); //输出V3 IntWritable outputValue = new IntWritable(); /** * 每一组调用一次 * @param key:单词 * @param values:所有相同单词对应的1 * @param context * @throws IOException * @throws InterruptedException */ @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { //取出当前单词所有 1,进行累加 sum += value.get(); } //给V3赋值 this.outputValue.set(sum); //传递到下一步 context.write(key,this.outputValue); } }
-
-
小结
- 参考代码实现即可
知识点15:WordCount开发:集群运行及本地运行
- 目标:实现WordCount程序的集群运行及本地环境测试运行
- 开发好的程序如何运行?
- 开发过程中如何做测试运行?
- 路径
- step1:集群模式分布式运行
- step2:本地模式测试运行
- 实施
-
集群模式分布式运行
-
打成jar包

-
上传到Linux中

-
使用yarn的客户端来提交运行
-
yarn语法
yarn jar 运行jar包的位置 你要运行的类 【类的参数】 -
实现
yarn jar /export/data/wordcount.jar bigdata.itcast.cn.hadoop.mr.wordcount.WordCountDriver /wordcount/input/wordcount.txt /wordcount/output4

-
-
-
本地模式测试运行
- step1:先配置本地环境:参考HDFS环境配置
- step2:直接右键单击运行
- 注意:如果将三个类放在一个文件中定义,Mapper和Reducer必须申明为static【硬性规定】
-
- 小结
- 开发好的程序如何运行?
- 打成jar包集群分布式运行
- 开发过程中如何做测试运行?
- 先本地测试
- 再打包集群运行测试
- 开发好的程序如何运行?
知识点16:MR实现二手房个数统计
-
目标:基于Mr实现各地区二手房个数的统计
-
路径
- step1:分析需求
- step2:代码实现
-
实施
-
分析需求
-
基于Mr实现各地区二手房个数的统计
-
step1:结果长什么样?
地区 个数 杨浦 300 虹口 400 …… -
step2:K2是谁
- 经过shuffle:只有K2才会被分区
- K2:地区
-
step3:V2是谁
- 标记为1,表示这个地区出现一套二手房
-
-
代码实现
package bigdata.itcast.cn.hadoop.mr.secondhouse; import bigdata.itcast.cn.hadoop.mr.mode.MRMapperMode; import bigdata.itcast.cn.hadoop.mr.mode.MRReducerMode; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.FileSystem; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.IntWritable; import org.apache.hadoop.io.LongWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.Reducer; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; import java.io.IOException; /** * @ClassName MRDriverMode * @Description TODO 各个地区二手房个数统计 * @Date 2021/4/26 14:31 * @Create By