







 本文介绍了基于TWC_CNN的藏文文本分类技术,涉及数据集构建、预处理、特征基元选择、模型构建等。研究对比了RNN、LSTM和Transformer,并提出融合词和音节的TWC_CNN模型,通过实验展示了其在藏文文本分类中的优势。
本文介绍了基于TWC_CNN的藏文文本分类技术,涉及数据集构建、预处理、特征基元选择、模型构建等。研究对比了RNN、LSTM和Transformer,并提出融合词和音节的TWC_CNN模型,通过实验展示了其在藏文文本分类中的优势。
本文仅用于自己学习所用,切勿搬运和转载!如有不对,欢迎批评指正!
如有侵权,联系立删!
藏文文本分类数据集构建、文本预处理、分类特征基元选择、分类器构建等方面研究了基于TwC_CNN的藏文文本分类技术。
藏文概述

藏文的基本单位是基本构件,基本构件组合成字丁,字丁组成藏文的字。
藏文的文本从小到大依次是基本构件级、字丁级、字级、词级、短语级、句级。

文本分类的深度学习方法
(1)RNN
循环神经网络(RNN)是一种用来处理序列数据的定向循环结构模型。RNN 网络和其他网络最大的不同就在于RNN能够实现某种“记忆功能”,是进行时间序列分析时最好的选择。RNN的整个网络只有简单的输入输出和网络状态参数。
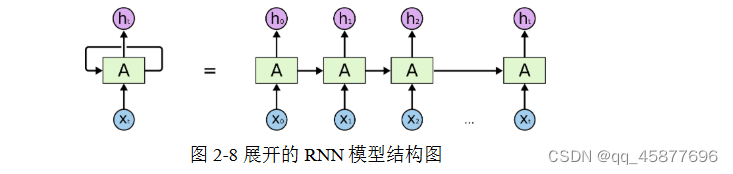
RNN每个时刻的隐藏层内部的计算流程如图所示,这种状态的传递被称作是RNN的正向传播:
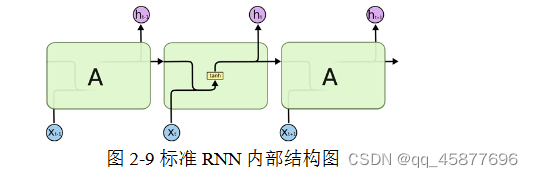
(2)LSTM
LSTM是一种特殊的循环神经网络,两者的区别在于普通的RNN单个循环结构内部只有一个状态,而LSTM的单个循环结构(又称为细胞)内部有四个状态。LSTM 循环结构之间保持一个持久的单元状态不断传递下去,用于决定哪些信息要遗忘或者继续传递,有效解决了RNN难以解决的人为延长时间任务的问题,并解决了RNN容易出现梯度消失的问题。
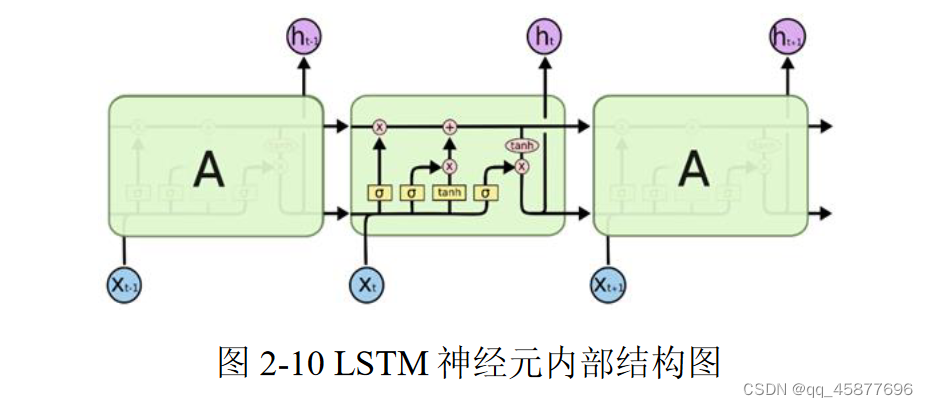
LSTM 细胞由单元状态、遗忘门、输入门及输出门组成。
遗忘门:决定 时刻的状态信息中存留多少信息到当前时刻;
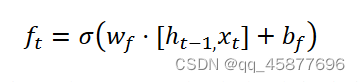
输入门:决定 时刻的输入数据中多少信息可以保留到单元状态;
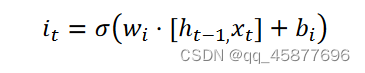
输出门:决定当前的输出值。
(3)Transformer
Transformer能一次性遍历文本的序列,也能提取全局语义特征,而且主要应用于序列编码-解码任务中。Transformer模型通过多头自注意力机制可以在并行计算的同时捕获长距离依赖关系,充分学习到输入文本的全局语义信息。Transformer模型中位置编码可以参考:Transformer学习笔记一:Positional Encoding(位置编码) - 知乎 (zhihu.com)

自注意力机制参考:Transformer学习笔记二:Self-Attention(自注意力机制) - 知乎 (zhihu.com)
藏文文本分类数据集构建
获得数据
藏语数据集预处理一般包括去除非藏文字符、过滤停用词、音节切分、分词及词性标注等,其研究起步较晚,主要成果集中在分词和词性标注方面。
本文采集数据时,采用爬虫为主人工录入为辅的策略采集了文学、宗教、医学、格萨尔、教育、经济、历史地理、农牧、生态旅游和政治等类别的藏文文本数据,数据的主要来源为中国西藏网、中国藏族网通和琼迈文学网等。得到了规模为104.8M的藏文分类文本数据。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









