









- 题目描述
小琛是一所学校的校长。
他的学校有n个校区(编号1~n),被n-1条双向道路连接,呈树形结构。
第i个校区共有Ai个学生。
第i天早上,所有的学生会沿最短路走到第i个校区参加活动,晚上再原路返回。
一个人通过第j条通道一次(即一人次),需要小琛支付wj的维护费用。
小琛想知道第n天结束之后,对于每一条通道,他总共需要支付多少费用。
对于100%的数据,1≤ n ≤ 200,000,1≤ A[i]≤ 10,000,1≤ w[i] ≤ 10,000。 - 输入描述:
第一行一个整数n,表示校区的数量。
接下来一行,n个整数,表示A1~An。
第3到第n+1行,每行包含3个整数。第i行包含三个整数ui-2,vi-2,wi-2,表示第i-2条通道所连接的两个校区的编号,以及一人次通过这条通道的费用。 - 输出描述:
共n-1行,每行一个整数。
第i行的整数表示小琛对于第i条通道所需支付的费用。 - 示例1
输入
4
2 1 2 3
1 3 1
1 2 3
4 1 2
输出
24
60
56
错误写法
#include <bits/stdc++.h>
using namespace std;
const int N=2e5+5;
int n,sums;//sums所有学生数
int a[N];//每个校区的人数
struct node{
int u,v,cost;
}edge[N];//每条路的端点和花费
int main()
{
cin>>n;
sums=0;
for(int i=1;i<=n;++i){
cin>>a[i];
sums+=a[i];
}
for(int i=1;i<=n-1;++i){
int u,v,cost;
cin>>u>>v>>cost;
if(u>v) swap(u,v);//把每条边的两个点按小大来排,大的负责这条边
//比如1 2 那就把边看做是校区2的
edge[i].u=u;
edge[i].v=v;
edge[i].cost=cost;
}
for(int i=1;i<=n-1;++i){
int ans=0;
//每条边就视为
//1.它这条边所在校区的学生到外面校区,外面有多少校区就要经过该边多少次
//2.外面校区学生到这个校区
ans+=(a[edge[i].v]*(n-1)+(sums-a[edge[i].v]))*edge[i].cost*2;
cout<<ans<<endl;
}
return 0;
}
这种情况是符合样例的,但是如果碰上下图中这种,多一层甚至几层的就有问题
比如对a-b这条边来说
1.它这条边所在校区的学生到外面校区,外面有多少校区就要经过该边多少次。外面有4个校区,但是经过该边的只有3个校区
2.外面校区学生到这个校区。同理,e校区的学生进到b校区也不用经过该边
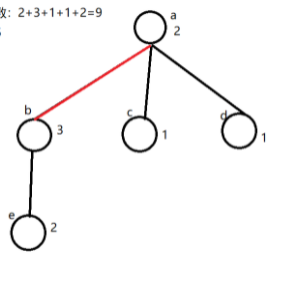
- 分析
对于该题,我们可以把它想象成树(题目说了)
那必有一个根节点,从根节点进入每一条分支,然后维护每一条边
如何维护边呢?
一条边连接了两个点,也就是两个校区a(假设为根节点),b,那就有a(以及和a相连的其他点)要通过边到b,也有b(以及与b相连的其他点)要通过边到a。
a(以及和a直接相连或间接相连的其他点)要通过边到b:
求出a下面几个结点的总学生人数(包括a),求出b下面有几个结点(包括b),a下面的所有学生都要通过a-b去到b下面的所有点
b(下面的点)要通过边到a:求b下面一共有多少学生(包括b),求出a下面有几个结点(包括a),b及下面的点的所有学生都必须通过a-b去到a以及其他点
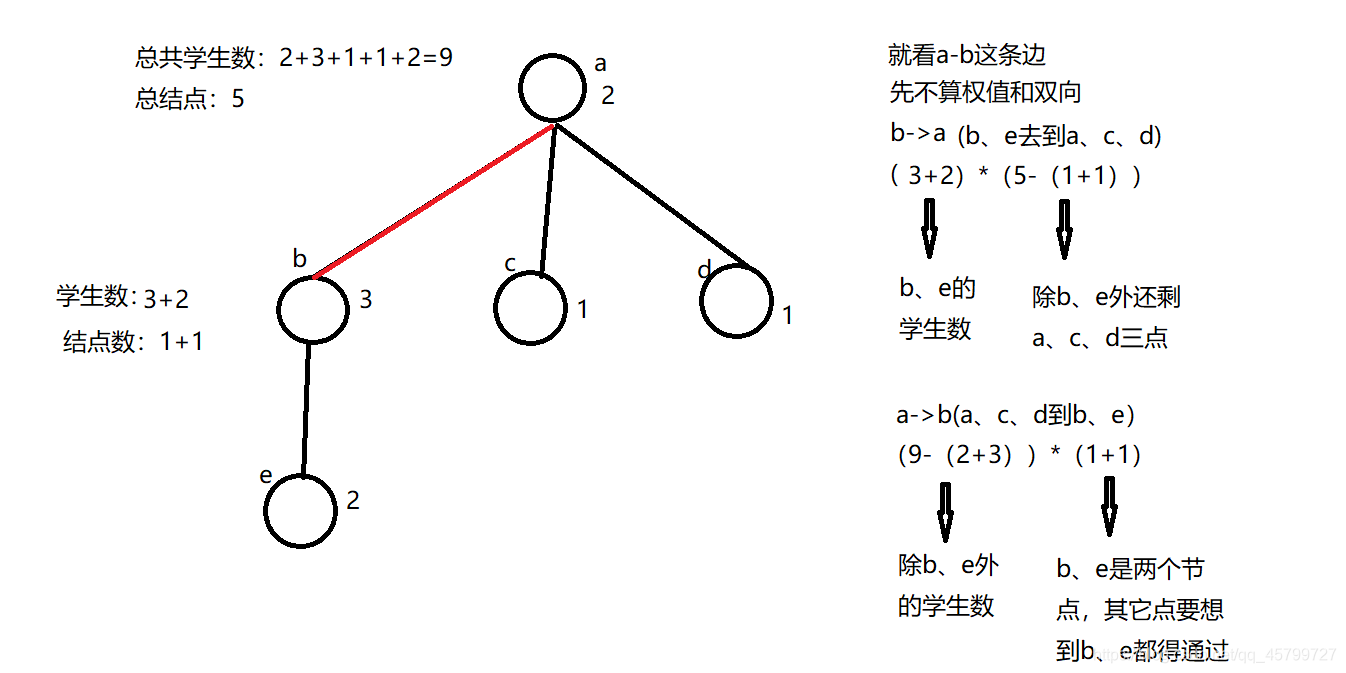 - 实现
- 实现
如何得到一个点下所有的学生数,以及所有的结点个数呢?