Frank */ public class SecondHouseCount extends Configured implements Tool { //构建、配置、提交Job public int run(String[] args) throws Exception { /** * step1:构建Job */ //实例化一个MapReduce的Job对象 Job job = Job.getInstance(this.getConf(),"second house numb"); //指定允许jar包运行的类 job.setJarByClass(SecondHouseCount.class); /** * step2:配置Job */ //Input:配置输入 //指定输入类的类型 job.setInputFormatClass(TextInputFormat.class);//可以不指定,默认就是TextInputFormat //指定输入源 Path inputPath = new Path("datas/lianjia/secondhouse.csv");//使用第一个参数作为程序的输入 TextInputFormat.setInputPaths(job,inputPath); //Map:配置Map job.setMapperClass(SecondMapper.class); //设置调用的Mapper类 job.setMapOutputKeyClass(Text.class); //设置K2的类型 job.setMapOutputValueClass(IntWritable.class); //设置V2的类型 //Shuffle:配置Shuffle // job.setPartitionerClass(null); //设置分区器 // job.setSortComparatorClass(null); //设置排序器 // job.setGroupingComparatorClass(null); //设置分组器 // job.setCombinerClass(null); //设置Map端聚合 //Reduce:配置Reduce job.setReducerClass(SecondReducer.class); //设置调用reduce的类 job.setOutputKeyClass(Text.class); //设置K3的类型 job.setOutputValueClass(IntWritable.class); //设置V3的类型 // job.setNumReduceTasks(1); //设置ReduceTask的个数,默认为1 //Output:配置输出 //指定输出类的类型 job.setOutputFormatClass(TextOutputFormat.class);//默认就是TextOutputFormat //设置输出的路径 Path outputPath = new Path("datas/output/second/output1"); //判断输出是否存在,存在就删除 FileSystem fs = FileSystem.get(this.getConf()); if(fs.exists(outputPath)){ fs.delete(outputPath,true); } TextOutputFormat.setOutputPath(job,outputPath); /** * step3:提交Job */ return job.waitForCompletion(true) ? 