







147-循环神经网络其他应用
RNN应用
一、关键字提取(many to one):将一段话作为序列输入网络,转输出只取最后一个状态用它来表示这句话的关键字。
二、手写数字识别(many to many:)输入与输出都是序列,一般是定长的,模型设计上利用RNN单元在每一个时间步上的输出得到序列结果。
三、seq2seq:一般是在机器翻译的任务中出现,将一句中文翻译成英文,那么这句英文的长度有可能会比中文短,也有可能会比中文长,所以这时候输出的长度就不确定了需要用序列到序列的模型来解决这个问题。
聊天机器人和问答系统也都是同样的原理,将句子输入,车输出是根据前面的输入来得到。
Seq2Seq
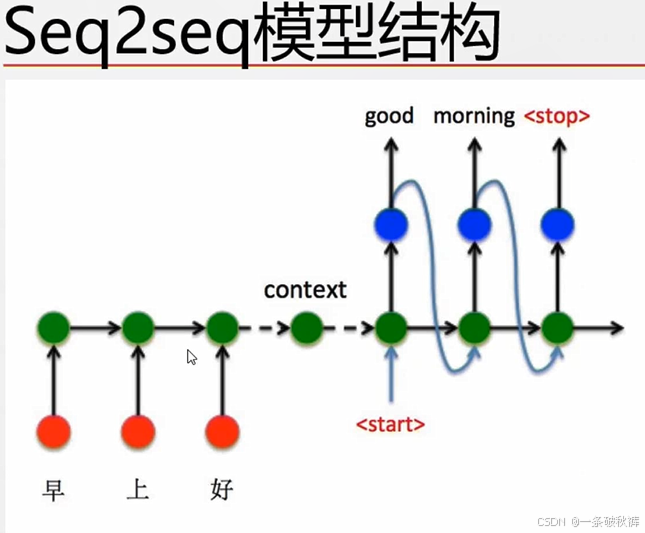
在Seq2Seq结构中,编码器Encoder把所有的输入序列都编码成一个统一的语义向量Context,然后再由解码器Decoder解码。在解码器Decoder解码的过程中不断地将前一个的输出作为后一个时刻的输入,循环解码,直到输出停止符为止 。
首先,解码器输入一个特殊的单词,即句子开头的单词对应的词向量(这个特殊的单词一般标记为<SOS>,即Start Of Sentence),输出第一个预测的单词。然后根据第一个预测的单词获取对应的词向量,进行第二个单词的预测,不断重复这个过程,直到到达最大预测长度或者预测得到另一个特殊单词(这个特殊的单词一般标记为<EOS >,即End Of Sentence),整个解码过程结束。
Seq2seq解码过程对应的解码模型称为自回归模型(Autoregressivemodel)。与经典RNN结构不同的是Seq2Seq结构不再要求输入和输出序列有相同的时间长度!它能够输出任意长的序列。
148-注意力机制简介
Seq2Seg缺陷
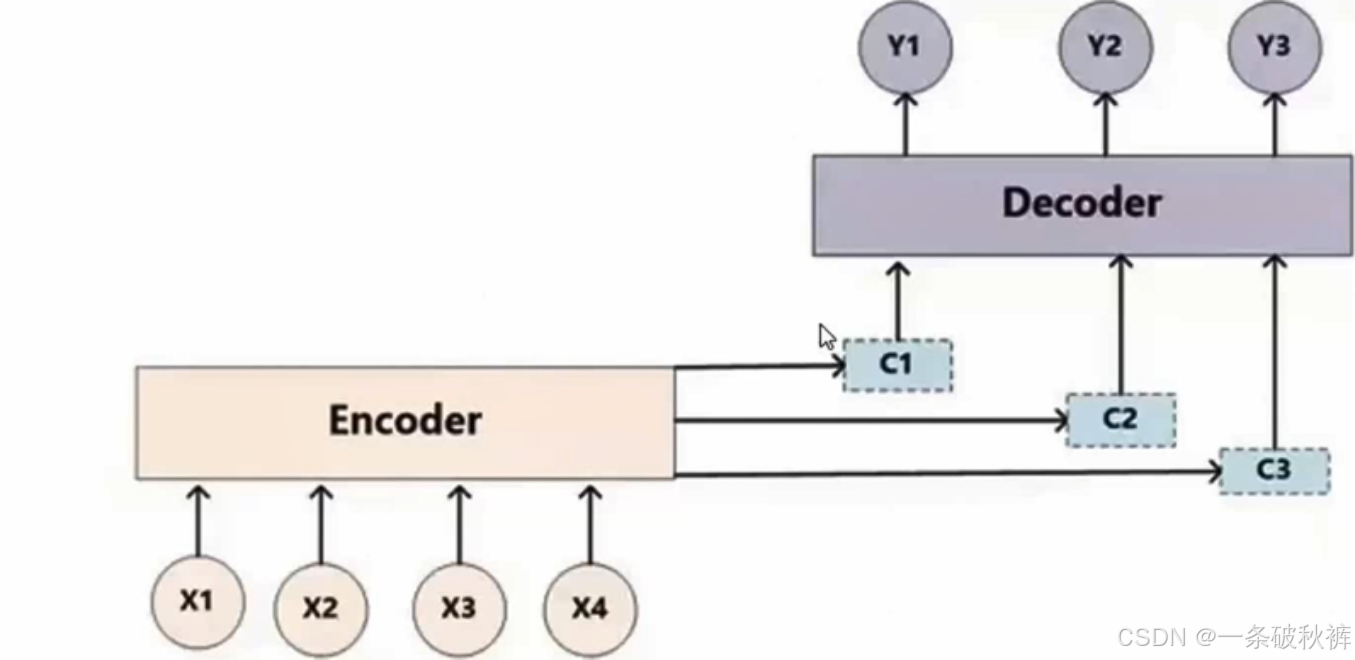
Seq2Seq模型能够用于很多任务,比如机器翻译,编码器对应的是源语言的文本序列,解码器对应的是目标语言的文本序列和文本归纳;也可用于文本摘要,编码器对应的是段落的文本序列解码器对应的是文本摘要。
但是由于RNN的特性,对于很长的序列,RNN(包括LSTM和GRU,它们只是在设计上尽量减少遗忘的发生都不可避免地出现遗忘的状况。这个缺点可以使用引入注意力机制J(Attention Mechanism) 来解决。
注意力机制
