






目录
第一章 Shell正则应用
正则表达式是一种字符模式,用于在查找过程中匹配指定的字符。
在大多数程序里,正则表达式都被置于两个正斜杠之间;/1[o0]ve/就是由正斜杠界定的正则表达式,
它将匹配被查找的行中任何位置出现相同的模式。在正则表达式中,元字符式最重要的概念。
正则表达式的作用
01.Linux正则表达式`grep、sed、awk`
02.大量的字符串文件需要进行配置,而且式非交互式的
03.过滤相关的字符串,匹配字符串,打印字符串
正则表达式注意事项
01.正则表达式应用非常广泛,存在于各种语言中,例如:php,python,java等。
02.正则表达式和通配符特殊字符是有本质区别的。
03.要学好`grep、sed、awk`首先就要掌握正则表达式。
1.1基础正则表达式
元字符意义BRE,正则表达式实际就是一些特殊字符,赋予了它特定的含义。
正则表达式 描述
\ 转义符,将特殊字符进行转义,忽略其特殊意义
^ 匹配行首,awk中,^则是匹配字符串的开始
$ 匹配行尾,awk中,$则是匹配字符串的结尾
^$ 表示空行
. 匹配除换行符\a之外的任意单个字符
.* 匹配所有
[] 匹配包含在[字符]之中的任意一个字符
[^ ] 匹配[]之外的任意一个字符(排除,PS:不是以什么开头)
[ - ] 匹配[]中指定范围的任意一个字符
? 匹配之前的项1次或者0次
+ 匹配之前的项1次或者多次
* 匹配之前的项0次或者多次.*
() 匹配表达式,创建一个用于匹配的子串
{ n } 匹配之前的项n次,n是可以为0的正整数
{n,m} 指定之前的项至少匹配n次,最多匹配m次,n<=m
| 交替匹配|两边的任意一项ab(c|d)匹配abc或abd
1.2 grep 正则表达式实战
1.2.1 grep 参数
-a 二进制以文本方式搜索数据
-c 计算找到的搜索字符串总行数
-o 仅显示出匹配的内容 统计文件中出现的次数
-i 不区分大小写
-v 反向选择 显示没有 收到字符串的那一行
-E 扩展的grep即egrep
--clolr=auto 以特定颜色高亮显示匹配关键字
-B 除显示匹配一行之外,并显示该行之前的num行
-A 除显示匹配一行之外,并显示该行之后的num行
-C 除了显示匹配的行外,并显示该行之前后的各num行
-W 按单词搜索,相当于\b
-r 递归查找目录下所有包含内容
[root@abin ~]# cat test.txt
I am abin boy!
I teach linux.
test
I like badminton ball,billiard ball and chinese chess!
my blog is http:www.abins.cn
our site is http:www.abins.cn
my qq num is 1781668
not 5728918888887
1.2.2过滤以m开头的行
[root@abin ~]# grep "^m" test.txt
my blog is http:www.abins.cn
my qq num is 1781668
1.2.3过滤以n结尾的行
[root@abin ~]# grep "n$" test.txt
my blog is http:www.abins.cn
our site is http:www.abins.cn
1.2.4排除空行,并打印行号
[root@abin ~]# grep -n "^$" test.txt --显示空行,并显示行号
4:
[root@abin ~]# grep -vn "^$" test.txt --排除空行,并显示行号
1:I am abin boy!
2:I teach linux.
3:test
5:I like badminton ball,billiard ball and chinese chess!
6:my blog is http:www.abins.cn
7:our site is http:www.abins.cn
8:my qq num is 1781668
9:not 5728918888887
1.2.5匹配任意一个字符,不包括空行
[root@abin ~]# grep "." test.txt
I am abin boy!
I teach linux.
test
I like badminton ball,billiard ball and chinese chess!
my blog is http:www.abins.cn
our site is http:www.abins.cn
my qq num is 1781668
not 5728918888887
1.2.6匹配所有
[root@abin ~]# grep ".*" test.txt --包括空行
I am abin boy!
I teach linux.
test
I like badminton ball,billiard ball and chinese chess!
my blog is http:www.abins.cn
our site is http:www.abins.cn
my qq num is 1781668
not 5728918888887
1.2.7匹配单个任意字符
[root@abin ~]# grep "abin" test.txt
I am abin boy!
my blog is http:www.abins.cn
our site is http:www.abins.cn
1.2.8以点结尾的
[root@abin ~]# grep "\.$" test.txt
I teach linux.