0 : -1; } //程序的入口方法 public static void main(String[] args) throws Exception { //构建配置管理对象 Configuration conf = new Configuration(); //通过工具类的run方法调用当前类的实例的run方法 int status = ToolRunner.run(conf, new SecondHouseCount(), args); //退出程序 System.exit(status); } public static class SecondMapper extends Mapper<LongWritable,Text,Text,IntWritable>{ //K2 Text outputKey = new Text(); //V2 IntWritable outputValue = new IntWritable(1); //梅园六街坊,2室0厅,47.72,浦东,低区/6层,朝南,500,104777,1992年建 @Override protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException { //取出地区 String region = value.toString().split(",")[3]; //地区作为K2 this.outputKey.set(region); //输出 context.write(this.outputKey,this.outputValue); } } public static class SecondReducer extends Reducer<Text,IntWritable,Text,IntWritable>{ //V3 IntWritable outputValue = new IntWritable(); @Override protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException { int sum = 0; for (IntWritable value : values) { sum += value.get(); } this.outputValue.set(sum); context.write(key,this.outputValue); } } }
-
-
小结
- 核心掌握MapReduce的五大阶段的功能
练习:使用MR统计各个地区二手房的平均单价
package cn.itheima.secondHouseAvgTest;
import cn.itheima.secondHouseAvg.JobTest;
import cn.itheima.secondHouseAvg.MapTask;
import cn.itheima.secondHouseAvg.ReducerTask;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.TextInputFormat;
import org.apache.hadoop.mapreduce.lib.output.TextOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import java.io.IOException;
public class SecondHouseAvg extends Configured implements Tool {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
int status = ToolRunner.run(conf, new SecondHouseAvg(), args);
System.exit(status);
}
@Override
public int run(String[] args) throws Exception {
Job job = Job.getInstance(this.getConf(), "secondAvg");
job.setJarByClass(SecondHouseAvg.class);
job.setInputFormatClass(TextInputFormat.class);
TextInputFormat.setInputPaths(job, new Path("C:\\Users\\User\\Desktop\\input\\secondhouse.csv"));
