



一、计算机组成与体系结构
1、计算机基础
数据的表示
进制转换
进制转换:短除法、减法、按权展开法。
码制
原码:最高位符号位,其余低位表示数值。范围:
反码:整数的反码与原码相同,负数的反码其绝对值按位取反(符号位不变)。范围:
补码:正数的补码与原码相同,负数的补码是其反码+1(符号位不变).范围:
移码:补码的符号位取反。
0的补码表示是唯一的,原码和反码不一致,但补码一致。0有-0和+0.
浮点数的表示
浮点的格式:
- 尾数*基数^指数。
- 尾数用补码表示,阶码用移码表示:阶码的位数决定定数范围;尾数的位数决定树的精度。
浮点数计算过程:对阶(小阶向大阶看齐,尾数右移)
算术与逻辑运算
- 逻辑或(||、OR)连接两个逻辑值全为0才取0.
- 逻辑与(&&、AND)两个逻辑值全为1才取1
- 逻辑异或(XOR)连接两个逻辑不相同才取1,相同取0;
- 逻辑非(NOT、!)将逻辑取反即可
校验码
- 奇偶校验码:可检查奇数个数位的错误,不可纠错。
- CRC循环冗余校验码:可检错,不可纠错,采用模二除法
- 海明校验码:既可检错,又可纠错;检验校验码的位数公式:
系统总线常用来连接计算机的各个部件。
寄存器和运算器主要用片内总线连接。接口外设、DMA控制器和中断控制器由外部总线进行连接。
系统开发基础:
- 数据耦合:一个模块访问另一个模块,彼此通过简单数据参数(不是控制参数、公共数据结构和外部变量)来交换、输出信息。
- 标记耦合:一组通过参数表传递记录信息。
- 控制耦合:如果一个模块通过开关、标识、名字等控制信息,明显控制另一个模块功能,就是控制耦合。
- 公共耦合:若一组模块访问同一个公共数据环境,则它们之间耦合就叫公共耦合。
web防火墙认为内部是安全的,只会对外部请求进行处理。
默认情况下:Linux系统使用Apache服务器使用/home/httpd作为默认目录。
IIS是window系统常见web服务器,DFS文件系统服务器。
2、计算机组成
CPU的组成(运算器与控制器)
运算器
- 算术逻辑单元ALU:数据的算术运算和逻辑运算
- 累加寄存器AC:通用寄存器,为ALU提供工作区,暂存数据
- 数据缓冲寄存器DR:写内存时,暂停指令或数据
- 状态条件寄存器PSW:存状态与控制标志
控制器
- 程序计数器PC:下一条指令的地址
- 指令寄存器DR:即将执行的指令
- 指令译码器ID:对指令的操作码字段进行分析解释
- 时序部件:提供时序控制信号
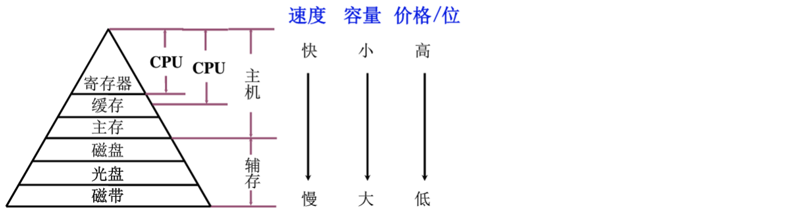
存储系统
层次化存储结构
- CPU:寄存器最快,但容量小,成本高。
- cache:按内容进行存取
- 内存:RAM随机寄存器、ROM只读存储器
- 外存:硬盘、光盘、U盘等
- 局部性原理是层次化存储结构的支撑:时间局部性(刚被访问的内容,立即又被访问);空间局部性(刚被访问的内容,临近的空间很快被访问)
速度(快-慢):CPU(寄存器、缓存)、主存、磁盘
cache
- 直接相连映象:冲突率高、电路简单
- 全相联映像:冲突率低、电路复杂
- 组相联映像:冲突率中、电路复杂折中
主存编码计算
- 存储单元个数=最大地址-最小地址+1
- 编码内容:按字编址(存储单元以字为存储单元,最小寻址是一个字);按字节编址(存储单元以字节为存储单元,最小寻址一字节)
- 总容量=存储单元个数*编码内容
- 总片数=总容量/每片容量
输入输出技术
- 程序查询方式:方法简单,硬件开销小,但I/O能力不高,严重影响CPU利用率
- 程序的中断方式:与程序控制方式相比,中断方式因为CPU无须等待而提高传输请求的响应速度
- DMA方式:DMA方式是为了在主存和外设之间实现高速、批量的数据交换而设置的
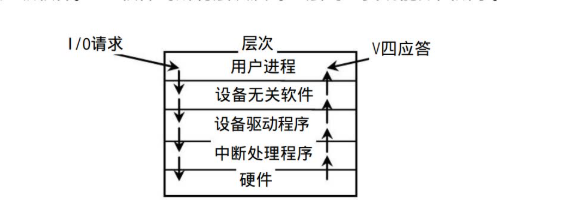
