







 本文详细介绍了Java中创建对象的四种方法:new关键字、反射机制(newInstance()和Constructor)、序列化与反序列化,以及Clone方法的应用。重点讲解了每种方法的原理和适用场景,帮助读者理解对象生命周期与状态保存技巧。
本文详细介绍了Java中创建对象的四种方法:new关键字、反射机制(newInstance()和Constructor)、序列化与反序列化,以及Clone方法的应用。重点讲解了每种方法的原理和适用场景,帮助读者理解对象生命周期与状态保存技巧。
java如何创建对象
什么!学java还能找对象?这要从何说起
大家都知道没有对象先new一个,除了new以外还有哪些方法,首先提供一个学生类作为我们今天的主角对象
Student学生类
package domain;
/**
* Created by yantailor
*/
public class Student {
private String name;
private Integer age;
private String sex;
public Student(String name, Integer age, String sex) {
this.name = name;
this.age = age;
this.sex = sex;
}
public Student(){
this.name = "无参名字";
this.age = 10086;
this.sex = "无参性别";
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getSex() {
return sex;
}
public void setSex(String sex) {
this.sex = sex;
}
public void StudentMethod(){
System.out.println("学生方法");
}
public void StudentMethodWithParams(String params){
System.out.println("学生方法带参数:"+params+"\n"+this.name);
}
}
1.New创建对象
import domain.Student;
/**
* Created by yantailor
*/
public class testMain {
public static void main(String[] args) {
//1.new创建对象
Student student = new Student();
student.StudentMethod();
}
}
//返回结果
学生方法
2.反射创建对象
2.1 Class对象的newInstance()方法
使用Class对象的newInstance()方法来创建该Class对象对应类的实例。但是这种方式要求该Class对象的对应类有默认的构造器,而执行newInstance()方法时实际上是利用默认构造器来创建该类的实例。
import java.lang.reflect.InvocationTargetException;
import java.lang.reflect.Method;
/**
* Created by yantailor
*/
public class testMain {
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, InvocationTargetException, IllegalAccessException, InstantiationException {
//2.1 newInstance()创建对象
Class<?> student = Class.forName("domain.Student");
Object o = student.newInstance();
Method studentMethod =
student.getDeclaredMethod("StudentMethod", null);
studentMethod.invoke(o, null);
}
}
//返回结果
学生方法
2.2Class对象的Constructor创建再实例化对象
先使用Class对象获取指定的Constructor对象,再调用Construtor对象的newInstance()方法来创建该Class对象对应类的实例。通过这种方式可以选择使用某个类的指定构造器来创建实例。
如果我们不想利用默认构造器来创建java对象,而想利用指定的构造器来创建java对象,则需要利用Construtor对象,每个Construtor对应一个构造器,为了利用指定构造器来创建java对象,需要如下三个步骤:
(1)获取该Class对象;
(2)利用该Class对象的getConstrutor方法来获取指定的构造器;
(3)调用Construtor的newInstance方法来创建Java对象。
以下为带参数的构造器
import domain.Student;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
/**
* Created by yantailor
*/
public class testMain {
//2.2 Construtor后newInstance()创建对象
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, InvocationTargetException, IllegalAccessException, InstantiationException {
Class student = Class.forName("domain.Student");