1.2.9精确匹配到
[root@abin ~]# grep -o "8*" test.txt
1.2.10匹配有abc的行
[root@abin ~]# grep "[abc]" test.txt
I am abin boy!
I teach linux.
I like badminton ball,billiard ball and chinese chess!
my blog is http:www.abins.cn
our site is http:www.abins.cn
1.2.11匹配数字所在的行"[0-9]"
[root@abin ~]# grep "[0-9]" test.txt
my qq num is 1781668
not 5728918888887
1.2.12匹配所有小写字母[a-z]
[root@abin ~]# grep "[a-z]" test.txt
1.2.13重复8三次
[root@abin ~]# grep -E "8{3}" test.txt --第一种方式
not 5728918888887
[root@abin ~]# grep "8\{3\}" test.txt --第二种方式
not 5728918888887
1.2.14重复数字8,3-5次
[root@abin ~]# grep "8\{3,5\}" test.txt
not 5728918888887
1.2.15至少1次或1次以上
[root@abin ~]# grep -E "8{1,}" test.txt
my qq num is 1781668
not 57289188888871.3 sed文本处理
sed是一个流编辑器,非交互式的编辑器,它一次处理一行内容
处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”(pattern space)
接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕
接着处理下一行,这个不断重复,直到文件末尾
文件内容并没有改变,除非你,使用重定向存储输出
sed要用自动编辑一个或多个文件,简化对文件的反复操作,编辑转换程序等
1.3.1 sed命令格式
sed [options] command files
1.3.2 sed正则使用
与grep一样,sed在文件中查找模式时也可以使用正则表达式(RE)和各种元字符
正则表达式是括在斜杠间的模式,用于查找和替换,以下是sed支持的元字符
使用基本元字符集^ , $ , . , * , [] , [^] , \< \> , \(\) , \{\}
使用扩展元字符集? , + , {} , | , ()
使用扩展元字符的方式 \+ sed -r
1.3.3 sed选项参数
-e 允许多项编辑器
-n 取消默认的输出
-i 直接修改对应文件
-r 支持扩元字符
1.3.4 sed内置命令参数
a 在当前行后添加一行或多行
c 在当前行进行替换修改
d 在当前行进行删除操作
i 在当前行之前插入文本
p 打印匹配的行或指定行
n 读入下一输入行,从下一条命令进行处理
! 对所选行以外的所有行应用命令
h 把模式空间里的内容重定向到暂存缓冲区(暂存缓冲区即为暂存区)
H 把模式空间里的内容追加到暂存缓冲区
g 取出暂存缓冲区的内容,将其复制到模式空间,覆盖该处原有内容
G 取出暂存缓冲区的内容,将其复制到模式空间,追加在原有内容后面
1.3.5 先删除行,然后管道给后面的sed进行替换
[root@abin ~]# sed '1,4d' test.txt|sed 's#abin#cxt#g'
1.3.6 使用-e进行多次编辑修改操作
[root@abin ~]# sed -e '1,3d' -e 's#cn#com#g' test.txt
1.3.7 打印命令p
1.3.7.1 打印匹配abins的行
[root@abin ~]# sed -n '/abins/p' test.txt
1.3.7.2 打印第二行的内容
[root@abin ~]# sed -n '2p' test.txt
1.3.7.3 打印最后一行
[root@abin ~]# sed -n '$p' test.txt1.3.8 追加命令`a`
1.3.8.1 给3行添加配置\t tab键(需要转义)\n换行符
[root@abin ~]# sed -i '3a cxt' test.txt 1.3.9 修改命令`c`
1.3.9.1 指定某行进行内容替换
[root@abin ~]# sed -i '4c abins' test.txt
1.3.9.2 正则匹配对应内容,然后进行替换
[root@abin ~]# sed -i '/^SELINUX/c SELINUX=Disabled' /etc/selinux/config
1.3.9.3 非交互式修改指定的配置文件
[root@abin ~]# sed -ri '/UseDNS/cUseDNS no' /etc/ssh/sshd_config
[root@abin ~]# sed -ri '/GSSAPIAuthentication/c#GSSAPIAuthentication no' /etc/ssh/sshd_config
[root@abin ~]# sed -ri '/^SELINUX=/cSELINUX=disabled' /etc/selinux/config1.3.10 删除命令`d`
1.3.10.1 指定删除第三行,但不会改变文件内容
