







网页文本获取
import requests
url='https://www.baidu.com'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0'
}
html=requests.get(url,headers=headers).text
print(html)
xpath的标签定位
| nodename | 选取此节点的所有子节点 |
|---|---|
| / | 从根节点选取 |
| // | 从匹配选择的当前节点选择文档中的节点,而不考虑它们的位置。 |
| . | 选取当前节点 |
| … | 选取当前节点的父亲节点 |
| @ | 选取属性 |
需求分析
根据当前页面的URL找规律
请求网页,获取网页数据
数据解析,得到title和子域名
对这个子域名发起请求得到url
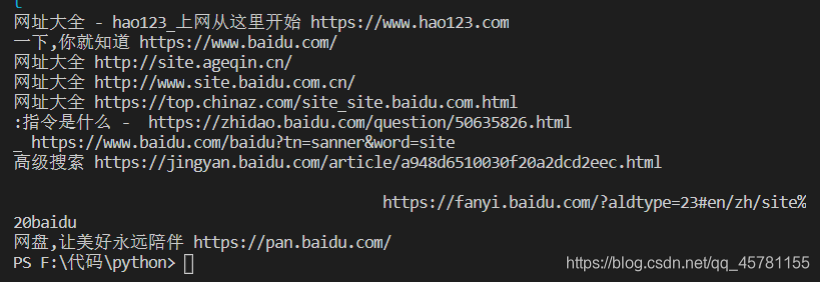
百度子域名获取
import requests
from lxml import etree
url='https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&tn=monline_7_dg&wd=site baidu'
headers={
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0'
}
html=requests.get(url,headers=headers).text
tree=etree.HTML(html)
list = tree.xpath('//div[@id="content_left"]/div')
for li in list:
title = li.xpath('./h3/a/text()')
if title != []:
href_url = li.xpath('./h3/a/@href')[0]
new_url = requests.get(url=href_url,headers=headers).url
print(title[0],new_url)


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









