







 本文介绍了跳表的数据结构特点及应用,包括查找、插入和删除等操作,并对比了快速排序和堆排序在不同数据量下的效率表现。
本文介绍了跳表的数据结构特点及应用,包括查找、插入和删除等操作,并对比了快速排序和堆排序在不同数据量下的效率表现。
算法复习
跳表
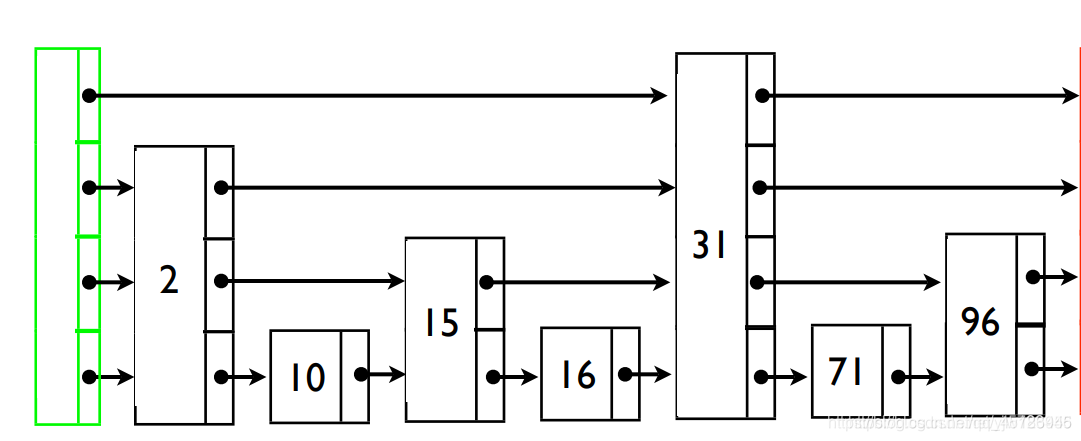
定义:为一个值有序的链表建立多级索引,比如每2个节点提取一个节点到上一级,我们把抽出来的那一级叫做索引或索引层。其中down表示down指针,指向下一级节点。以此类推,对于节点数为n的链表,大约可以建立log2n-1级索引。像这种为链表建立多级索引的数据结构就称为跳表。
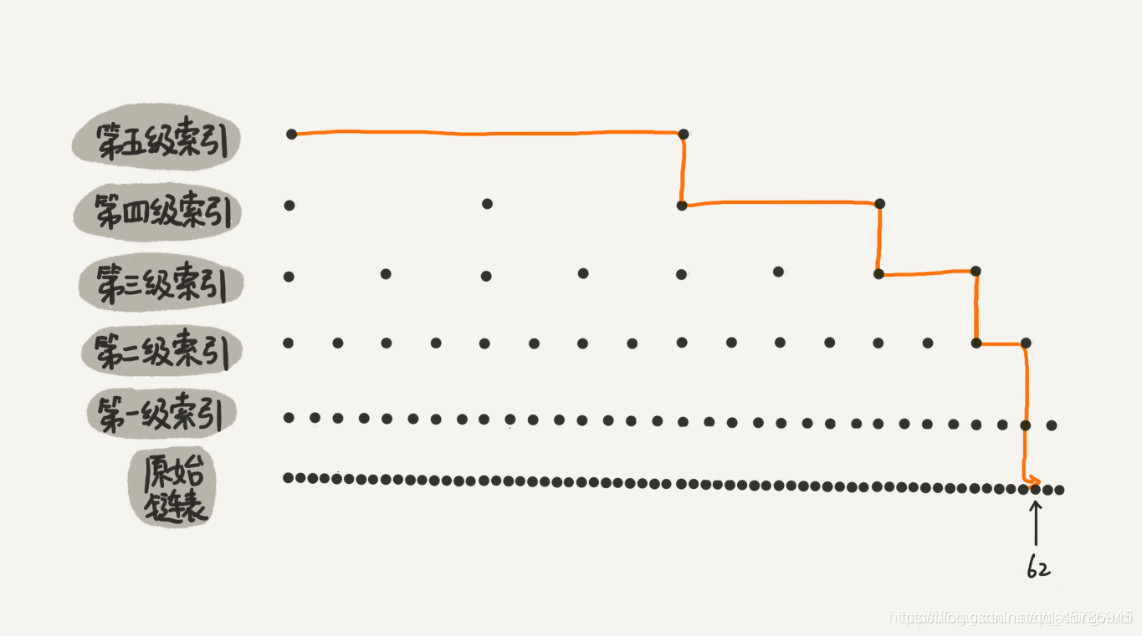
查找方式:从最上面一层索引开始,假设寻找y,在第一层索引找到x和z,x<y<z,那么就沿着x的down指针向下找,递归。
跳表的高度(空间):第一层有n/2个,第二层有n/4个,第k层n/2^k个。
假设索引有h级别,最高级的索引有2个节点,则有n/(2^h)=2,得出h=log2n-1,包含原始链表这一层,整个跳表的高度就是log2n。
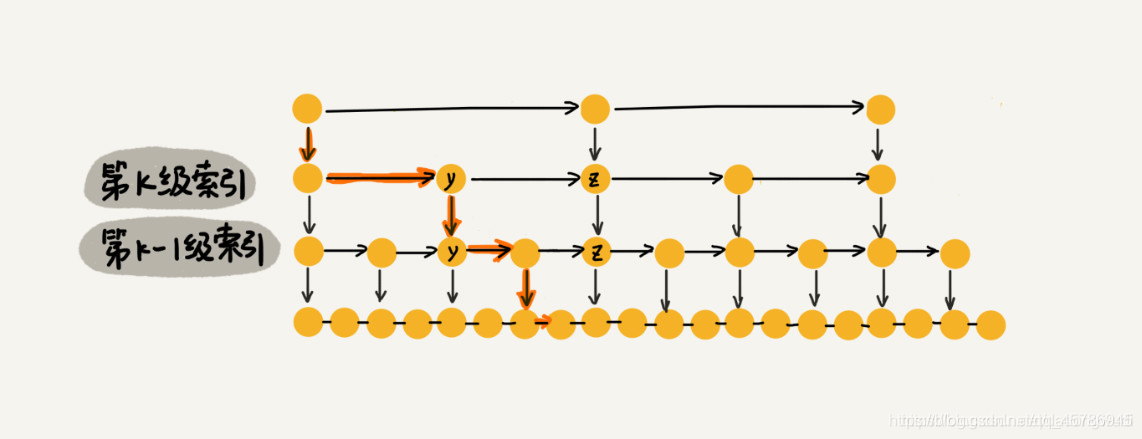
时间复杂度:可以看出最后一层索引只会遍历3个索引,这3个索引的头在上一层也是如此,递归。每一级索引都最多只需要遍历3个节点。所以m=3(与间距有关)。因此在跳表中查询某个数据的时间复杂度就是O(logn)。
通过扩大间隔,可以减少层数,提高时间性能,比如最下面一层索引的范围是n/2^k
现在变成n/3^k,层数就减少了,自然节约了时间性能。