[root@abin ~]# sed '3d' test.txt
1.3.10.2 从第三行删除到最后一行
[root@abin ~]# sed '3,$d' test.txt
1.3.10.3 删除最后一行
[root@abin ~]# sed '$d' test.txt
1.3.10.4 删除所有的行
[root@abin ~]# sed '1,$d' test.txt
1.3.10.5 匹配正则进行该行删除
[root@abin ~]# sed /test/d test.txt1.3.11 插入命令`i`
1.3.11.1 在文件的某一行上面添加内容
[root@abin ~]# sed -i '3i linux' test.txt
1.3.12 写文件命令`w`
1.3.12.1 将匹配的行写入新文件中
[root@abin ~]# sed -n '/abins/w newfile' test.txt
1.3.12.2 将text.txt文件的第二行写入到newfile01中
[root@abin ~]# sed -n '2w newfile01' test.txt
1.3.13 获取下一行命令`n`
1.3.13.1 匹配test的行,删除test行的下一行
[root@abin ~]# sed '/test/{n;d}' test.txt
1.3.13.2 替换匹配test行的下一行
[root@abin ~]# sed '/root/{n;s/bin/test/}' passwd1.3.14 暂存和取用命令`h H g G` --g为覆盖,G为追加
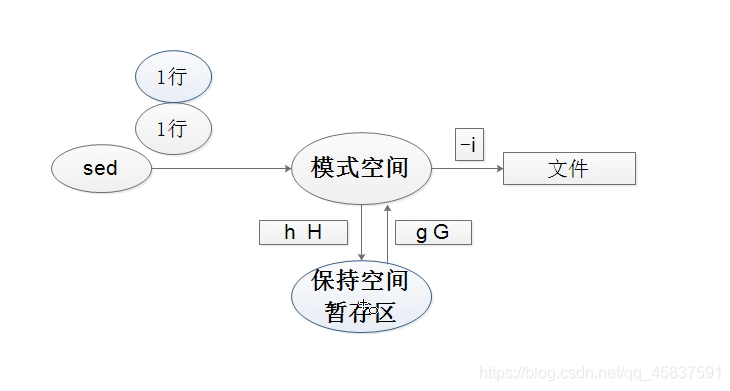
1.3.14.1 将第一行的写入到暂存区,替换最后一行的内容
[root@abin ~]# sed '1h;$g' /etc/hosts
1.3.14.2 将第一行的写入到暂存区,在最后一行调用暂存区内容追加至于尾部
[root@abin ~]# sed '1h;$G' /etc/hosts
1.3.14.3 将第一行的内容删除但保留至暂存区,在最后一行调用暂存区内容追加至于尾部
[root@abin ~]# sed -r '1{h;d};$G' /etc/hosts
1.3.14.4 将第一行的内容写入到暂存区,
[root@abin ~]# sed -r '1h;2,$g' /etc/hosts
1.3.14.5 将第一行重定向至暂存区,2-3行
[root@abin ~]# sed -r '1h;2,3H;$G' /etc/hosts1.3.15 反向选择命令`!`
1.3.15.1 除了第三行,其他全部删除
[root@abin ~]# sed -r '3!d' test.txt1.3.16 sed匹配替换
s 替换命令标志
g 行内全局替换
i 忽略替换大小写
替换命令`s`
1.3.16.1 替换每行出现的第一个root
[root@abin ~]# sed 's/root/abin/' passwd
1.3.16.2 替换以root开头的行
[root@abin ~]# sed 's/^root/abin/' passwd
1.3.16.3 查找匹配的行,在匹配的行后面添加内容
[root@abin ~]# sed -r 's/[0-9][0-9]$/&.5/' passwd
1.3.16.4 匹配包含有root的行进行替换
[root@abin ~]# sed -r 's/root/abin/g' passwd
1.3.16.5 匹配包含有root的行进行替换,忽略大小写
[root@abin ~]# sed -r 's/root/abin/gi' passwd
1.3.16.6 后项引用
[root@abin ~]# ifconfig eth0|sed -n '2p'|sed -r 's#(^.*et)(.*)(net.*$)#\2#g'
删除文本的内容,需加转义
[root@abin ~]# sed -r '\/etc\/abc\/456/d' a.txt
如果碰到/符号,建议使用#符替换
[root@abin ~]# sed -r 's#/etc/abc/456#/dev/null#g' a.txt 1.3.17 删除文件
1.3.17.1 删除配置文件中#开头的注释行,如果碰到tab或空格是无法删除
[root@abin ~]# sed '/^#/d' file
1.3.17.2 删除配置文件包含有tab键的注释行
[root@abin ~]# sed -r '/^[\t]*#d' file
1.3.17.3 删除无内容空行
[root@abin ~]# sed -r '/^[\t]*$/d' file
1.3.17.4 删除注释行及空行
[root@abin ~]# sed -r '/^[\t]*#/d;/^[\t]*$/d' file
[root@abin ~]# sed -r '/^[\t]*#|^[ \t]*$/d' file
[root@abin ~]# sed -r '/^[\t]*($|#)/d' file1.3.18 给文件行加注释
1.3.18.1 将第二行到第六行加上注释信息
[root@abin ~]# sed '2,6s/^/#/' passwd
1.3.18.2 将第二行到第六行最前面添加#注释符
[root@abin ~]# sed -r '2,6s/.*/#&/' passwd --&表示匹配的所有内容
1.3.19 添加#注释符
