









机器学习中的算法涉及诸多的优化问题,典型的就是利用梯度下降法(gradient descent)求使损失函数 J ( θ ) J(\theta) J(θ)下降的模型参数 θ \theta θ。
Bath Gradlient Descen (BGD)
采用整个训练集的数据来计算 cost function 对参数的梯度
梯度更新规则
θ = θ − η ∇ θ ( θ ) \theta = \theta-\eta\nabla_\theta(\theta) θ=θ−η∇θ(θ)
缺点
计算慢,遇到大量数据集棘手,不能投入新数据实时更新模型
代码
for i in range(nb_epochs):
params_grad = evaluate_gradient(loss_function, data, params)
params = params - learning_rate * params_grad
nb_epochs -> 事先定义的迭代次数
params_grad -> 梯度向量
沿梯度方向更新参数 params
learning_rate -> 学习速率
适用范围
Batch gradient descent 对于凸函数可以收敛到全局极小值,对于非凸函数可以收敛到局部极小值。
Stochastic Gradient Descent (SGD)
SGD 每次更新只对每个样本进行梯度更新
一次只进行一次更新 没有冗余 可以新增样本
梯度更新规则
θ = θ − η ∇ θ J ( θ ; x i ; y i ) \theta=\theta-\eta\nabla_\theta{J}(\theta;x^i;y^i) θ=θ−η∇θJ(θ;xi;yi)
缺点
噪音比BGD多,使得SGD并不是每次迭代都是向着整体最优方向,所以虽然训练速度快,但是准确度下降,并不是全局最优(cost function 震荡)
稍微减小 learning rate SGD 和 BGD的收敛性是一样的
代码
for i in range(nb_epochs):
np.random.shuffle(data)
for example in data:
params_grad = evaluate_gradient(loss_function, example, params)
params = params - learning_rate * params_grad
整体数据集加了一个对样本的循环
适用范围
BGD 可以收敛到局部极小值,当然 SGD 的震荡可能会跳到更好的局部极小值处。
Mini-Batch Gradient Descent (MBGD)
MBGD 每一次利用一小批样本,即n个样本进行计算
-
可以降低参数更新时的方差,收敛更稳定
-
方便用库中高度优化的矩阵操作来进行梯度的计算
梯度更新规则
θ = θ − η ∇ J ( θ ; x i : i + n ; y i : i + n ) \theta=\theta-\eta\nabla{J}(\theta;x^{i:i+n};y^{i:i+n}) θ=θ−η∇J(θ;xi:i+n;yi:i+n)
缺点
- 会在鞍点或者局部最小点震荡跳动,每次找到的梯度都是不同的,就会发生震荡,来回跳动。
- 需要挑选一个合适的学习率
代码
# n 一般取值在 50~256
for i in range(nb_epochs):
np.random.shuffle(data)
for batch in get_batches(data, batch_size=50):
params_grad = evaluate_gradient(loss_function, batch, params)
params = params - learning_rate * params_grad
适用范围
同SGD
Momentun