应该想到用dfs,从上层到下层,下层在得到结论后,再层层返回给上层使得上层有一个总体的认知
可以看到,叶子结点的总学生数就是它自己的学生数,总结点数就是1,即它自己,所以,在dfs到达叶子结点后,就能开始回传,上层结点通过对子节点的汇总最终得到数据
注意记得开long long,不开过不了,因为结点个数有2e5个,每个节点的学生也有1e4,边的权重有1e4,乘一下会很大
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N=2e5+5;
struct node{
int v,w,id;
};
vector<node>ve[N];
ll a[N],sum[N],sub[N],ans[N];//sum[i]存i这一点i以下的点的学生总数,sub[i]存i这一点i以下的点的个数
int n;
ll tot;
void dfs(int u,int pre){
sum[u]=a[u];sub[u]=1;//sub[u]初始化为1,就它自己一个节点
for(int i=0;i<ve[u].size();++i){
int v=ve[u][i].v;
int w=ve[u][i].w;
int id=ve[u][i].id;
if(v==pre) continue;//pre这个点就不要再深搜了,因为当初就是由pre到v的,再dfs会死循环
dfs(v,u);
sum[u]+=sum[v],sub[u]+=sub[v];
ans[id]=(sum[v]*(n-sub[v])+sub[v]*(tot-sum[v]))*w;
//加号前部分是v即它以下的点出去到其他点,后部分是其他点进到v及它以下的点
}
}
int main()
{
cin>>n;
for(int i=1;i<=n;++i){
cin>>a[i];//每个校区的学生数
tot+=a[i];
}
for(int i=1;i<=n-1;++i){
int u,v,w;
cin>>u>>v>>w;
ve[u].push_back({v,w,i});
ve[v].push_back({u,w,i});
}//n-1条边 把每个点相连边的另一个点放到它的数组中
dfs(1,0);//从第一个点开始 0是一个树中没有的点,假设由这个点进入到1点 这种方法注意一下
//为什么要有第二个参数?
//为了知道当前结点是从哪个结点传进来的,即标记一下父结点
//因为上面记录边的方式是看不出父结点,只知道相邻,
//而汇总sum sub是要汇总下面结点的,即要排除父结点
for(int i=1;i<n;++i) cout<<ans[i]*2<<endl;
return 0;
}
补充:理解一下dfs()的结构
两个参数传进去,第一个参数表示即将进入的点,第二个参数表示从哪个点进入,可以理解为第二个点是第一个点的父结点
为什么要这样设计呢?
因为我们算ans数组的时候需要sum数组和sub数组,这两个数组可以通过不断地深搜再回溯得到,但是当初我们加边的时候,点和点之前是互相加到对方的ve数组里,没有区分谁是谁的父结点。我们传入两个参数就是为了能把父结点区分出来,这样得到的sum数组和sub数组才是我们想要的,才能计算出ans
也可以不用两个参数,在标记边的时候,就只记一侧,比如a-b,就记
a->b,到时候在b的相邻边里就可以不用判断有没有a了
#include <bits/stdc++.h>
using namespace std;
typedef long long ll;
const int N=2e5+5;
struct node{
int v,w,id;
};
vector<node>ve[N];
ll a[N],sum[N],sub[N],ans[N];//sum[i]存i这一点i以下的点的学生总数,sub[i]存i这一点i以下的点的个数
int n;
ll tot;
void dfs(int u){
sum[u]=a[u];sub[u]=1;//sub[u]初始化为1,就它自己一个节点
for(int i=0;i<ve[u].size();++i){
int v=ve[u][i].v;
int w=ve[u][i].w;
int id=ve[u][i].id;
//if(v==pre) continue;//注释掉
dfs(v);
sum[u]+=sum[v],sub[u]+=sub[v];
ans[id]=(sum[v]*(n-sub[v])+sub[v]*(tot-sum[v]))*w;
}
}
int main()
{
cin>>n;
for(int i=1;i<=n;++i){
cin>>a[i];//每个校区的学生数
tot+=a[i];
}
for(int i=1;i<=n-1;++i){
int u,v,w;
cin>>u>>v>>w;
if(u>v) swap(v,u);
ve[u].push_back({v,w,i});
//ve[v].push_back({u,w,i});注释掉
}//n-1条边 把每个点相连边的另一个点放到它的数组中
dfs(1);
for(int i=1;i<n;++i) cout<<ans[i]*2<<endl;
return 0;
}


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