所谓注意力机制,就是通过引入一个神经网络,计算编码器的输出对解码器贡献的权重,最后计算加权平均后编码器的输出,即上下文(Context)。【原文一个单词对翻译很有作用,通过引入注意力机制增大权重,就可以有效地保留】
通过在编码器的输出和下一步的输入中引入上下文的信息,最后达到让解码器的某一个特定的解码和编码器的一些输出关联起来,即对齐(Alignment))的效果。
假设编码器的输出向量为si,解码器当前步的隐含层输出是hj,则可以根据这两个向量计算对应输出的分数score(si,hj)。
然后根据分数计算输入的加权平均的权重wij,对给定隐含层的输出hj,计算每个输出向量的分数,然后对所有的分数取Softmax函数,得到归一化后的权重。【输入输出建立关系,通过权重反应密切程度】
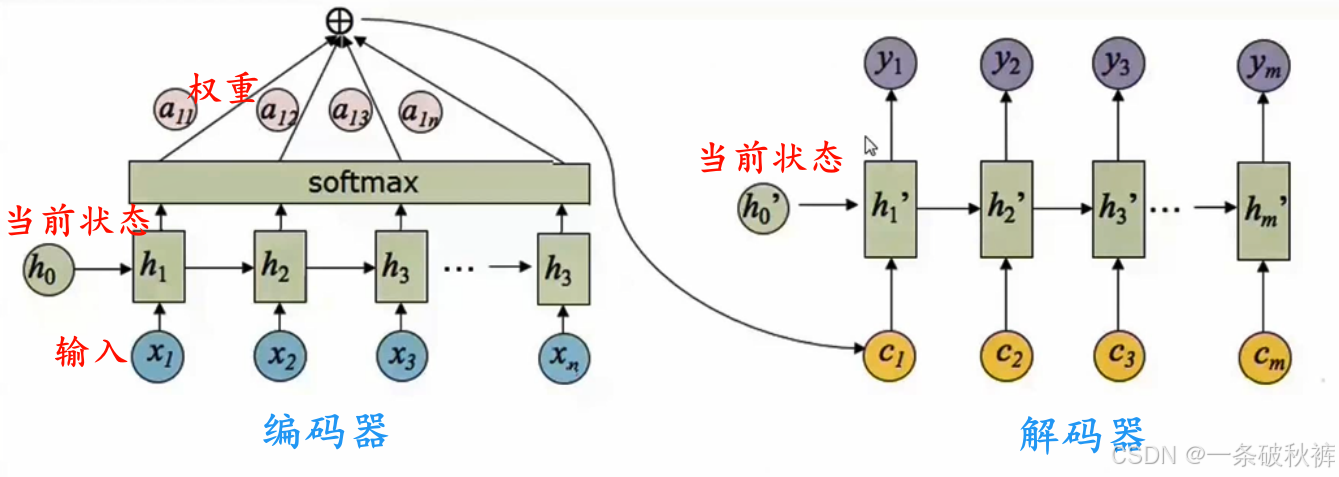
最后将隐含层的结果和归一化后的结果在特征方向)(最后-个维度)做拼接,线性变换,并且使用Tanh函数作为激活函数输出最终的上下文的值,当前步的计算可以通过拼接RNN的输出结果,以及上下文的值。
然后线性变换到和字典单词数目相同的特征输出,最后使用Softmax计算下一个单词的概率。根据单词的概率挑选出概率最大的单词,然后找到这个单词的词向量,与上下文向量cj拼接,作为下一步的RNN的输入。
注意力层涉及解码器每一步输出的隐含状态,以及编码器的所有输出。假设编码器输入序列的长度是S,解码器输出序列的长度是T,则总的计算量是S×T,因为解码过程中每个步骤都需要S次分数计算。
注意力是根据解码器的隐含状态生成的,根据注意力机制计算得到的权重,对编码器的输出加权平均可以得到对于当前的隐含状态,加权平均对应的权重代表的是编码器输出的哪些部分比较重要。
一般来说,重要的输出权重会比较大。通过检查权重相关的信息,可以把输入和输出对应起来相当于将输入序列和输出序列做对齐。
通过构建基于注意力机制的深度模型,可以让模型自动学习到编码器和解码器的序列单词之间的对应关系,从而提高Seq2Seg模型的准确率。
149-自注意力机制
循环神经网络的问题
循环神经网络在自然语言和其他序列处理的任务中得到了广泛的应用,而且取得了巨大的成果在序列的建模方面,由于循环神经网络天然的时序依赖的特性,因此,特别适合用来描述自然语言和时间序列等有内含顺序的输入数据。
循环神经网络结合上一节介绍的注意力机制,在长距离时间序列依赖关系的建模上也取得了巨大的成功,很多优秀的神经网络翻译模型都是基于注意力机制和Seg2Seg模型来构造的。
循环神经网络也有一些难以避免的缺点:
- 是模型的运行效率和代码优化的问题。对于循环神经网络来说,由于下一步的计算依赖上一步输出的隐含状态,因此,前后的计算有相互依赖关系,这就造成了模型不能进行并行化计算。
- 是多层神经网络的计算和优化问题因为在计算顺序上,下一层的计算依赖于上一层的输入,下一层只有等到上一层有一定输出之后才能进行计算,同时下一层的计算完成也依赖于上一层的计算完成,这也造成了模型优化上的困难。
计算速度上的劣势限制了循环神经网络的应用,特别是在计算比较长的序列的时候,时间的延迟可能对模型的实际应用造成比较大的影响。为了能够增加模型的并行性,同时也方便程序的优化,Google的深度学习研究团队开发了一个新的机制,即自注意力机制。
自注意力机制
自注意力机制首先来源于Google的研究团队发表的一篇论文。这篇文章的核心思想是不需要使用循环神经网络,取而代之可以完全使用注意力机制来描述时间序列的上下文相关性。对应的注意力机制称为自注意力机制。
自注意力机制的计算涉及序列中某一个输入相对于其他所有输入之间的联系。【联系到所有输入】在计算中并没有先后顺序之分,所以能够很容易地进行并行计算;在计算过程中主要涉及的是矩阵的乘法,模型的结构更加简单。因此,也更方便地对模型的结构进行优化,能够获得更大的加速比。
自注意力机制基本构造

自注意力机制需要输入三个值,即查询张量量(Q)、键张量(K)和值张量(S)。
这里假设Q、K、V三个张量的形状为N×TxC,即第一个维度是批次维度,第二个维度是序列的时间长度,第三个维度是序列的特征长度。
前两个张量(Q,K)的作用是根据查询张量获取每个键张量对应的分数,然后根据分数计算出对应的权重用得到的权重乘以值(V)张量,并对值张量加权平均,最后输出结果。【用输入进行线性变换得到三个张量,使用两个张量得到一个权重,对第三个张量进行加权求和求平均值】
第一、使用Q、K、V对应的权重矩阵对这三个张量进行线性变换,获得对应的变换后的张量Query、Key、Value。
接下来、计算相应的分数和权重,Query和Key进行矩阵乘法。在Query和Key最后的特征维度相等的状况下,这里相当于使用Query的每个特征,对Key的每个特征,求得两个特征的相似度,用这个相似度作为分数,沿着Key做Softmax函数来计算具体的权重。如果Query和Key相似度越大,那么该Key对应的分数也较大,同时对应的权重也比较大。
多头自注意力机制
在实践中经常使用多个并行的自注意力机制,成为多头注意力 (Multihead Attention),即使用多个注意力矩阵和多个权重对输入值进行加权平均,最后对加权平均的结果进行拼接。