动量算法积累了之前梯度指数级衰减的移动平均,并且继续沿该方向移动。从形式上看,动量算法引入了变量 v v v 充当速度角色-代表参数在参数空间移动的方向和速率,速度被认为是负梯度的指数衰减平均
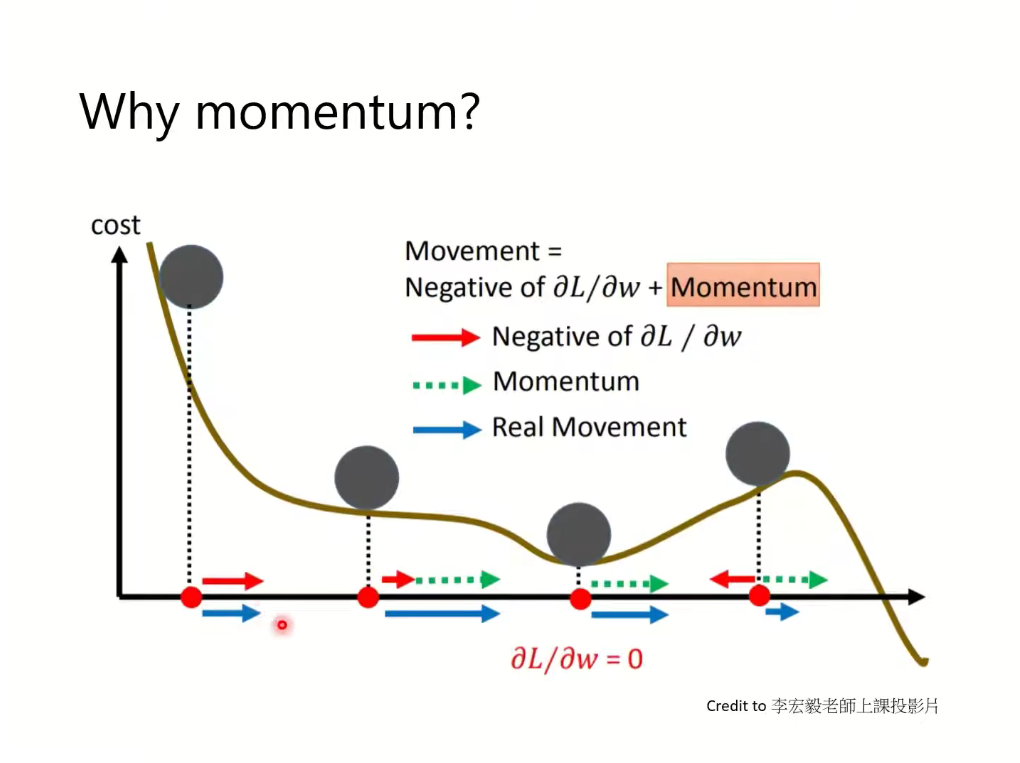
通过加入变量v 使梯度继续沿原方向移动
梯度更新规则
v t = γ t − 1 + η ∇ θ J ( θ ) v_t=\gamma_{t-1}+\eta\nabla_\theta{J}(\theta) vt=γt−1+η∇θJ(θ)
θ = θ − v t \theta=\theta-v_t θ=θ−vt
一般取 γ = 0.9 \gamma=0.9 γ=0.9
缺点
需要人工设定学习率
代码
vx = 0
while True:
dx = computed_gradient(x)
vx = rho * vx + dx
x += - learning_rate * vx
适用范围
SGD只依赖于当前迭代的梯度,十分不稳定,加一个“动量”的话,相当于有了一个惯性在里面,梯度方向不仅与这次的迭代有关,还与之前一次的迭代结果有关。“当前一次效果好的话,就加快步伐;当前一次效果不好的话,就减慢步伐”;而且在局部最优值处,没有梯度但因为还存在一个动量,可以跳出局部最优值
Nesterov Accelerated Gradient
Nesterov动量和标准动量之间的区别在于梯度的计算上。Nesterov动量中,梯度计算在施加当前速度之后,可以理解为Nesterov 动量往标准动量方法中添加了一个校正因子
梯度更新规则
v t = γ v t − 1 + η ∇ θ J ( θ − γ v t ) v_t = \gamma v_{t-1}+\eta \nabla_\theta J(\theta-\gamma v_t) vt=γvt−1+η∇θJ(θ−γvt)
θ = θ − v t \theta = \theta-v_t θ=θ−vt
一般取 γ = 0.9 \gamma=0.9 γ=0.9
适用范围
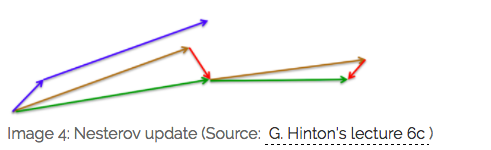
蓝色是 Momentum 的过程,会先计算当前的梯度,然后在更新后的累积梯度后会有一个大的跳跃
而 NAG 会先在前一步的累积梯度上(brown vector)有一个大的跳跃,然后衡量一下梯度做一下修正(red vector),这种预期的更新可以避免我们走的太快
代码
while True:
dx = compute_gradient(x)
old_v = v
v = rho * v - learning_rate * dx
x += - rho * old_v + (1+rho) * v
适用范围
目前为止,我们可以做到,在更新梯度时顺应 loss function 的梯度来调整速度,并且对 SGD 进行加速。
Adagrad(Adaptive gradient algorithm)
独立地适应所有模型参数的学习率,缩放每个参数反比于其所有梯度历史平方值总和和平方根,具有损失最大偏导的参数相应有一个快速下降的学习率,而具有小偏导的参数在学习率上有相对较小的下降。总的效果是在参数空间中更为平缓的倾斜方向会取得更大的进步
梯度更新规则
θ t + 1 = θ t , i − η G t , i i + ϵ g t , i \theta_{t+1} = \theta_{t,i} - \frac \eta {\sqrt{G_{t,ii}+\epsilon}}g_{t,i} θt+1=θt,i−Gt,ii+ϵηgt,i
其中g为 t时刻 参数
θ
i
\theta_i
θi 的梯度
g
t
,
i
=
∇
θ
J
(
θ
i
)
g_{t,i}=\nabla_\theta J(\theta_i)
gt,i=∇θJ(θi)
其中
G
t
G_t