[root@abin ~]# sed -r '3,$s/^#*/#/' passwd
[root@abin ~]# sed -r '30,50s/^[\t]*#*/#/' passwd
[root@abin ~]# sed -r '2,8s/^[\t#]*/#/' passwd1.4 awk文本处理
1.4.1 awk文本处理
`awk`是一种编程语言,用于在linux/unix下对文本和数据进行处理
`awk`数据可以来自标准输入,一个或多个文件,或其他命令的输出
`awk`通常是配合脚本进行使用,是一个强大的文本处理工具。
1.4.2 awk的数据处理方式
01.进行逐行扫描文件,从第一行到最后一行
02.寻找匹配的特定模式的行,在行上进行操作
03.如果没有指定处理动作,则把匹配的性显示到标准输出
04.如果没有指定模式,则所有被操作的行都被处理
1.4.3 awk的语法格式
awk [options] 'commands' filenames
awk [options] -f awk-script-file filenames
1.4.4选项options
-F 定义输入字段分隔符,默认的分隔符,空格或tab键
命令 command
行处理前 行处理 行处理后
BEGIN{} END{}
BEGIN发生在读文件之前
[root@abin ~]# awk 'BEGIN{print 1/2}'
0.5
BEGIN在行处理前,修改字段分隔符
[root@abin ~]# awk 'BEGIN{FS=":"}{print $1}' /etc/passwd
BEGIN在行处理前,修改字段读入和输出分隔符
[root@abin ~]# awk 'BEGIN{FS=":";OFS="---"}{print $1,$2}' /etc/passwd --OFS指定输出分隔符
[root@abin ~]# awk 'BEGIN{print 1/2} {print "ok"} END {print "Game over"}' /etc/hosts
0.5
ok
ok
ok
Game over
1.4.4.1 awk 命令格式
1.4.4.2 匹配awk 'pattern' filename
[root@abin ~]# awk '/root/' /etc/passwd
1.4.4.3 处理动作 awk '{action}' /etc/passwd
[root@abin ~]# awk -F: '{print $1}' /etc/passwd
1.4.4.4 匹配+处理动作 awk 'pattern {aaction}' filename
[root@abin ~]# awk -F ":" '/root/{print $1,$3}' /etc/passwd
root 0
operator 11
[root@abin ~]# awk 'BEGIN{FS=":"}/root/{print $1,$3}' /etc/passwd
root 0
operator 11
1.4.4.5 判断大于多少则输出什么内容 command | awk 'pattern {action}'
[root@abin ~]# df | awk '/\/$/ {if ($3>50000) print $4}'1.4.2 awk工作原理
awk -F: '{print $1,$3}' /etc/passwd
01.awk将文件中的每一行作为输入,并将每一行赋给内部变量'$0',以换行符结束 --$0输出总行
02.awk开始进行字段分解,每个字段存储在已编号的变量中,从'$1'开始[默认空格分隔]
03.awk默认字段分隔符是有内部'FS'变量来确定,可以使用'-F'修订
04.awk行处理时使用了'print'函数打印分割后的字段
05.awk在打印后的字段加上空行,因为'$1,$3'之间有一个逗号,逗号被映射至'OFS'内部变量中,称为输出字段分隔符,'OFS'默认为空格
06.awk输出之后,将从文件中获取另一行,并将其存储在'$0'中,覆盖原来的内容,然后将新的字符串分割成字段进行处理,该过程将持续到所有行处理完毕1.4.3 awk内部变量
01.'$0'保存当前记录的内容
[root@abin ~]# awk '{print $0}' /etc/passwd
02.'NR'记录输入总的编号(行号)
[root@abin ~]# awk '{print NR,$0}' /etc/passwd
[root@abin ~]# awk 'NR<=3' /etc/passwd
03.'FNR'当前输入文件的编号(行号)
[root@abin ~]# awk '{print NR,$0}' /etc/hosts /etc/hosts --两个文件序号连续
[root@abin ~]# awk '{print FNR,$0}' /etc/passwd /etc/hosts --两个文件各自编号
04.'NF'保存行的最后一列
NF表示一共多少列
$NF表示输出最后一列
[root@abin ~]# awk -F ":" '{print NF,$NF}' /etc/passwd /etc/hosts
05.'FS'指定字段分隔符,默认是空格
以冒号作为字段分隔符
[root@abin ~]# awk -F: '/root/{print $1,$3}' /etc/passwd
[root@abin ~]# awk 'BEGIN{FS=":"}{print $1,$3}' /etc/passwd
以空格冒号tab作为字段分割