使用多头注意力的原因是单个注意力机制只能捕捉一种序列之间的关联 (比如相邻单词之间的相关性)。如果使用多个注意力机制,就能捕捉多种序列之间的关联(比如,距离比较远的单词之间的相关性)。最后的拼接通过结合多种注意力机制,就能比较好地描述不同距离的单词之间的相互关系。
150-Transformer模型简介
Transformer模型
有了自注意力机制之后,就可以使用自注意力机制执行Seq2Seq任务,我们称这个模型为Transformer模型。
相比于RNN模型,基于自注意力机制的Seq2Seq总体的思路是类似的,只不过是把RNN的模块切换成了自注意力(Multihead Attention) )模块。
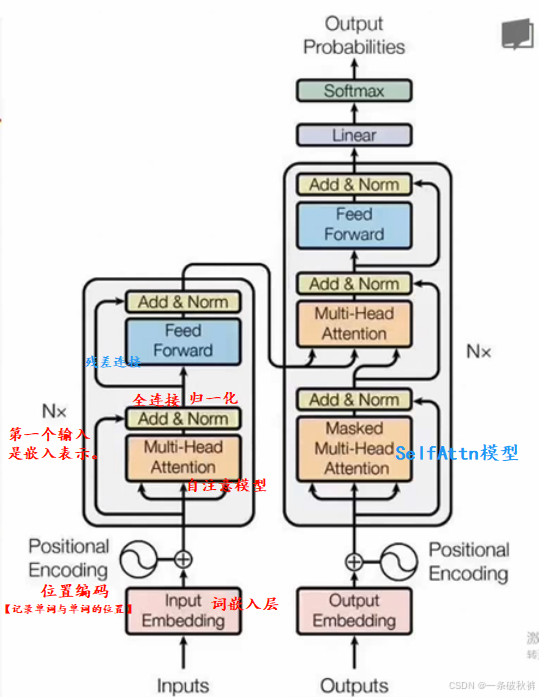
位置编码:
可使用周期性的函数来编码单词的顺序,比如使用不同周期的正弦函数和余弦函数来描述单词的顺序,这种位置编码方式的优点是能够编码任意长度的序列,但缺点是序列的词嵌入需要进行预先计算,需要消耗一定的计算时间。也可使用位置的嵌入。
在计算嵌入层之后,进入自注意力模块和全连接模块的计算,以及归一化模块的计算。对于Transformer模型来说,根据张量输入的是编码器还是解码器,具体的自注意力模块输入有所不同。
在编码器中,对于第一个单元,其输入为词向量和位置向量沿着特征方向拼接的结果,对于其他单元,其输入均为前一个单元的输出。对于编码器的自注意力机制,K、Q、V的输入均为同一个即词嵌入或上一个模块的输出。
通过自注意力机制得到对应变换以后的输出后,然后使用两个全连接层(FeedForward,激活函数为ReLU)对输出的张量进行神经网络计算,最后对输出结果和模块的输入求和(残差连接),并对求和结果进行层归一化处理,输出模块的计算结果,这个结果将会保留下来便于进一步计算。
在解码器中,基本结构和编码器类似,但是在细节上有所区别,对于解码器来说,输入的值(单词嵌入和位置嵌入,或者上一层解码器的输出)首先要经过一个自注意力机制,就是解码器部分所示的SelfAttn模块,这个模块的作用是自注意力机制和残差连接,以及最后的层归一化输出。
PyTorch中自注意力机制模块
PyTorch本身提供了一系列的模块用来完成基于自注意力机制的模型的构建,其中包含自注意力机制的模块、Transformer编码器和解码器的模块。