Gt是个对角矩阵,(i,i)元素就是t时刻参数
θ
i
\theta _i
θi的梯度平方和
一般 η \eta η 选取 0.01
缺点
分母会不断积累,这样学习率就会收缩并最终变得非常小
代码
grad_squared = 0
while True:
dx = compute_gradient(x)
grad_squared += dx * dx
x -= learning_rate * dx / (np.sqrt(grad_squared) + 1e-7)
使用范围
总的效果是在参数空间中更为平缓的倾斜方向会取得更大的进步。对于训练深度神经网络而言,从训练开始积累梯度平方会导致有效学习率过早和过量的减小
Adadelta (RMSProp)
对 Adagrad 的改进
和 Adagrad 相比,分母的G换成了过去的梯度平方的衰减平均值 指数衰减平均值
Δ
θ
t
=
−
η
E
[
g
2
]
t
+
ϵ
g
t
\Delta\theta_t=-\frac \eta {E[g^2]_t+\epsilon}g_t
Δθt=−E[g2]t+ϵηgt
这个分母相当于梯度的均方根 root mean squared (RMS),在数据统计分析中,将所有值平方求和,求其均值,再开平方,就得到均方根值 ,所以可以用 RMS 简写
Δ
θ
t
=
−
η
R
M
S
[
g
]
t
g
t
\Delta\theta_t=-\frac \eta {RMS[g]_t}g_t
Δθt=−RMS[g]tηgt
其中 E 的计算公式如下,t 时刻的依赖于前一时刻的平均和当前的梯度
E
[
g
2
]
t
=
γ
E
[
g
2
]
t
−
1
+
(
1
−
γ
)
g
t
2
E[g^2]_t=\gamma E[g^2]_{t-1}+(1-\gamma){g_t}^2
E[g2]t=γE[g2]t−1+(1−γ)gt2
梯度更新规则
将学习率
η
\eta
η 换成
R
M
S
[
Δ
θ
]
RMS[\Delta \theta]
RMS[Δθ]
Δ
θ
t
=
−
R
M
S
[
Δ
θ
]
t
−
1
R
M
S
[
g
]
t
g
t
\Delta\theta_t=-\frac {RMS[\Delta \theta]_{t-1}} {RMS[g]_t}g_t
Δθt=−RMS[g]tRMS[Δθ]t−1gt
θ t + 1 = θ t + Δ θ t \theta_{t+1}=\theta_t+\Delta\theta_t θt+1=θt+Δθt
γ \gamma γ 一般设定为 0.9
缺点
解决了 AdaGrad 的缺点
代码
grad_squared = 0
while True:
dx = compute_gradient(x)
grad_squared = decay_rate * grad_squared + (1-decay_rate) * dx * dx
x -= learning_rate * dx / (np.sqrt(grad_squared) + 1e-7)
适用范围
RMSProp由Hinton于2012年提出,用于修改AdaGrad以在非凸设定下效果更好,将梯度积累改变为指数加权的移动平均。AdaGrad设计以让凸问题能够快速的收敛。当应用于非凸函数训练神经网络时,学习轨迹可能穿过了很多不同的结构,最终到达一个局部是凸碗的结构。AdaGrad根据平方梯度的整个历史来收缩学习率,学习率很可能在到达这样的凸碗结构之前就变得太小。而RMSProp使用指数衰减平均,丢弃遥远过去的历史,使其能够在找到凸碗结构后快速收敛,该算法等效于一个初始化与该碗状结构的AdaGrad算法。实践中和经验上,RMSProp已经被证明是是一种有效而且实用的深度神经网络优化算法,目前是深度学习从业者经常采用的优化方法之一
Adam
Adam (adaptive moments),在早期算法的背景下,最好被看成结合RMSProp和具有一些重要区别的动量的变种