//参数类型传入构造器
Constructor studentDeclaredConstructor = student.getDeclaredConstructor(new Class[]{String.class,Integer.class,String.class});
//参数传入构造器
Student o =(Student) studentDeclaredConstructor.newInstance(new Object[]{"zhangsan", 18, "male"});
o.StudentMethodWithParams("996");
}
}
//返回结果
学生方法带参数:996
zhangsan
以下为不带参数的构造器
import domain.Student;
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
/**
* Created by yantailor
* on 2021/8/14 10:19 @Version 1.0
*/
public class testMain {
public static void main(String[] args) throws ClassNotFoundException, NoSuchMethodException, InvocationTargetException, IllegalAccessException, InstantiationException {
Class student = Class.forName("domain.Student");
//参数类型传入构造器
Constructor studentDeclaredConstructor = student.getDeclaredConstructor();
//参数传入构造器
Student o =(Student) studentDeclaredConstructor.newInstance();
o.StudentMethodWithParams("996");
}
}
//返回结果
学生方法带参数:996
无参名字
3.利用反序列化创建对象
1、为什么要进行序列化
再介绍之前,我们有必要先了解下对象的生命周期,我们知道Java中的对象都是存在于堆内存中的,而堆内存是可以被垃圾回收器不定期回收的。从对象被创建到被回收这一段时间就是Java对象的生命周期,也即Java对象只存活于这个时间段内。
对象被垃圾回收器回收意味着对象和对象中的成员变量所占的内存也就被回收,这意味着我们就再也得不到该对象的任何内容了,因为已经被销毁了嘛,当然我们可以再重新创建,但这时的对象的各种属性都又被重新初始化了。所以如果我们需要保存某对象的状态,然后再在未来的某段时间将该对象再恢复出来的话,则必须要在对象被销毁即被垃圾回收器回收之前保存对象的状态。要保存对象状态的话,我们可以使用文件、数据库,也可以使用序列化,这里我们主要介绍对象序列化。我们很有必要了解这方面的内容,因为对象序列化不仅在保存对象状态时可以被用到(对象持久化),在Java中的远程方法调用RMI也会被用到,在网络中要传输对象的话,则必须要对对象进行序列化,关于RMI有机会我会再专门开贴介绍。
简单总结起来,进行对象序列化的话的主要原因就是实现对象持久化和进行网络传输,这里先只介绍怎样通过对象序列化保存对象的状态。
下面我们通过一个简单的例子来介绍下如何进行对象序列化。
2、怎样进行对象序列化
假设我们要保存Person类的某三个对象的name、age、height这三个成员变量,当然这里只是简单举例
我们先看下Person类,要序列化某个类的对象的话,则该类必要实现Serializable接口,从Java API中我们发现该接口是个空接口,即该接口中没声明任何方法。
import java.io.Serializable;
public class Person implements Serializable {
int age;
int height;
String name;
public Person(String name, int age, int height){
this.name = name;
this.age = age;
this.height = height;
}
}
下面我们看一下如何来进行序列化,这其中主要涉及到 Java 的 I/O 方面的内容,主要用到两个类 FileOutputStream 和 ObjectOutputStream , FileOutputStream 用于将字节输出到文件, ObjectOutputStream 通过调用 writeObject 方法将对象转换为可以写出到流的数据。所以整个流程是这样的: ObjectOutputStream 将要序列化的对象转换为某种数据,然后通过 FileOutputStream 连接某磁盘文件,再对象转化的数据转化为字节数据再将其写出到磁盘文件。下面是具体代码:
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
public class MyTestSer {
/**
* Java对象的序列化与反序列化
*/
public static void main(String[] args) {
Person zhangsan = new Person("zhangsan", 30, 170);
Person lisi = new Person("lisi", 35, 175);
Person wangwu = new Person("wangwu", 28, 178);
try {
//需要一个文件输出流和对象输出流;文件输出流用于将字节输出到文件,对象输出流用于将对象输出为字节