job.setMapperClass(cn.itheima.secondHouseAvg.MapTask.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
job.setReducerClass(cn.itheima.secondHouseAvg.ReducerTask.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setOutputValueClass(TextOutputFormat.class);
Path path = new Path("C:\\Users\\User\\Desktop\\output\\secondAvg");
FileSystem fs = FileSystem.get(this.getConf());
if (fs.exists(path)) {
fs.delete(path, true);
}
TextOutputFormat.setOutputPath(job, path);
return job.waitForCompletion(true) ? 0 : -1;
}
public static class MapTask extends Mapper<LongWritable, Text, Text, IntWritable> {
Text outputKey = new Text();
IntWritable outputValue = new IntWritable();
@Override
protected void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String area = value.toString().split(",")[3];
String price = value.toString().split(",")[7];
this.outputKey.set(area);
this.outputValue.set(new Integer(price));
context.write(this.outputKey, this.outputValue);
}
}
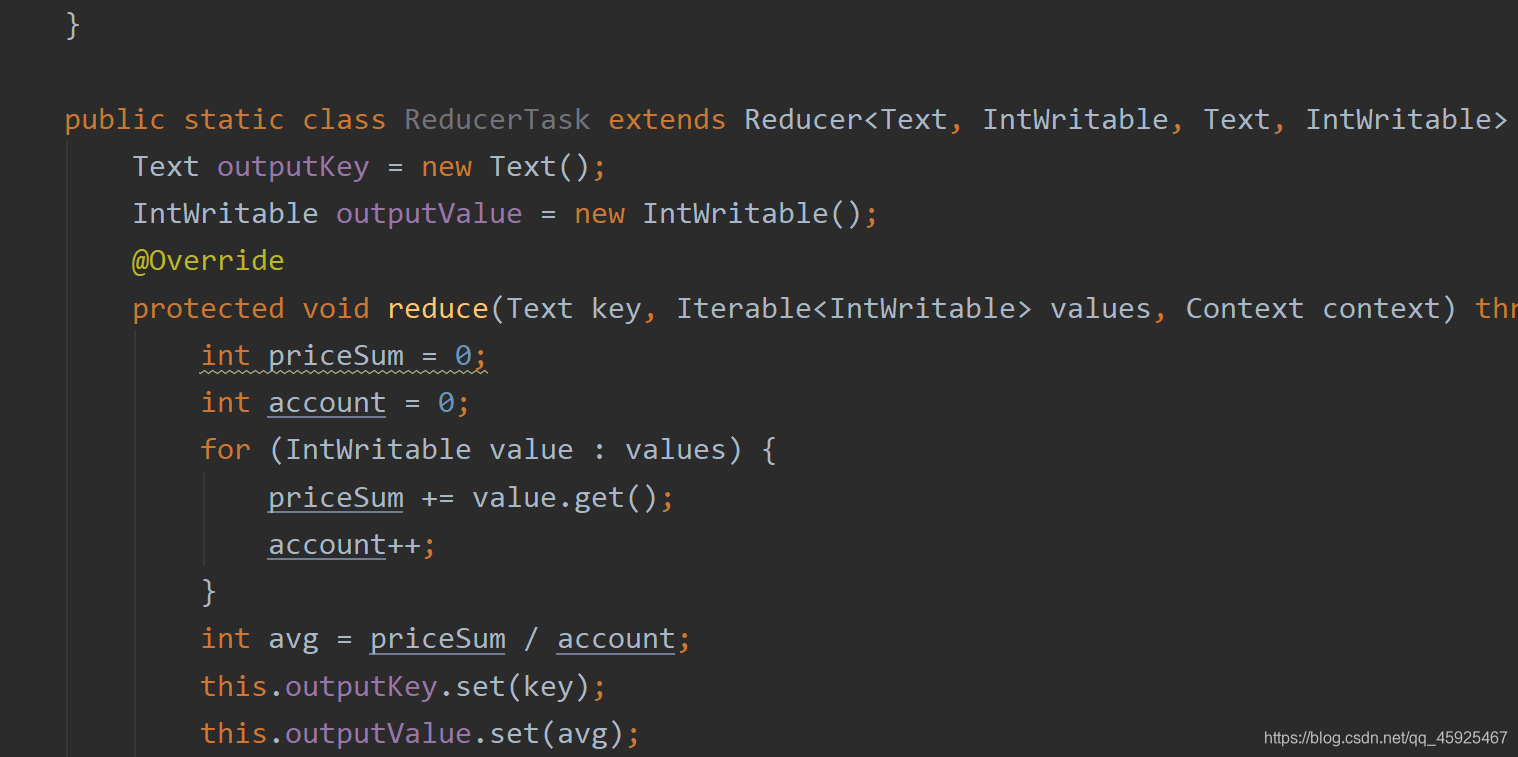
public static class ReducerTask extends Reducer<Text, IntWritable, Text, IntWritable> {
Text outputKey = new Text();
IntWritable outputValue = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int priceSum = 0;
int account = 0;
for (IntWritable value : values) {
priceSum += value.get();
account++;
}
int avg = priceSum / account;
this.outputKey.set(key);
this.outputValue.set(avg);
context.write(outputKey, outputValue);
}
}
}
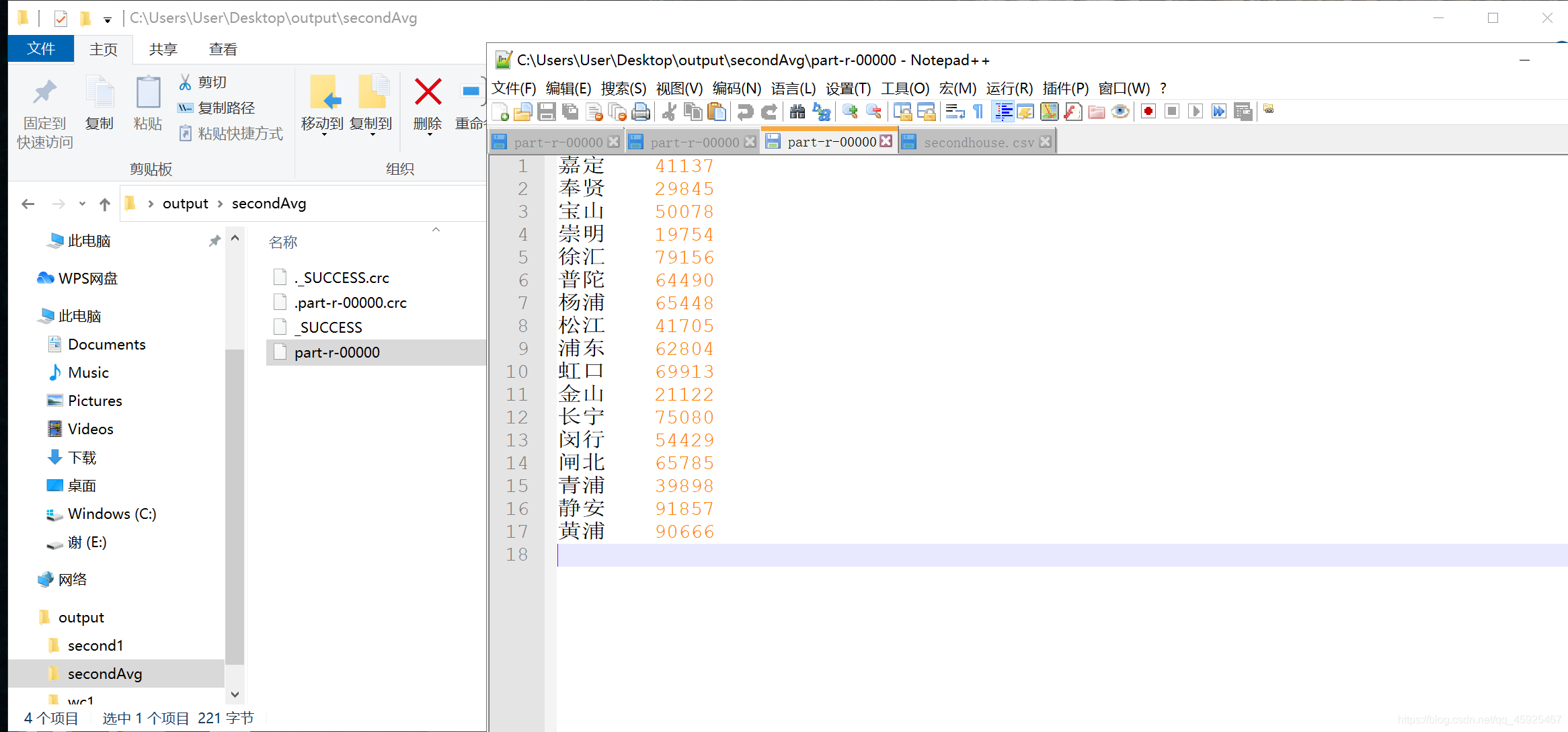
附录一:MapReduce编程依赖
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.7.5</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.13</version>
</dependency>
</dependencies>


















 691
691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