相当于 RMSprop + Momentum
梯度更新规则
除了像 Adadelta 和 RMSprop 一样存储了过去梯度的平方 vt 的指数衰减平均值 ,也像 momentum 一样保持了过去梯度 mt 的指数衰减平均值
m
t
=
β
1
m
t
−
1
+
(
1
−
β
1
)
g
t
m_t=\beta_1m_{t-1}+(1-\beta_1)g_t
mt=β1mt−1+(1−β1)gt
v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 v_t=\beta_2v_{t-1}+(1-\beta_2){g_t}^2 vt=β2vt−1+(1−β2)gt2
如果 mt 和 vt 被初始化为 0 向量,那它们就会向 0 偏置,所以做了偏差校正,通过计算偏差校正后的 mt 和 vt 来抵消这些偏差
m
t
^
=
m
t
1
−
β
1
t
\hat{m_t}=\frac {m_t} {1-{\beta_1}^t}
mt^=1−β1tmt
v t ^ = v t 1 − β 2 t \hat{v_t}=\frac {v_t} {1-{\beta_2}^t} vt^=1−β2tvt
规则
θ
t
+
1
=
θ
t
−
η
v
t
^
+
ϵ
m
t
^
\theta_{t+1}=\theta_t-\frac {\eta} {\sqrt{\hat{v_t}}+\epsilon}\hat{m_t}
θt+1=θt−vt^+ϵηmt^
建议 β1 = 0.9,β2 = 0.999,ϵ = 10e−8
缺点
并不适合所有
代码
- beta1 = 0.9
- beta2 = 0.999
- learning_rate = 1e-3 or 5e-4
first_moment = 0
second_moment = 0
while True:
dx = computed_gradient(x)
first_moment = beta1 * first_moment + (1-beta1) * dx # Momentum
second_moment = beta2 * second_moment + (1-beta2) * dx *dx #AdaGrad/RMSProp
x -= learning_rate * first_moment / (np.sqrt(second_moment) + 1e-7)
上面的Adam前几次迭代的步长会非常大,这里增加了偏置矫正项t:
注意t的值会随着迭代次数增加
first_moment = 0
second_moment = 0
for t in range(num_iterations):
dx = compute_gradient(x)
first_moment = beta1 * first_moment + (1-beta1) * dx
second_moment = beta2 * second_moment = (1-beta2) * dx * dx
first_unbias = first_moment / (1 - beta1 ** t) #偏置纠正
second_unbias = second_moment / (1 - beta2 ** t)
x -= learning_rate * first_unbias / (np.sqrt(second_unbias) + 1e-7)
适用范围
首先,在Adam中动量直接并入了梯度一阶矩(指数加权)的估计。将动量加入RMSProp最直观的方法是将动量应用于缩放后的梯度。其次,Adam包括偏置修正,修正从原点初始化的一阶矩(动量项)和二阶矩(非中心项)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