[root@abin ~]# awk -F '[ :\t]' '{print $1,$2,$3}' /etc/passwd
06.'OFS'指定输出字段分隔符
逗号映射为OFS,初始情况下OFS变量是空格
[root@abin ~]# awk -F: '/root/{print $1,$2,$3,$4}' /etc/passwd
[root@abin ~]# awk 'BEGIN{FS=":";OFS="+++"}/root/{print $1,$2}' /etc/passwd
07.'RS'输入记录分隔符,默认为换行符[了解]
[root@abin ~]# awk -F: 'BEGIN{RS=" "}{print $0}' /etc/hosts
08.'ORS'将文件以空格为分隔每一行合并为一行[了解]
[root@abin ~]# awk -F: 'BEGIN{ORS=" "}{print $0}' /etc/hosts
09.'print'格式化输出函数
[root@abin ~]# date|awk '{print $2,"5月份""\n",$NF,"今年"}'
Jun 5月份
2020 今年
[root@abin ~]# awk -F: '{print "用户是:"$1"\t 用户uid:"$3"\t用户gid:"}' /etc/passwd
printf函数
[root@abin ~]# awk -F: '{print "%-15s %-10s %-15s\n",$1,$2,$3}' /etc/passwd
%s 字符类型
%d 数值类型
占15字符
- 表示左对齐,默认是右对齐
print 默认不会在行尾自动换行,如\n1.4.4 awk模式动作
awk语句都由模式和动作组成
模式部分决定动作语句何时触发及触发事件
如果省略模式部分,动作将时刻保持执行状态,模式可以是条件语句或复合语句或正则表达式
01.正则表达式
匹配记录(整行)
[root@abin ~]# awk '/^root/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
[root@abin ~]# awk '$0~/^root/' /etc/passwd
root:x:0:0:root:/root:/bin/bash
匹配字段:匹配操作符(`!`)
[root@abin ~]# awk '$1~/^root/' /etc/passwd
[root@abin ~]# awk '$NF!~/bash$/' /etc/passwd
02.比较表达式
比较表达式采用对文本进行比较,只有当条件为真,才执行指定的动作
比较表达式使用关系运算符,用于比较数字与字符串
关系运算符
运算符 含义 示例
< 小于 x<y
<= 小于等于 x<=y
== 等于 x==y
!= 不等于 x!=y
>= 大于等于 x>=y
> 大于 x>y
uid为0的列出来
[root@abin ~]# awk -F ":" '$3==0' /etc/passwd
uid小于10的全部列出来
[root@abin ~]# awk -F: '$3<10' /etc/passwd
用户登录的shell等于/bin/bash
[root@abin ~]# awk -F: '$7=="/bin/bash"' /etc/passwd
第一列为root的列出来
[root@abin ~]# awk -F: '$1=="root"' /etc/passwd
为root的用户列出来
[root@abin ~]# awk -F: '$1~/root/' /etc/passwd
[root@abin ~]# awk -F: '$1 !~/root/' /etc/passwd
03.条件表达式
[root@abin ~]# awk -F: '$3>300{print $0}' /etc/passwd
[root@abin ~]# awk -F: '{if($3>300)print $0}' /etc/passwd
[root@abin ~]# awk -F: '{if($3>5555){print $3} else {print $1}}' /etc/passwd
04.运算表达式
[root@abin ~]# awk -F: '$3*10 > 500000' /etc/passwd
[root@abin ~]# awk -F: 'BEGIN{OFS="--"}{if($3*10>50000){print $1,$3}}END{print "打印ok"}' /etc/passwd
nfsnobody--65534
打印ok
05.逻辑操作符和复合模式
&&逻辑与 ||逻辑或 !逻辑非
匹配用户名为root并且打印uid小于15的行
[root@abin ~]# awk -F: '$1~/root/&& $3<=15' /etc/passwd
root:x:0:0:root:/root:/bin/bash
匹配用户名为root或uid大于5000
[root@abin ~]# awk -F: '$1~/root/ || $3>=5000' /etc/passwd
root:x:0:0:root:/root:/bin/bash
nfsnobody:x:65534:65534:Anonymous NFS User:/var/lib/nfs:/sbin/nologin1.4.5 `awk`示例1
[root@abin ~]# cat b.txt
abin cxt:is a:good girl!
