






 该博客通过TensorFlow2.0实现了一个深度学习的全连接神经网络(DNN)模型,对IMDB电影评论数据集进行情感分析的二分类任务。首先加载并预处理数据,然后构建DNN模型,包括三层全连接层,并使用RMSprop优化器、二元交叉熵损失函数及准确率作为指标。在训练过程中,观察并记录训练与验证集的损失和准确率变化。最后,模型在测试集上评估并进行预测。
该博客通过TensorFlow2.0实现了一个深度学习的全连接神经网络(DNN)模型,对IMDB电影评论数据集进行情感分析的二分类任务。首先加载并预处理数据,然后构建DNN模型,包括三层全连接层,并使用RMSprop优化器、二元交叉熵损失函数及准确率作为指标。在训练过程中,观察并记录训练与验证集的损失和准确率变化。最后,模型在测试集上评估并进行预测。
目的:使用IMDB电影评论数据集进行二分类实验,基于深度学习的全连接神经网络模型DNN
平台:pycharm,tensorflow2.0
代码:
"""
# -*- coding: utf-8 -*-
@author: SYM
@software: PyCharm
@time: 2022/5/10 0010 10:52
"""
#from keras.datasets import imdb
#import numpy as np
#from keras import models
#from keras import layers
#2.0需要使用后面的
from tensorflow.keras import models
from tensorflow.keras import layers
import matplotlib.pyplot as plt
#from keras.datasets import imdb
#(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
import numpy as np