IO设备管理器一般分为4层:中断处理程序、设备驱动程序、与设备无关的系统软件和用户级软件
总线系统
3、指令系统
寻址方式
- 零地址指令/一地址指令/二地址指令/三地址指令:指令分类
- 寻址方式
- 立即寻址:操作数直接在指令上,速度快,灵活性差
- 直接寻址:指令中存放的是操作数地址
- 间接寻址:指令中存放一个地址,这个地址对应的内容是操作数的地址
- 寄存器寻址:寄存器存放操作数
- 寄存器间接寻址:寄存器内存放的是操作数的地址。
由快——>慢:立即寻址、寄存器寻址、直接寻址、寄存器间接寻址、间接寻址。
CISC和RISC
- CISC(复杂指令集):数量多、支持多种寻址方式、微程序实现、研制周期长。一条指令干一堆活,硬件复杂
- RISC(精简指令集):数量少、定长格式、支持方式少,增加了统通用寄存器和硬布线逻辑控制、适合流水线技术。一条指令干一点活,靠多指令+优化速度
流水线技术
- 流水线周期为执行时间最长的一段
- 计算公式:1条指令执行时间+(指令条数-1)*流水线周期
4、可靠性
可靠性指标
- 可靠性:MTTF
- 可用性:MTBF
串联与并联系统
- 串联
- 并联
计算机性能指标
- 主频(计算机参数),时钟周期=主频倒数,主频=倍频*外频
- 平均每条指令的平均周期个数(CPI,clock per instruction),CPI=时钟周期总数/指令总条数
- 每(时钟)周期运行指令条数(IPC)IPC=指令总条数/时钟周期总数
- 百万条指令每秒(MIPS)=(IPC*时钟周期)/106
- 每秒百万浮点操作(MFLOPS)浮点操作
- 字节
- 总线宽度:每次脉冲通过的数据量
- 带宽:单位时间通过的数据量,带宽=数据总理/总时间
- 吞吐量,某个时间段内完成的任务总数;吞吐率,单位时间内完成的任务总数,吞吐率=任务总数/总时间
系统开发基础
软件工程概述
信息系统的基本生存周期
可行性分析-需求分析-概要设计-详细设计-编码-维护-测试
软件过程改进
CMM能力成熟度模型
- 初始级:杂乱无章,甚至混乱,几乎没有明确定义的步骤
- 可重复级:建立了基本项目管理过程和实践来跟踪项目费用、进度和功能特性。
- 已定义级:管理和工程两方面软件过程已经文档化、标准化
- 已管理级:制定了软件过程和产品质量的详细度量标准
- 优化级:加强定理分析,通过来自过程质量反馈和来自新技术的反馈过程能不断持续改进
CMMI连续式能力成熟度模型
- CL0(未完成):未执行或未得到
- CL1(已执行):可标准的输入工作产品转换成可标识的输出工作
- CL2(已管理):已管理的过程制度化
- CL3(已定义级):已定义的过程制度化
- CL4(定量管理):可定理管理的过程制度化
- CL5(优化的):量化手段改变和优化过程域
软件开发方法
- 结构化开发方法:需求明确,自顶向下,逐步分解
- 原型法:需求不明确
- 面向对象开发方法:更好的复用性、适合系统项目大。
在面向对象方法中,对象是基本的运行实体,它既包括数据(属性),也包括用于数据的操作(行为),即一个对象把属性和行为封装为一个整体。所有属性以及属性的当前值表示对象的状态
软件开发模型
瀑布模型与V模型
瀑布模型:以文档为驱动、适合软件需求很明确的软件项。
V模型:测试贯穿始终
演化模型(原型模型、螺旋模型)
- 演化模型:迭代的过程模型,适合软件需求缺乏准确认识的情况
- 原型模型:适合需求不明确经常变化的情况,系统规模不是很大也不复杂
- 螺旋模型:瀑布模型和演化模型的结合,加入了风险分析,特别适合庞大、复杂具有高风险的系统
增量模型
第一个增量往往是核心产品。将需求分段为一系列增量产品,每个增量可以分别开发
喷泉模型
以用户需求为动力,以对象作为驱动的模型,适合面向对象模型的开发方法,迭代无间隙
统一过程UP
用例为驱动,以架构为中心,迭代且增量