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.ser"));
out.writeObject(zhangsan);
out.writeObject(lisi);
out.writeObject(wangwu);
out.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
3、对象的反序列化
我们存储的目的主要是为了再恢复使用,下面我们来看下加上反序列化后的代码:
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.ObjectInputStream;
import java.io.ObjectOutputStream;
public class MyTestSer {
/**
* Java对象的序列化与反序列化
*/
public static void main(String[] args) {
Person zhangsan = new Person("zhangsan", 30, 170);
Person lisi = new Person("lisi", 35, 175);
Person wangwu = new Person("wangwu", 28, 178);
try {
//需要一个文件输出流和对象输出流;文件输出流用于将字节输出到文件,对象输出流用于将对象输出为字节
ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.ser"));
out.writeObject(zhangsan);
out.writeObject(lisi);
out.writeObject(wangwu);
} catch (IOException e) {
e.printStackTrace();
}
try {
ObjectInputStream in = new ObjectInputStream(new FileInputStream("person.ser"));
Person one = (Person) in.readObject();
Person two = (Person) in.readObject();
Person three = (Person) in.readObject();
System.out.println("name:"+one.name + " age:"+one.age + " height:"+one.height);
System.out.println("name:"+two.name + " age:"+two.age + " height:"+two.height);
System.out.println("name:"+three.name + " age:"+three.age + " height:"+three.height);
} catch (Exception e) {
e.printStackTrace();
}
}
}
输出结果如下:
name:zhangsan age:30 height:170
name:zhangsan age:35 height:175
name:zhangsan age:28 height:178
从添加的代码我们可以看到进行反序列化也很简单,主要用到的流是FileInputstream和ObjectInputstream正好与存储时用到的流相对应。另外从结果顺序我们可以看到反序列化后得到对象的顺序与序列化时的顺序一致。
4、总结
进行对象序列化主要目的是为了保存对象的状态(成员变量)。
进行序列化主要用到的流是FileOutputStream和ObjectOutputStream。FileOutputStream主要用于连接磁盘文件,并把字节写出到该磁盘文件;ObjectOutputStream主要用于将对象写出为可转化为字节的数据。
要将某类的对象序列化,则该类必须实现Serializable接口,该接口仅是一个标志,告诉JVM该类的对象可以被序列化。如果某类未实现Serializable接口,则该类对象不能实现序列化。
保存状态的目的就是为了在未来的某个时候再恢复保存的内容,这可以通过反序列化来实现。对象的反序列化过程与序列化正好相反,主要用到的两个流是FileInputstream和ObjectInputStream。
反序列化后得到的对象的顺序与保存时的顺序一致。
5、补充
补充一:上面我们举得例子很简单,要保存的成员变量要么是基本类型的要么是String类型的。但有时成员变量有可能是引用类型的,这是的情况会复杂一点。那就是当要对某对象进行序列化时,该对象中的引用变量所引用的对象也会被同时序列化,并且该对象中如果也有引用变量的话则该对象也将被序列化。总结说来就是在序列化的时候,对象中的所有引用变量所对应的对象将会被同时序列化。这意味着,引用变量类型也都要实现Serializable接口。当然其他对象的序列化都是自动进行的。所以我们只要保证里面的引用类型是都实现Serializable接口就行了,如果没有的话,会在编译时抛出异常。如果序列化的对象中包含没有实现Serializable的成员变量的话,这时可以使用transient关键字,让序列化的时候跳过该成员变量。使用关键字transient可以让你在序列化的时候自动跳过transient所修饰的成员变量,在反序列化时这些变量会恢复到默认值。
补充二:如果某类实现了Serializable接口的话,其子类会自动编程可序列化的,这个好理解,继承嘛。
补充三:在反序列化的时候,并不会调用对象的构造器,这也好理解,如果调用了构造器的话,对象的状态不就又重新初始化了吗。
补充四:我们说到对象序列化的是为了保存对象的状态,即对象的成员变量,所以静态变量不会被序列化。
4.clone创建对象
什么是"clone"?
