







 本文详细介绍了属性文法的基本概念,包括如何为文法符号分配属性,如何通过语义规则进行属性计算和传递。涵盖了S-属性文法和L-属性文法的区别,以及它们在语法分析树构建和语义计算中的应用,涉及树遍历、依赖图和不同类型的属性(综合和继承)。
本文详细介绍了属性文法的基本概念,包括如何为文法符号分配属性,如何通过语义规则进行属性计算和传递。涵盖了S-属性文法和L-属性文法的区别,以及它们在语法分析树构建和语义计算中的应用,涉及树遍历、依赖图和不同类型的属性(综合和继承)。
属性文法(属性翻译文法)
基本概念
在基础文法的基础上:
- 为每个文法符号(终结符或非终结符)配备相关属性,如类型、值、代码片段、符号表内容
- 对于文法的每个产生式都配备一组属性的语义规则(动作),对属性进行计算和传递

属性文法操作
- 对于给定输入串x,构建x的语法分析树,利用与产生式相关联的语义规则来计算分析树中各节点对应的语义属性值。
- 每个结点的属性值都标注出来的分析树,称为带注释的语法树。
综合属性
- 自下而上传递信息
- 语法规则:产生式左边符号的综合数学由右部符号的属性计算得出
- 语法树:父节点的综合属性由子节点的属性和父节点自身的属性计算得出
理解:自己的综合属性来自自己和自己的孩子们
非终结符的综合属性
可能由下面两部分组成
- 产生式左部非终结符的综合属性
- 产生式右部非终结符的综合属性
终结符的综合属性
- 终结符可以具有综合属性
- 终结符的综合属性是由词法分析器提供的词法值,因此在属性文法中没有计算终结符属性值的语义规则
继承属性
- 自上而下传递信息
- 语法规则:根据右部候选式中的符号的属性和左部符号的属性计算右部候选式中的符号的继承属性
- 语法树:根据父节点和兄长节点的属性计算子节点的继承属性
理解:自己的继承属性来自自己的爸爸和自己的兄弟们
语义规则总结
- 产生式右部符号的继承属性和产生式左部符号的综合属性由本产生式提供
- 产生式左部符号的继承属性和产生式右部符号的综合属性不由本产生式提供
语义规则的内容:
- 属性计算
- 静态语义检查
- 符号表操作
- 代码生成
- 给出错误信息
- 执行任何其他动作
带注释的语法树(仅含综合属性)
- 在语法树中,一个节点的综合属性的值由其子节点和它本身的属性确定
- 使用自底向上的方法在每个结点处使用语义规则计算综合属性的值
- 仅使用综合属性的属性文法称为S-属性文法
带注释的语法树(仅含继承属性)
- 在语法树中,一个节点的继承属性由父节点、其兄弟节点和其本身某些属性确定
- 不能在LR分析的同时构造带注释的语法树:先构造语法树、再计算属性
语义计算
- 语义规则的计算
- 产生代码
- 在符号表中存放信息
- 给出错误信息
- 执行任何其他动作
- 对输入串的翻译就是根据语义规则进行计算
语义计算的顺序:
输入串→语法树→按照语义规则计算属性
- 依赖图
- 树遍历
- 一遍扫描
属性依赖
- 对应于每一个产生式
A
→
α
A→\alpha
A→α都有一套与之相关联的语义规则,每条规则的形式为(f是一个函数):
b : f ( c 1 , c 2 , . . . , c k ) b:f(c_1,c_2,...,c_k) b:f(c1,c2,...,ck) - 属性b依赖于属性
c
1
,
c
2
,
.
.
.
,
c
k
c_1,c_2,...,c_k
c1,c2,...,ck