敏捷方法
- 尽可能早的、持续地对有价值的软件交付,使客户满意。“小步快跑思想”适合小项目
- 极限编程XP:4大价值观、5个原则、12个最佳实践
- 水晶法:以人为本、每个项目都需要一套不同的策略、约定和方法论、
- 开发式源码:程序开发人员在地域上分布很广
- 并列争球法:每30天依次的迭代作为一个冲刺
- 功能驱动PDF:首席程序员和类程序员
- 自适应软件开发ASD:三个非线性开发阶段:猜测、合作与学习
需求分析
需求分析相关概念
结构化分析结果:一套分层的数据流图,一本数据词典,一组小说明、补充材料
需求的分类
- 功能需求
- 性能需求
- 设计约束
需求分析的工具
- 数据流图与数据字典
- 决策表与决策树
系统设计
系统设计概述
设计概要与详细设计
抽象化、自顶向下、逐步求精、信息隐蔽、模块独立(高内聚、低耦合)
系统设计任务
- 体系结构设计
- 数据设计
- 接口设计
- 过程设计
模块设计
内聚性
内聚类型与模块之间部分功能之间的关系有关。
- 功能内聚:完成单一功能,各个部分协同工作,缺一不可
- 顺序内聚:处理元素相关,而且必须顺序执行
- 通信内聚:所有处理元素集中在一个数据结构的区域上
- 过程内聚:处理元素相关,而且必须按照特定的次序执行
- 瞬时内聚:所包含的任务必须在同一时间间隔内执行
- 逻辑内聚:完成逻辑上相关的一组任务
- 偶然内聚:完成一组没有关系或松散关系的任务
耦合性
耦合是各个模块之间的相对独立性的度量。耦合取决于各个模块之间接口的复杂程度、调用模块的方式以及通过接口的信息类型。
- 非直接耦合:两个模块没有直接关系
- 数据耦合:一组模块借助参数表传递简单数据
- 标记耦合:一组模块通过参数表传递记录数据
- 控制耦合:模块之间传递的信息包含控制模块内部逻辑信息
- 外部耦合:一组模块都访问同一个简单变量,而且不是通过参数传递该全局变量的信息
- 公共耦合:多个模块都访问同一个公共数据环境
- 内容耦合:一个模块直接访问另一个模块的内部数据
其他原则
保持模块的大小适中、尽可能减少调用深度、多扇入,少扇入、单入口、单出口、模块的作用域在模块之内、功能应该是可以预测的
人机界面设计
- 置于用户控制之下
- 减少用户的记忆负担
- 保持界面的一致性
软件测试
软件测试的基本概念与分类
测试的目的为了找出程序的错误
黑盒测试
- 等价类划分:确定无效和有效等价类,设计用例尽可能多的覆盖有效类,设计用例只覆盖一个无效类
- 边界分析:选取的测试数据恰好等于、稍小于或稍大于边界值
白盒测试
- 语句覆盖:被测试中每条语句至少执行一次
- 判定覆盖:被测试的每个判定至少获得“真”“假”值各一次
- 条件覆盖:每一个判定语句中每个逻辑条件的各种可能值至少满足一次
- 判定/条件覆盖:判定中每个条件的所有可能取值,至少出现一次,并使用每个判定本身的判定结果也至少出现一次
- 路径覆盖:覆盖被测试程序中所有可能的路径
测试阶段划分
- 单元测试:模块测试,模块功能、性能、接口等
- 集成测试:模块间测试
- 系统测试:真实环境下,验证完整的软件配置项能否和系统正确连接
- 确认测试:验证软件与需求的一致性
- 回归测试:测试软件变更之后,变更部分正确性对变更需求的符合性
面向对象软件测试可分为四个层次
- 算法层:测试类中定义的每个方法
- 类层:测试封装在同一个类中的所有方法与属性之间的相互作用
- 模板层:测试一组协同工作的类之间的相互作用
- 系统层:把各个子系统组装成完整的面向对象软件系统,在组装过程中进行测试
MaCabe复杂度计算
=边-节点+2
或 闭合区域+1
软件维护
软件开发和维护过程涉及种类繁多的工序,可以分为软件开发工具、软件维护工具、软件管理工具和支持工具。其中软件维护工具包括控制工具、文档分析工具、开发信息工具、逆向工程工具和再工程工具。
可维护因素决定
- 可理解性