old = np.load
np.load = lambda *a,**k: old(*a,**k,allow_pickle=True)
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(num_words=10000)
#(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=10000)
# #第一条评论的单词索引列表
# print(train_data[0])*
# #1表示正面品论,0表示负面评论2
# print(train_labels[0])
# #取所有测试单词所有的最大的索引值
# print(max([max(sequence) for sequence in train_data]))
# #某条评论解码为英文
# word_index = imdb.get_word_index()
# reverse_word_index = dict(
# [(value,key) for (key,value) in word_index.items()]
# )
# decoded_review = ' '.join(
# [reverse_word_index.get(i-3,'?') for i in train_data[0]]
# )
# print(decoded_review)
#转换为10000维的向量,索引的位置是1,其他位置是0
def vectorize_sequences(sequences,dimension=10000):
results = np.zeros((len(sequences),dimension))
for i, sequence in enumerate(sequences):
results[i,sequence] = 1.
return results
#数据向量化
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
print(x_train[0])
#标签向量化
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
#模型定义
model = models.Sequential()
#第一层全连接层
model.add(layers.Dense(16,activation='relu',input_shape=(10000,)))
#第二层全连接层
model.add(layers.Dense(16,activation='relu'))
#第三层全连接层
model.add(layers.Dense(1,activation='sigmoid'))
#定义优化器,损失函数,指标
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
#取10000用于验证集
x_val = x_train[:10000] #验证集
partial_x_train = x_train[10000:]
y_val = y_train[:10000] #验证集
partial_y_trail = y_train[10000:]
#训练模型
history = model.fit(partial_x_train,
partial_y_trail,
epochs=4,
batch_size=512,
validation_data=(x_val,y_val))
history_dict = history.history
print(history_dict.keys())
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
acc_values = history_dict['accuracy']
val_acc_values = history_dict['val_accuracy']