对于按照区间查找数据这个操作,跳表可以做到 O(logn) 的时间复杂度定位区间的起点,然后在原始链表中顺序往后遍历就可以了。
对于插入节点,随机生成待插入节点的层数。
节点的删除:根据查找算法,理论上是可以在一次查找过程中找到它的前驱节点,并进行删除的。
图的中心问题
对于一个图,建立一个中心节点,使得到这个点的最大距离最小。先用弗洛伊德算法求出到各个顶点的,不同临节点的最短距离,然后在所有顶点的最长距离中选择最小的,就是中心节点的距离。
快速排序和堆排序效率比较
1.10w 数据量两种排序速度基本相当,但是堆排序交换次数明显多于快速排序;10w+数据,随着数据量的增加快速排序效率要高的多,数据交换次数快速排序相比堆排序少的多。
堆排序还会有可能产生无谓的开销,比如取出一个元素后,把最后一个元素拿到堆顶,然后调整之后发现又回到了堆底,浪费了交换的开销,最坏的维护开销可能达到nlogn。
2.堆排序时间复杂度是nlogn,快排如果选择的基准不当可能会达到n^2的复杂度。如果对快排改进成插值排序可能会好些。
补充:对于基于比较的排序算法来说,整个排序过程就是由两个基本的操作组成的,比较和交换(移动)。快速排序数据交换的次数不会比逆序度多。但是堆排序的第一步是建堆,建堆过程会打乱数据原有的相对先后顺序,导致数据的有序度降低。比如,对于一组已经有序的数据来说,经过建堆之后,数据反而变得更无序了。
3.快速排序是顺序访问数据,堆排序是跳跃访问数据,当数据大了之后,开销就超过指数级别增长。


















 2609
2609

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











