










 本文介绍了双链表的概念,对比了双链表与单链表的区别,强调双链表可逆向检索但存储密度较低。内容涵盖双链表的初始化、插入、删除和遍历操作,并指出双链表的查找操作只能通过遍历完成,时间复杂度为O(n)。
本文介绍了双链表的概念,对比了双链表与单链表的区别,强调双链表可逆向检索但存储密度较低。内容涵盖双链表的初始化、插入、删除和遍历操作,并指出双链表的查找操作只能通过遍历完成,时间复杂度为O(n)。
图片均来自B站王道考研(侵删)
单链表.VS.双链表:
单链表:无法逆向检索,有时候不太方便
双链表:可进可退,存储密度更低一点
双链表:
1.初始化(带头结点)
typedef struct DNode{ //定义双链表节点类型
ElemType data; //数据域
struct DNode *prior,*next; //前驱和后继指针(prior.先前的)
}DNode,*DLinkList;
//初始化双链表
bool InitDLinkList(DLinkList &L){
L = (DNode *)malloc(sizeof(DNode)); //分配一个头结点
if(L==NULL) //内存不足,分配失败
return false;
L->prior = NULL; //头结点的prior永远指向NULL
L->next = NULL; //头结点之后暂时还没有结点
return true;
}
//判断双链表是否为空(带头结点)
bool Empty(DLinkList L){
if(L->next == NULL)
return false;
else
return true;
}
void testDLinkList(){
//先声明双链表,再初始化双链表
DLinkList L;
InitDLinkList(L);
//后续代码...
}
2.插入
//①在p结点之后插入s结点
bool InsertNextDNode(DNode *p,DNode *s){
s->next = p->next; //将节点*s插入到结点*p后
p->next->prior = s; //把p的后继结点的前向指针指向此次新插入的s结点
s->prior = p;
p->next = s;
return true;
}//但是此种方法会有一个问题,就是第二句回应魏p是最后一个节点而产生空指针的错误
//②在p结点之后插入s结点
bool InsertNextDNode(DNode *p,DNode *s){
if(p==NULL || s==NULL) //非法参数
return false;
s->next = p->next;
if(p->next!=NULL) //如果p结点有后继节点
p->next->prior = s;
s->prior = p;
p->next = s;
return true
}
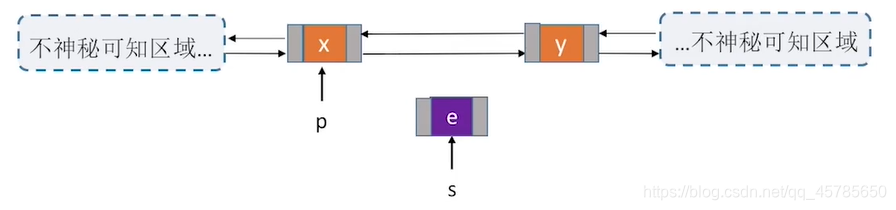
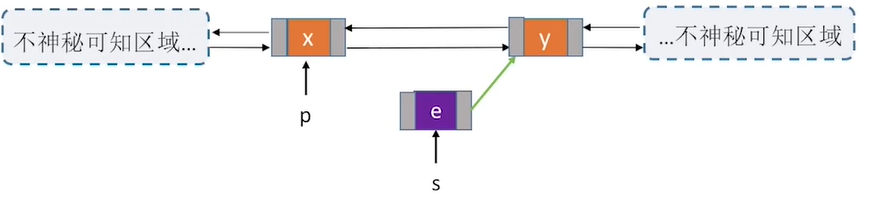
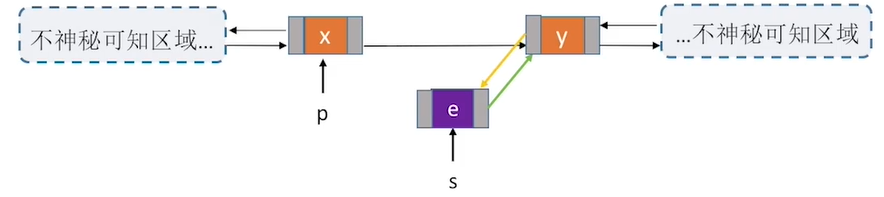
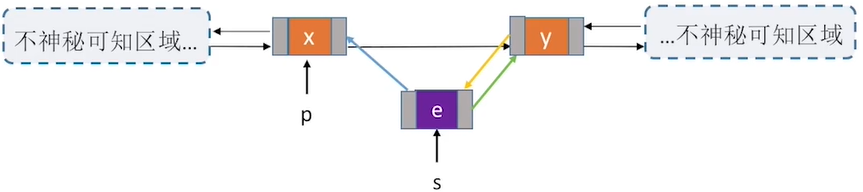
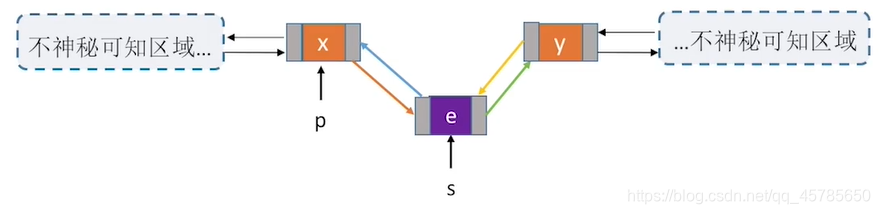
用后插操作实现结点的插入有什么好处?
3.删除
//删除p结点的后继节点q
bool DeleteNextDNode(DNode *p){
if(p==NULL)
return false;
DNode *q = p->next; //找到p的后继结点q
if(q==NULL)
return false; //p没有后继
p->next = q->next;
if(q->next!=NULL) //q结点不是最后一个节点
q->next->prior = p;
free(q);
return true;
}
//销毁一个双链表
void DestoryList(DLinkList &L){
//循环释放各个数据节点
while(L->next!=NULL) //每次循环都删除这个头指针的后继节点
DeleteNextDNode(L);
free(L); //释放头结点
L = NULL; //头指针指向NULL
}