epochs = range(1,len(loss_values)+1)
# plt.plot(epochs,loss_values,'bo',label='Training loss') #bo是蓝色圆点
# plt.plot(epochs,val_loss_values,'b',label='Validation loss') #b是蓝色实线
# plt.title('Training and validation loss')
# plt.xlabel('Epochs')
# plt.ylabel('Loss')
# plt.legend()
# plt.show()
#
# plt.clf() #清空图表
#acc_values = history_dict['accuracy']
#val_acc_values = history_dict['val_accuracy']
# plt.plot(epochs,acc_values,'bo',label='Training acc') #bo是蓝色圆点
# plt.plot(epochs,val_acc_values,'b',label='Validation acc') #b是蓝色实线
# plt.title('Training and validation accuracy')
# plt.xlabel('Epochs')
# plt.ylabel('Accuracy')
# plt.legend()
# plt.show()
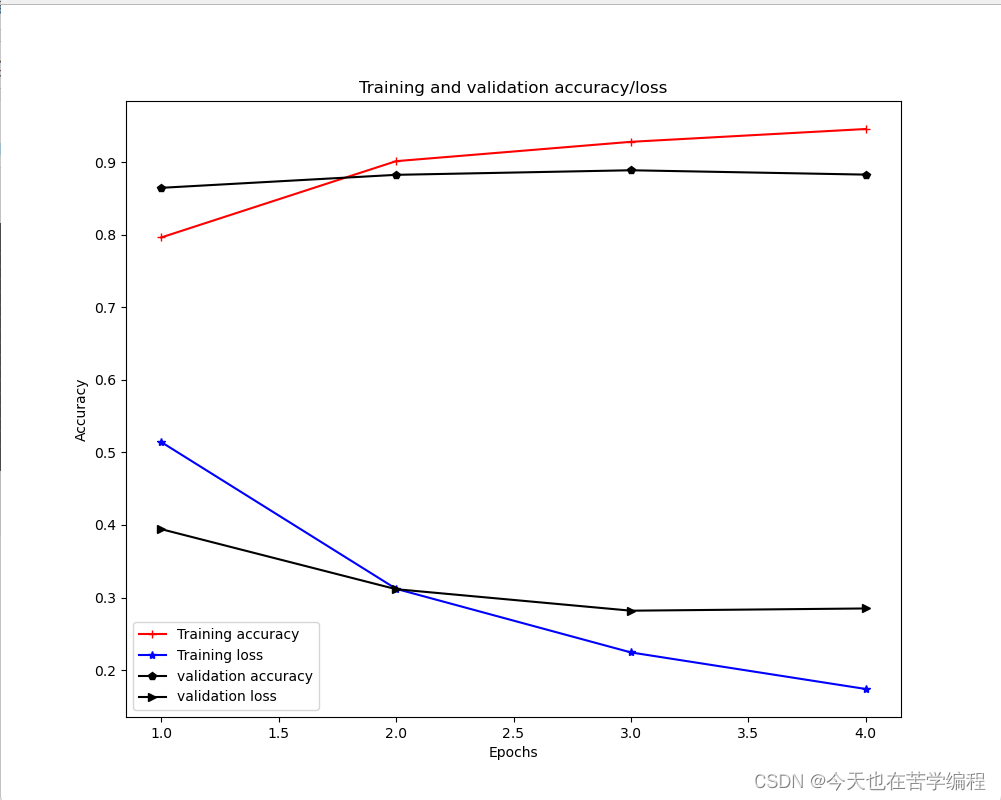
plt.figure(figsize=(10,8))
plt.plot(epochs, acc_values, color='red', marker='+', label='Training accuracy')
plt.plot(epochs, loss_values, color='blue', marker='*', label='Training loss')