PyTorch中自带的注意力机制模块是nn.MultiheadAttention。其默认的序列排列为 time step × Batch x features。
有了自注意力机制的模块后,就能使用它构造对应的编码器和解码器的层。模块对应的类的名字为TransformerEncoderLayer和TransformerDecoderLayer。
编码器和解码器的输入参数类似:
第一个参数dmodel代表单层编码器模型输入的特征维度大小;第二个参数nhead代表注意力的数目;dimfeedforward代表FF层的两层神经网络中间层的特征数目;dropout代表丢弃层的丢弃概率;这两个模块在内部自带层归一化,所以不需要指定层归一化的模块。
这两个类的forward方法:
对于编码器,srckey_padding_mask代表源序列中有效单词(即不包括填充单词)的掩码表示,srcmask代表注意力机制的掩码表示,从源代码可以看到,这部分相当于MultiheadAttention模块的attnmask。
有了单层的编码器和解码器模块的定义之后,我们可以进一步定义更大的模块Transformer模型的整个编码器和解码器以及Transformer模型本身。
对于TransformerEncoder和TransformerDecoder来说,需要分别传入对应的单层TransformerEncoderLayer和TransformerDecoderLayer的实例,以及对应的模块数目numlayers,最后的输入norm则是对张量经过所有子模块的计算之后,对最终输出做归一化的类型,默认是None,即不做任何归一化处理。
由于Transformer模型中不包含词嵌入模块因此,使用Transformer模块之前需要经过词嵌入模块和位置嵌入模块的编码。
Transformer是近年来自然语言处理方面的一个重要的模型很多其他的模型都借鉴了Transformer模型中的自注意力机制。Transformer不仅可以用来完成Seq2Seq的任务,还可以被用来完成其他的自然语言处理任务,如命名实体识别和机器阅读理解等。
在这个领域,基于Transformer模型的BERT模型(Bidirectional Encoder Representations fromTransformers,即基于Transformer模型的双向编码表示)能够起到很好的编码文本序列中包含的每个单词的作用。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