- b是A的一个综合属性并且 c 1 , c 2 , . . . , c k c_1,c_2,...,c_k c1,c2,...,ck是产生式右边文法符号的属性
- b是产生式右边某个文法符号的一个继承属性并且 c 1 , c 2 , . . . , c k c_1,c_2,...,c_k c1,c2,...,ck是A或产生式右边文法符号的属性
- 过程调用也当作属性
语义规则建立了属性之间的依赖关系,在对语法分析树节点的一个属性求值之前,必须首先求出这个属性值所依赖的所有属性值。
依赖图
- 依赖图是一个描述分析树中节点属性间依赖关系的有向图
- 分析树中每个标号为x的节点的每个属性a都对应着依赖图中的一个节点
- 如果属性X.a的值依赖于属性Y.b的值,则依赖图中有一条从Y.b的节点指向X.a的节点的有向边
树遍历算法
如何实现:
- 使用树的遍历方法来计算属性的值
- 假设语法树已经建立,并且树中已带有开始符号的继承属性和终结符的综合属性(人为开始符号的继承属性赋初值)
- 以某种次序遍历语法树,直至计算出所有属性
- 深度优先,从左到右的遍历
S-属性文法和L-属性文法
S-属性文法
仅包含综合属性的属性文法称为S-属性文法。
L-属性文法
- 当且仅当它的每个属性要么是一个综合属性,要么是满足如下条件的继承属性:
- 假设存在一个产生式
A
→
X
1
X
2
.
.
.
X
n
A→X_1X_2...X_n
A→X1X2...Xn ,其右部符号
X
i
(
1
≤
i
≤
n
)
X_i(1 \leq i \leq n)
Xi(1≤i≤n)的继承属性仅依赖于下列属性:
- A的继承属性
- 产生式中 X i X_i Xi左边的符号 X 1 X 2 . . . X n X_1X_2...X_n X1X2...Xn 的属性
- X i X_i Xi自身的属性,且 X i X_i Xi的全部属性不能在依赖图中形成环路
- 假设存在一个产生式
A
→
X
1
X
2
.
.
.
X
n
A→X_1X_2...X_n
A→X1X2...Xn ,其右部符号
X
i
(
1
≤
i
≤
n
)
X_i(1 \leq i \leq n)
Xi(1≤i≤n)的继承属性仅依赖于下列属性:
- S-属性文法是L-属性文法的一个特例
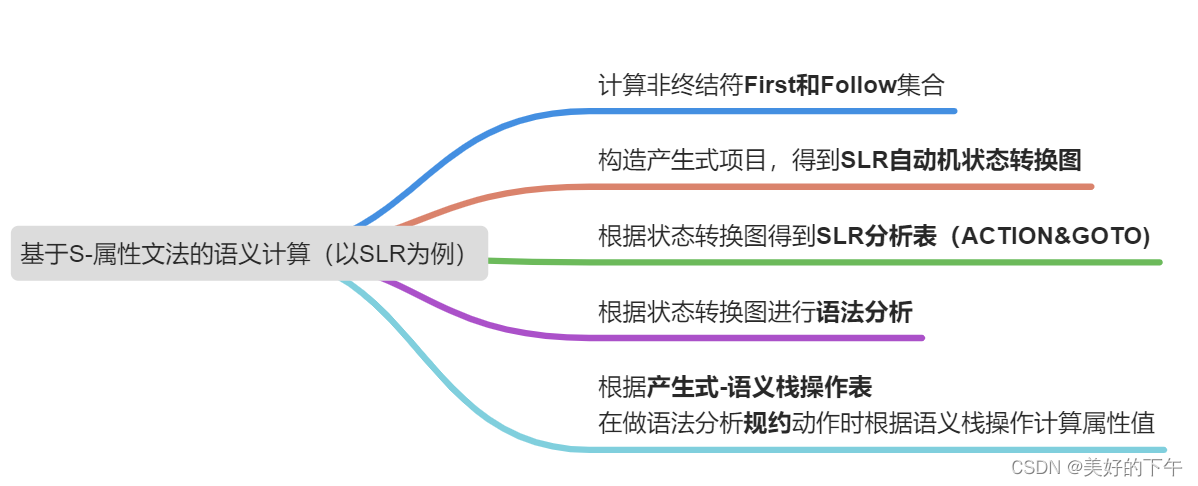
基于S-属性文法的语义计算
- 只包含综合属性
- 在自下而上的分析器分析输入符号串的同时计算综合属性
- 分析栈中保存语法符号、状态和有关的综合属性值
- 每当进行规约时,新的语法符号的属性值由栈中正在规约的产生式右边符号的属性值来计算
具体步骤:
- 在LR分析框架的基础上,在分析栈中增加附加域:语义栈(属性栈)
- 将语义规则(动作)改写成为具体可执行的栈操作
- 规约的时候执行语义规则的栈操作
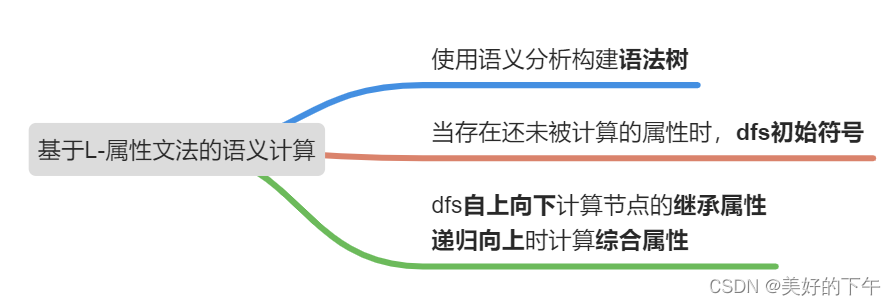
基于L-属性文法的语义计算
- 树遍历法
- 语法分析构建语法树,再深度优先,遍历语法树完成语义计算
while 还有未被计算的属性 do
VisitNode(S) - 深度优先,先使用图遍历算法自上向下计算每个非终结符的继承属性
- 在递归向上时计算所有能够计算的综合属性
- 语法分析构建语法树,再深度优先,遍历语法树完成语义计算

















 1003
1003

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









