







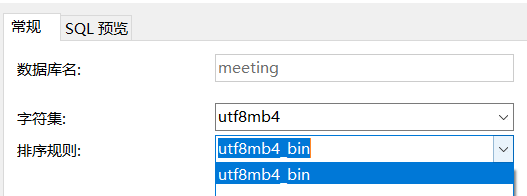
建数据库
创建一个数据库一般选择下面的字符集和排序规则
sql语句
对某个数据库或数据表的sql语句操作,如果不确定其存在与否,可以加一个判断条件:
如:创建某一数据:
CREATE DATABASE IF NOT EXISTS `onete`;
加一个IF NOT EXISTS表示如果此数据库不存在,则… …
当sql语句中出现的一些标识符,比如我们创建的表名和字段,当他们可能和sql语句中的某些关键值重复的时候,我们可以在这些标识符上面加一个``符号(在tab键上面),表示此为我们创建的一些名字。
查看数据库:show databases;
创建数据库:create database 数据库名;
删除数据库:drop database 数据库名;
使用数据库:use 数据库名;
在使用数据库的情况下查看表结构:desc 表名;或describe 表名;

对表的操作

对表中字段的操作,都是alter table `表名` 开头
删除表或删除数据库都是一样的规则,drop table或database `名字`

所有的创建和删除操作,加上判断(如:IF NOT EXISTS),防止其不存在或者已存在
数据库中的列类型

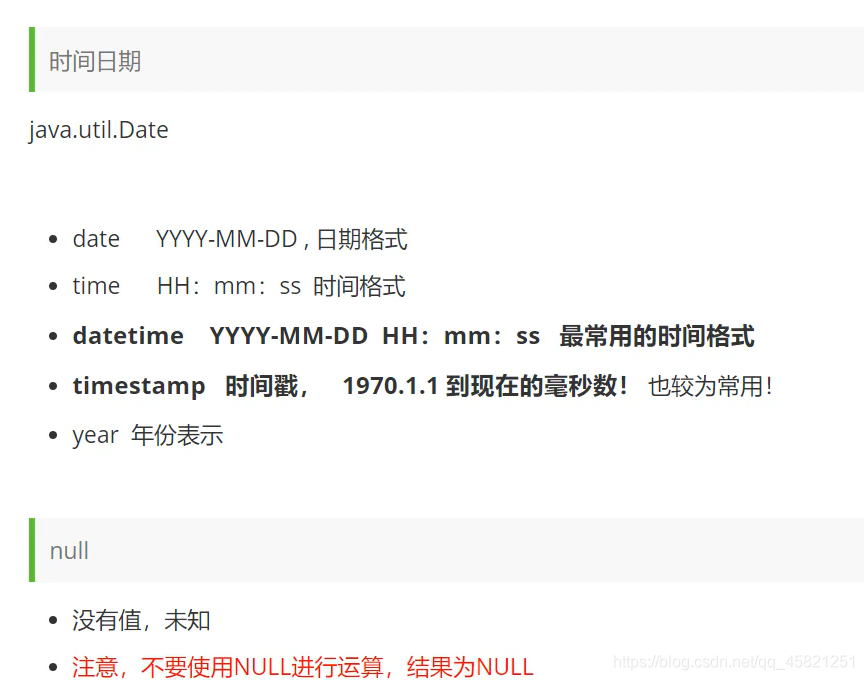
数据库的字段属性


这些属性,即我们在创建字段时可为字段设置的属性
表的创建
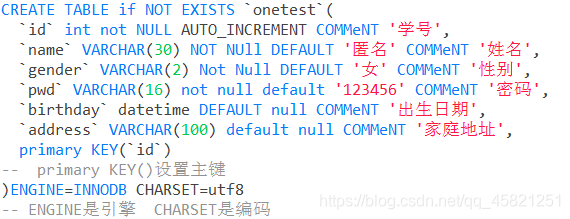
1: 格式:`字段名` 列类型 属性(如非空,0填充,自动递增…) 注释。一般把设置主键的语句放在最下面
2:当我们创建表时不指定字符集,则默认使用Latin1编码集,不支持中文,我们也可在my.ini文件中指定数据库默认使用那个编码集,my.ini即mysql的核心配置文件。配置方法:在文件中加上这么一句character-set-server=utf8,即指定此mysql默认使用utf8当做默认编码集。但是一般不要这样做。
3: 我们应该在创建表的时候指定此表的编码集,即charset=utf8,若一直使用mysql默认的,则更换mysql数据库,因为其他mysql可能没有配置默认编码集,所以可能会出问题。
引擎
现有两个比较常用的
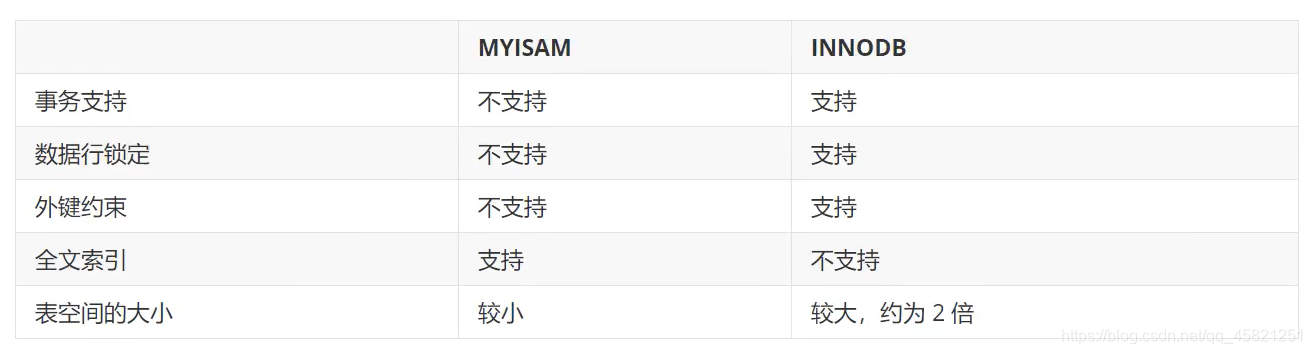
现若不指定引擎,则默认使用INNODB引擎。
在早期,默认使用的是MYISAM
两个引擎的使用环境:

物理空间存在位置

8.0以上版本,只有一个ibd文件
外键的两种设置方式
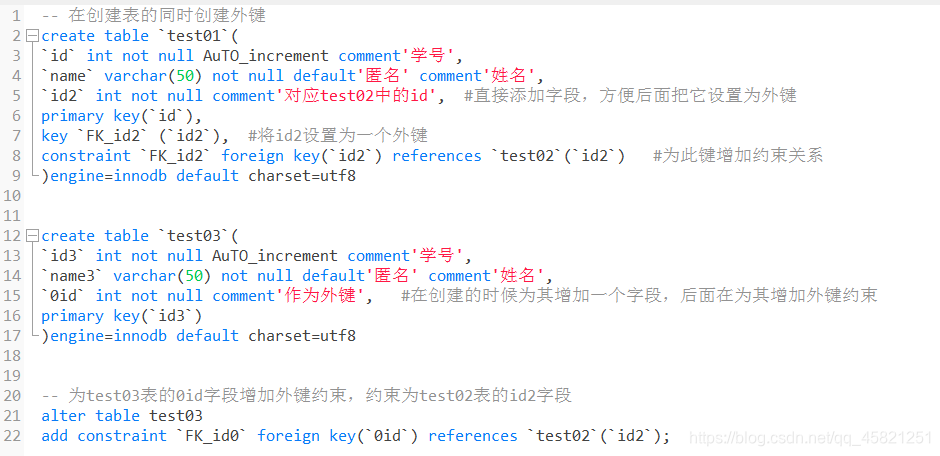
一个是在创建表的时候直接增加外键约束
一个是创建表结束后,再为表增加外键约束
一般不要使用外键,外键的概念要在应用层解决,不然会导致开发的时候很痛苦。
阿里中对这里也有着定性要求:“不得使用外键与级联,一切外键概念必须在应用层解决。”这是阿里Java规范里的原话。
简单的数据导入导出
一张表的导出
在cmd界面
用mysqldump -h主机名 -uMySQL用户名 -p密码 数据库名 表名(可同时导出多个表,表名间用空格隔开) >起一个文件名.sql
如果有可视化工具,则直接可以在可视化工具里面进行选择存储
一个数据库的导出
在cmd界面
mysqldump -h主机名 -uMySQL用户名 -p密码 >绝对路径/起一个文件名.sql
如果有可视化工具,则直接可以在可视化工具里面进行选择存储
或者在文件存储的层面
进入mySQL的安装路径(这里以文件夹方式安装的MySQL为例)
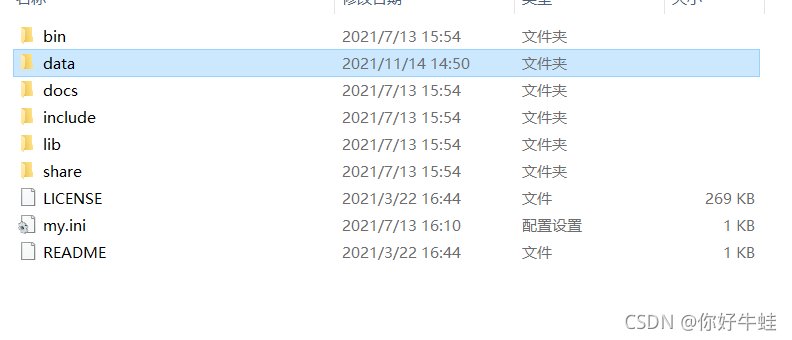 我们所有的表数据都在data里面
我们所有的表数据都在data里面
我们可以直接在里面找到要备份的数据库
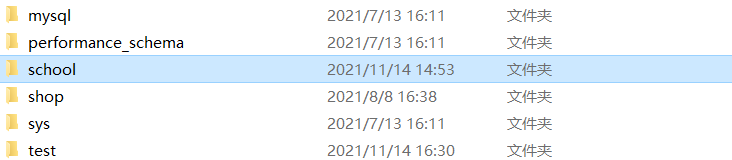
直接拷贝即可
导入
在cmd页面直接mysql -u用户名 -p密码 数据库名 表名 <文件的绝对路径
或者在mysql里面
直接
use 数据库名
source 文件的绝对路径
如果导入是数据库
则直接source 文件的绝对路径


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