[root@abin ~]# awk '{print NF}' b.txt
4
[root@abin ~]# awk -F"[ :]" '{print NF}' b.txt
61.4.6 awk条件判断
if语句格式:{if(表达式){语句:语句:...}}
打印当前管理员用户名称
[root@abin ~]# awk -F: '{if($3==0){print $1,"is administrator"}}' /etc/passwd
root is administrator
统计系统用户数
[root@abin ~]# awk -F: '{if($3>0 && $3<1000){i++}}END{print i}' /etc/passwd
27
统计普通用户数
[root@abin ~]# awk -F: '{if($3>1000){i++}} END{print i}' /etc/passwd
14
if...else 语句格式:{if(表达式){语句;语句;...} else{语句;语句}}
[root@abin ~]# awk -F: '{if($3==0){print $1} else {print $7}}' /etc/passwd
[root@abin ~]# awk -F: '{if($3==0) {count++} else{i++}}' /etc/passwd
[root@abin ~]# awk -F: '{if($3==0){count++}else{i++}} END{print "管理员个数:"count;print"系统用户数:"i}' /etc/passwd
管理员个数:1
系统用户数:42
if...else if...else 语句格式:
{if(表达式1){语句;语句;...}else if(表达式2){语句;语句;...}else{语句;语句;...}}
[root@abin ~]# awk -F: '{if($3==0){i++}else if($3>0 && $3<1000){j++}else if($3>1000){k++}}END{print i;print j;print k}' /etc/passwd
1
27
14
[root@abin ~]# awk -F: '{if($3==0){i++}else if($3>0 && $3<1000){j++}else if($3>1000){k++}}END{print "管理员个数"i;print "系统用户个数"j;print "普通用户个数"k}' /etc/passwd
管理员个数1
系统用户个数27
普通用户个数141.4.7 awk循环语句
1.4.7.1 while循环
[root@abin ~]# awk 'BEGIN{i=1;while(i<=10){print i;i++}}'
1
2
3
...
10
[root@abin ~]# awk -F: '{i=1;while(i<=NF){print $i;i++}}' /etc/passwd
[root@abin ~]# awk -F: '{i=1;while(i<=10){print $0;i++}}' /etc/passwd
[root@abin ~]# cat b.txt
111 222
333 444 555
666 777 888 999
[root@abin ~]# awk '{i=1;while(i<=NF){print $i;i++}}' b.txt
111
222
333
444
555
666
777
888
999
1.4.7.2 for循环
c 风格 for
[root@abin ~]# awk 'BEGIN{for(i=1;i<=5;i++){print i}}'
1
2
3
4
5
将每行打印10次
[root@abin ~]# awk -F: '{for(i=1;i<=10;i++){print $0}}' /etc/passwd
[root@abin ~]# awk -F: '{for(i=1;i<=NF;i++){print $i}}' /etc/passwd1.4.8 awk数组概述
将需要统计的某个字段作为数组的索引,然后对索引进行遍历
1.4.8.1
统计'/etc/passwd'中各种类型'shell'的数量
[root@abin ~]# awk -F: '{shells[$NF]++}END{for(i in shells){print i,shells[i]}}' passwd


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