- 可测试性
- 可修改性
软件维护分类
- 改正性维护:改正程序中出现的错误
- 适应性维护:适应环境的改变
- 预防性维护:未雨绸缪,提前预防
- 完善性维护:扩充功能和改善性能进行修改
软件文档
软件设计一般分为两个阶段:概要设计和详细设计。概要设计主要进行软件体系结构设计,逻辑数据结构设计,数据库设计和模块之间接口设计。而详细设计主要进行模块内部的数据结构和算法设计。
软件文档的作用:
- 1、提高软件开发过程的能见度;
- 2、提高开发效率;
- 3、作为开发人员在一定阶段的工作成果和结束标记
- 4、记录开发过程中的有关信息,便于协调以后的软件开发、使用和维护;
- 5、提供对软件的运行、维护和培训的相关信息;
- 6、便于潜在用户了解软件的功能、性能等各项指标。
开发文档
产品文档
管理文档
软件质量保证
功能性
- 适合性
- 准确性
- 互操作性
- 依从性
- 安全性
可靠性
- 成熟性
- 容错性
- 易恢复性
易用性
- 易理解性
- 易学性
- 易操作性
效率
- 时间特性
- 资源特性
维护性
- 易分析性
- 易改变性
- 稳定性
- 易测试性
可移植性
- 适用性
- 易安装性
- 一致性
- 易替换性
项目管理
进度管理
gantt图
- 关系
- 缺点:不能清晰地反映出各任务之间地依赖关系,难以确定整个项目地关键所在
pert图
- 优点:给出了每个任务地开始时间、结束时间和完成该任务所需地时间,还给出任务之间地关系
- 缺点:不能反映任务间地并行关系
- 关键路径:从开始到结束,需要时间最长地路径
- 总时差:在不延误总工期地前提下,该活动的动机时间
风险管理
- 项目管理
- 技术风险
- 商业风险
- 风险是指“损失或伤害的可能性”
成本管理
cocomoll模型:对象点、功能点、代码行。
沟通管理
- 无主程序员:计算公式n*(n-1)/2
- 有主程序员:计算公式n-1
其他
- 配置管理:软件配置项、版本控制、变更控制
- 人员管理
项目估算一般考虑规模、工作量、成本等因素,不考虑类型
标准化与知识产权
软件著作权属于软件开发者,软件著作权自软件开发完成之日起产生。
《计算机软件保护条例》是国务院颁布的。《著作权法》由全国人民代表大会常务委员会制定并颁布,是国家法律。
计算机软件著作权自开发完成之日产生,保护期50年。
主域名服务器在接收到域名请求后,查询顺序是本地缓存、本地 hosts 文件、本地数据库、转发域名服务器。
数据库
数据库的自然连接:是数据库中一种特殊的等值连接,它自动在两个表中所有同名的列上进行匹配,并只保留一份重复的列。这是它最核心的特点。
内连接:需要写ON和USING。不去重复列
左连接:需要写ON。不去重复列
右连接:需要写ON。不去重复列
全外连接:需要写ON。不去重复列
交叉连接:不需要(笛卡尔集),不去重。
例子:假设有两个表,
Student(SID, Name, Dept)
Dept(DID, Dept, Location)
自然连接
SELECT * FROM Student NATURAL JOIN Dept;
内连接
SELECT * FROM Student JOIN Dept ON Student.Dept = Dept.Dept;
左连接
-- 把左边表的所有行都保留,右边没匹配的填 NULL
SELECT *
FROM 表A
LEFT JOIN 表B
ON 表A.公共列 = 表B.公共列;
右连接
-- 把右边表的所有行都保留,左边没匹配的填 NULL
SELECT *
FROM 表A
RIGHT JOIN 表B
ON 表A.公共列 = 表B.公共列;

















 856
856

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