plt.plot(epochs, val_acc_values, color='black', marker='p', label='validation accuracy')
plt.plot(epochs, val_loss_values, color='black', marker='>', label='validation loss')
plt.title('Training and validation accuracy/loss')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
#plt.plot(color="blue",lebel="loss")
#plt.plot(color="red",lebel="accuracy")
plt.legend()
#plt.show()
plt.show(block=True)
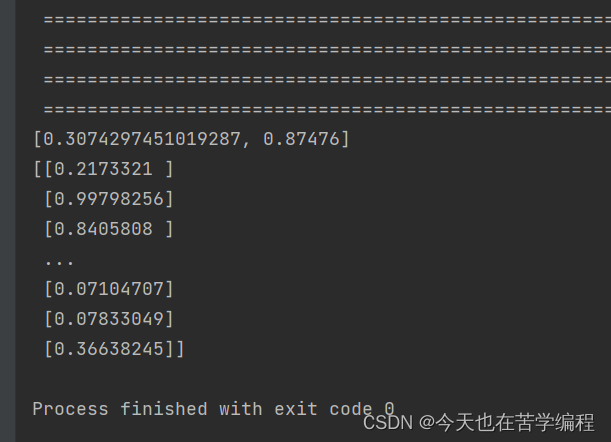
result = model.evaluate(x_test,y_test)
print(result)
predictResult = model.predict(x_test)
print(predictResult)
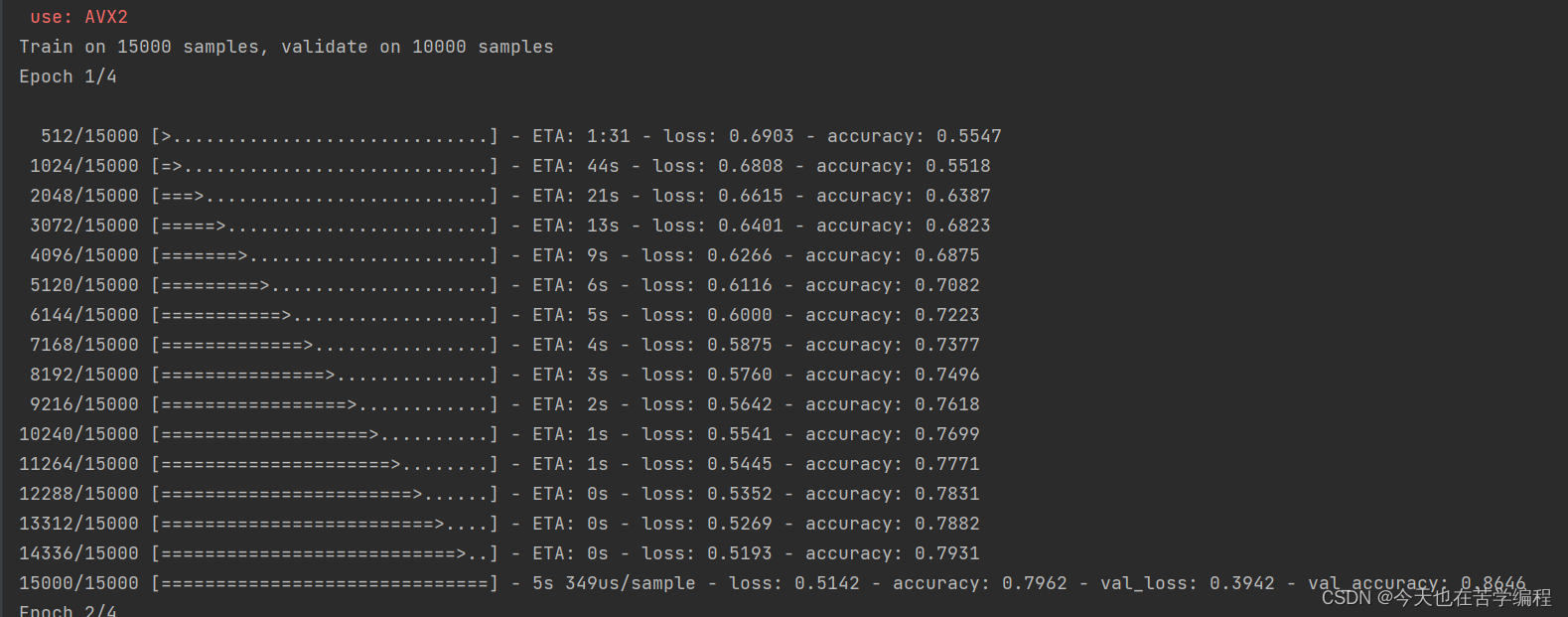
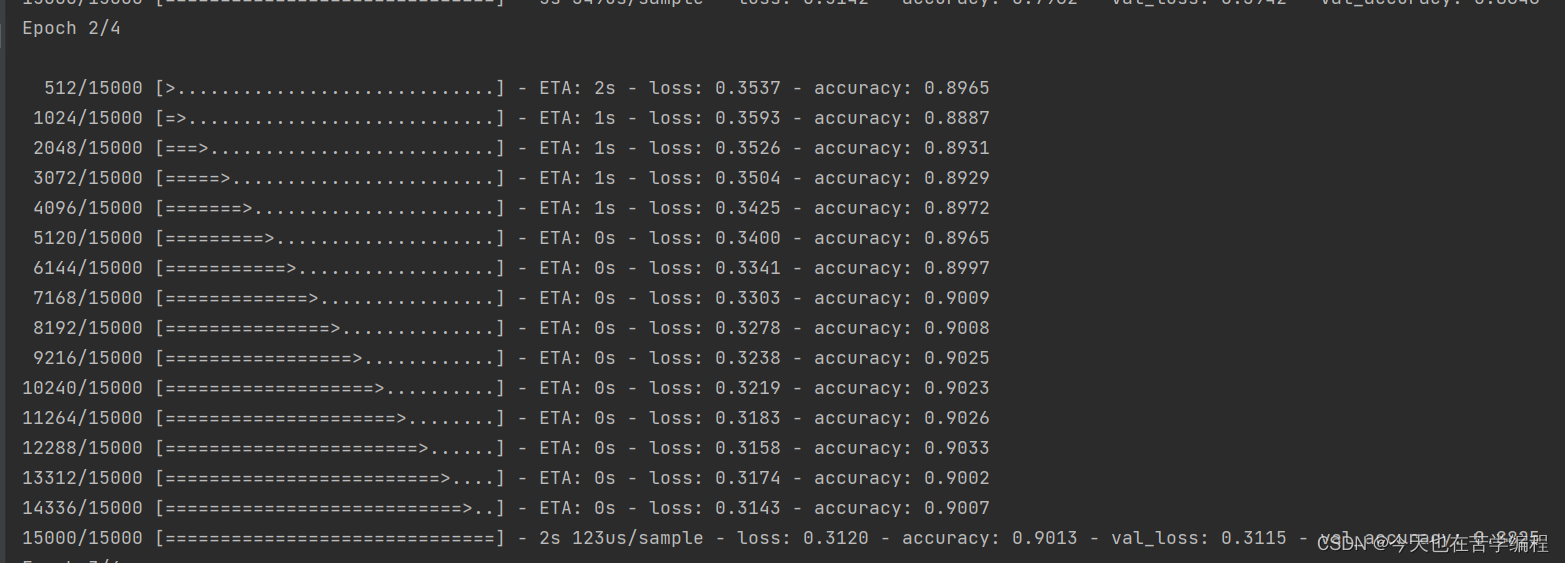
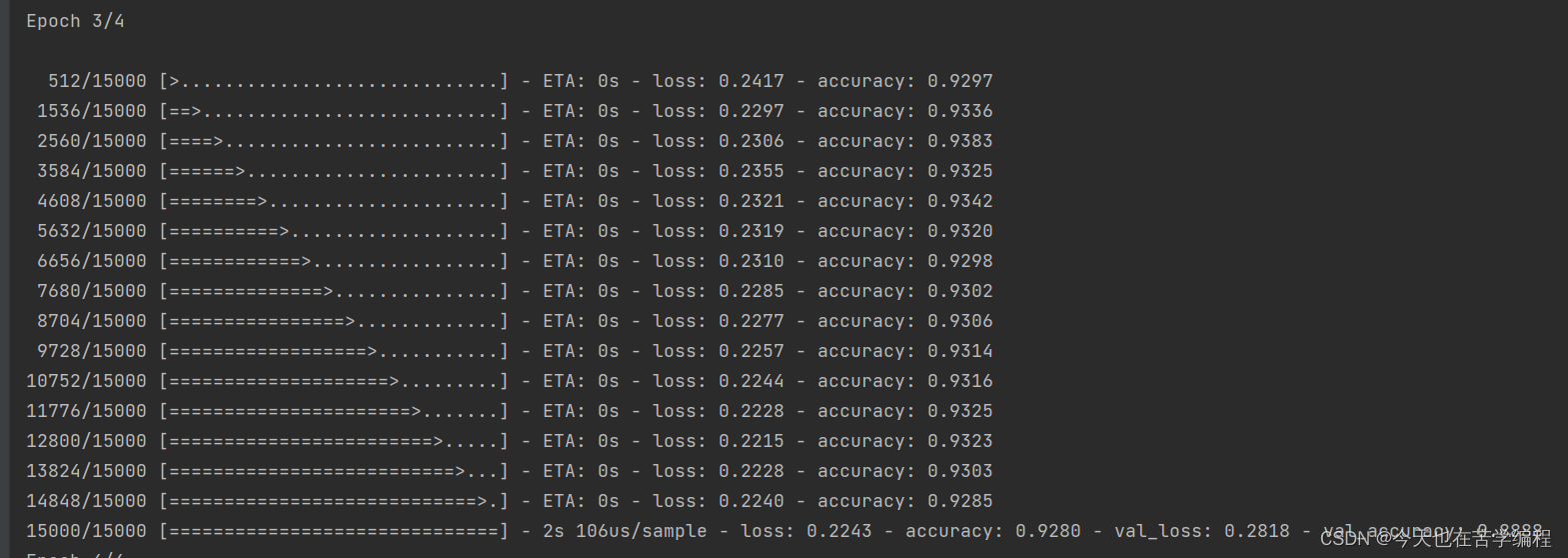
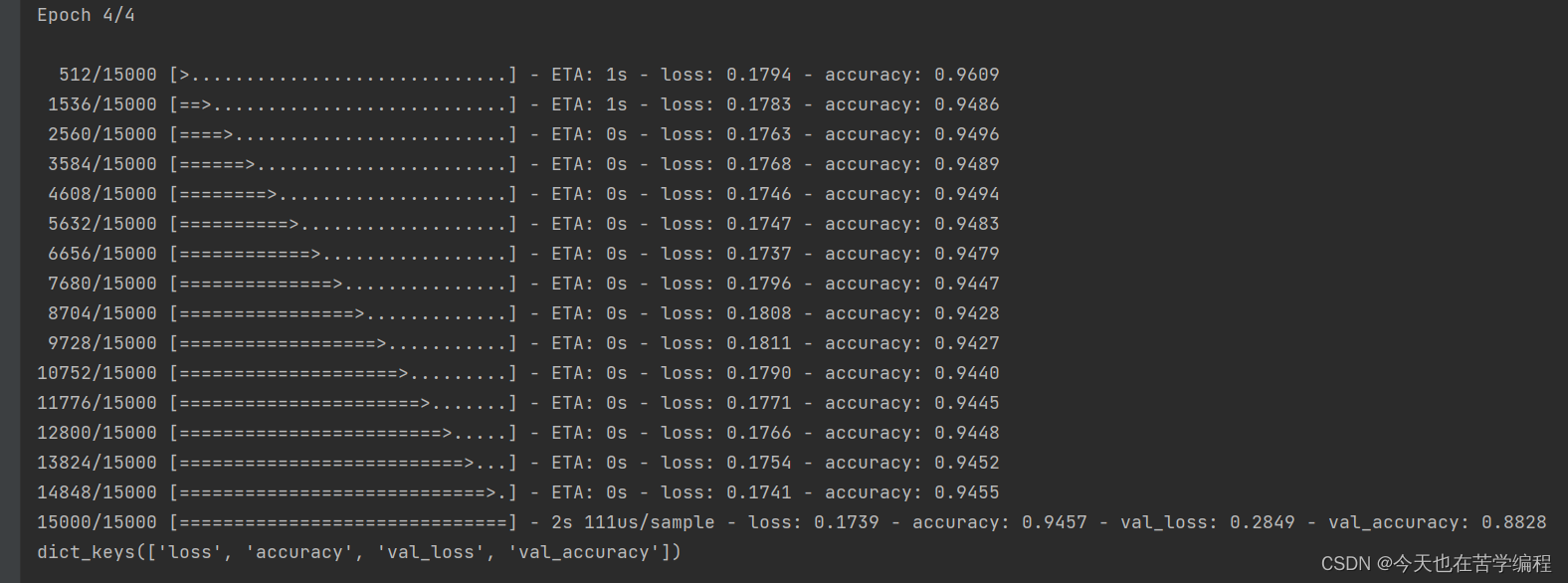
代码结果图:

















 2691
2691

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