在实际编程过程中,我们常常要遇到这种情况:有一个对象A,在某一时刻A中已经包含了一些有效值,此时可能 会需要一个和A完全相同新对象B,并且此后对B任何改动都不会影响到A中的值,也就是说,A与B是两个独立的对象,但B的初始值是由A对象确定的。在 Java语言中,用简单的赋值语句是不能满足这种需求的。要满足这种需求虽然有很多途径,但实现clone()方法是其中最简单,也是最高效的手段。
Java的所有类都默认继承java.lang.Object类,在java.lang.Object类中有一个方法clone()。JDK API的说明文档解释这个方法将返回Object对象的一个拷贝。要说明的有两点:一是拷贝对象返回的是一个新对象,而不是一个引用。二是拷贝对象与用 new操作符返回的新对象的区别就是这个拷贝已经包含了一些原来对象的信息,而不是对象的初始信息。
1. Clone&Copy
假设现在有一个Employee对象,Employee tobby =new Employee(“CMTobby”,5000),通
常我们会有这样的赋值Employee cindyelf=tobby,这个时候只是简单了copy了一下reference,cindyelf和tobby都指向内存中同一个object,这样cindyelf或者tobby的一个操作都可能影响到对方。打个比方,如果我们通过cindyelf.raiseSalary()方法改变了salary域的值,那么tobby通过getSalary()方法得到的就是修改之后的salary域的值,显然这不是我们愿意看到的。我们希望得到tobby的一个精确拷贝,同时两者互不影响,这时候我们就可以使用Clone来满足我们的需求。Employee cindy=tobby.clone(),这时会生成一个新的Employee对象,并且和tobby具有相同的属性值和方法。
2. Shallow Clone&Deep Clone
Clone是如何完成的呢?Object在对某个对象实施Clone时对其是一无所知的,它仅仅是简单地执行域对域的copy,这就是Shallow Clone。这样,问题就来了咯,以Employee为例,它里面有一个域hireDay不是基本型别的变量,而是一个reference变量,经过Clone之后就会产生一个新的Date型别的reference,它和原始对象中对应的域指向同一个Date对象,这样克隆类就和原始类共享了一部分信息,而这样显然是不利的,过程下图所示:
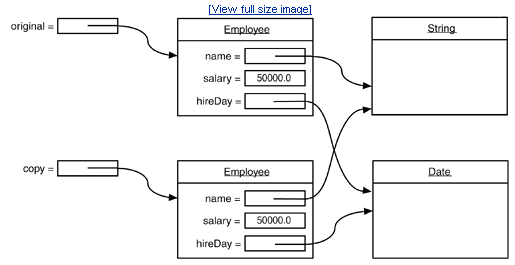
这个时候我们就需要进行deep Clone了,对那些非基本型别的域进行特殊的处理,例如本例中的hireDay。我们可以重新定义Clone方法,对hireDay做特殊处理,如下代码所示:
class Employee implements Cloneable
{
public Object clone() throws CloneNotSupportedException
{
Employee cloned = (Employee) super.clone();
cloned.hireDay = (Date) hireDay.clone()
return cloned;
}
}
3. Clone()方法的保护机制
在Object中Clone()是被申明为protected的,这样做是有一定的道理的,以Employee
类为例,通过申明为protected,就可以保证只有Employee类里面才能“克隆”Employee对象,原理可以参考我前面关于public、protected、private的学习笔记。
4. Clone()方法的使用
Clone()方法的使用比较简单,注意如下几点即可:
a. 什么时候使用shallow Clone,什么时候使用deep Clone,这个主要看具体对象的域是什么性质的,基本型别还是reference variable
b. 调用Clone()方法的对象所属的类(Class)必须implements Clonable接口,否则在调用Clone方法的时候会抛出CloneNotSupportedException。
部分内容来自于
{
Employee cloned = (Employee) super.clone();
cloned.hireDay = (Date) hireDay.clone()
return cloned;
}
}
3. Clone()方法的保护机制
在Object中Clone()是被申明为protected的,这样做是有一定的道理的,以Employee
类为例,通过申明为protected,就可以保证只有Employee类里面才能“克隆”Employee对象,原理可以参考我前面关于public、protected、private的学习笔记。
4. Clone()方法的使用
Clone()方法的使用比较简单,注意如下几点即可:
a. 什么时候使用shallow Clone,什么时候使用deep Clone,这个主要看具体对象的域是什么性质的,基本型别还是reference variable
b. 调用Clone()方法的对象所属的类(Class)必须implements Clonable接口,否则在调用Clone方法的时候会抛出CloneNotSupportedException。
部分内容来自于
[(1条消息) Java创建对象的四种方式_王温暖的博客-优快云博客_创建对象](https://blog.youkuaiyun.com/cpcpcp123/article/details/51353851)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