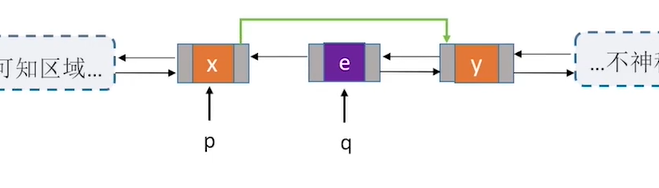
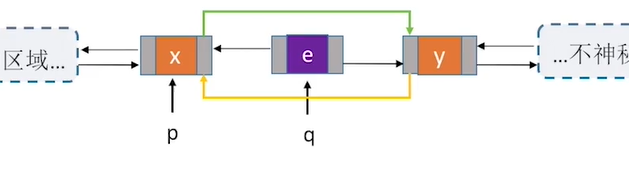
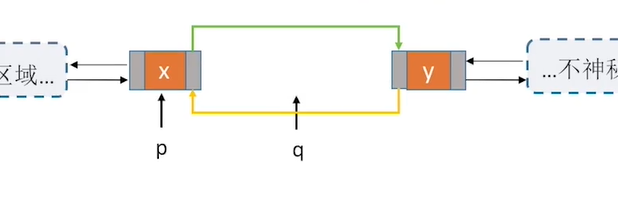
4.遍历
双链表不可随机存取,按位查找、按值查找操作都只能用遍历的方式实现。时间复杂度为:O(n)
按位查找,在对节点p做处理时,添加i++即可;按值查找,在对p结点处理时添加元素的对比即可
//后向遍历
while(p!=NULL){
//对结点p做相应处理,比如打印..
p = p->next;
}
//前向遍历
while(p!=NULL){
//对结点p做相应处理,比如打印..
p = p->prior;
}
//前向遍历(跳过头结点)
while(p->prior!=NULL){
//对结点p做相应处理,比如打印..
p = p->prior;
}
小结:


















 3369
3369

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









