
大数据
 关注
关注
 分享
分享
她與風皆過客
这个作者很懒,什么都没留下…
展开
专栏收录文章
- 默认排序
- 最新发布
- 最早发布
- 最多阅读
- 最少阅读
-
Shell总结
Shell基础原创 2022-11-06 18:19:41 · 307 阅读 · 0 评论 -
阿里云数据库Redis——本地客户端内网网连接
Redis内网连接原创 2022-10-16 16:39:36 · 584 阅读 · 0 评论 -
阿里云数据库Redis——本地客户端公网连接
阿里云数据库Redis——本地客户端公网连接原创 2022-10-16 16:35:53 · 387 阅读 · 0 评论 -
阿里大数据平台组件
阿里云计算大数据组件原创 2022-10-12 11:28:32 · 5898 阅读 · 0 评论 -
spark3.x 《自我总结》
spark四种运行模式:local Mode本地模式Standalone集群模式(伪分布式模式)Spark on Yarn 模式: 分为两种方式:Spark Client模式和Spark cluster模式mr-jobhistory-daemon.sh start historyserver yarn的历史服务器(HistoryServer)/export/server/spark/sbin/start-history-server.sh spark的历史服务器(JobHistoryServ原创 2022-05-06 10:37:27 · 468 阅读 · 0 评论 -
Docker容器安装部署MySQL
Docker官网https://www.docker.com/products/docker-hub拉取镜像docker pull mysql创建目录mkdir /tmp/mysql/datamkdir /tmp/mysql/conf挂载docker run -d --name mysql-test01 -p 3306:3306 --privileged=true -v /tmp/mysql/data:/var/lib/mysql -v /tmp/mysql/conf/hmy.c原创 2021-11-25 20:28:27 · 978 阅读 · 0 评论 -
Scala的高阶函数的使用
map函数语法:list.map(A=>B):List[B] final def map[B](f: (A) ⇒ B): List[B] //map函数只有1个参数,这个参数是一个函数类型 f: (A) ⇒ B:f就是参数函数 //f有1个参数:A:代表集合中的每个元素 //f的返回值:B:B是A处理以后的返回值 List[A].map = List[B] A1 -> B1 A2 -> B2 …… 栗子 val list1 = List(1,2,3,4原创 2021-04-12 13:49:50 · 244 阅读 · 1 评论 -
scala方法和函数
- - 方法:由方法名、参数、方法体构成,一般指的是类中定义的函数即为方法- 函数:由函数名、参数、函数体构成,一般指的是可以独立构建的称为函数方法def funcName(args1:Type1,args2:Type2……):ResultType = { //方法体}def m4(x:Int) = { if(x<= 1) 1 else m4(x-1)*x }函数函数的定义及语法规则(参数) => { //函数体}(x:Int,y:Int) => {原创 2021-04-12 11:52:02 · 131 阅读 · 0 评论 -
Scala基础语法
变量和常量变量的定义功能:定义一个值可变的变量 var name: String = "优快云" Scala中大多数场景下可以自动推断类型 var name= "优快云"常量的定义语法及测试 val aa:String = "csdn"初始值功能:用于构建一个变量时,指定初始值var 变量名称:数据类型 = _var a:string=_惰性赋值lazy val 常量名称:数据类型 = 值- 功能:构建一个常量时不直接赋值,只构建常量对象,当用到数据内容时,再真原创 2021-04-11 15:29:11 · 101 阅读 · 0 评论 -
Phoenix的二级索引实现
(一)关于二级索引因为Hbase的rowkey是唯一索引,无法满足大部分的需求,不能走rowkey索引,导致性能较差所以要构建二级索引来代替全表扫描(二)如何实现二级索引Phoenix底层封装了大量的协处理器来实现二级索引的构建- 1.根据数据存储需求 创建原始表 将数据写入表中- 2 根据业务需求 构建二级索引 Phoenix自动创建索引 -create index indexName on tbName(colName); -rowkey:name_id- 3查询数据时,Phoen原创 2021-03-24 18:25:07 · 391 阅读 · 0 评论 -
Phoenix与Hbase的关系
Phoenix的介绍功能Phoenix是一种专门针对于Hbase 所设计的SQL on Hbase 的一个工具使用SQL对Hbase进行操作使用phoenix自动构建二级索引来进行快速查询和维护原理- 上层提供了SQL接口 - 底层全部通过Hbase Java API来实现,通过构建一系列的Scan和Put来实现数据的读写- 功能非常丰富 - 底层封装了大量的内置的协处理器,可以实现各种复杂的处理需求,例如二级索引等特点- 优点 - 支持SQL接口 - 支持自动维原创 2021-03-24 17:09:38 · 1783 阅读 · 0 评论 -
分布式NoSQL列存储数据库Hbase
(一)数据采集- Flume:实时数据采集:采集文件或者网络端口- Sqoop:离线数据同步:采集数据库的数据(二)数据存储- HDFS:分布式离线文件存储系统- Hive:离线数据仓库- 将HDFS上的文件映射成了表的结构,让用户可以通过数据库和表的形式来管理大数据(三)数据计算- MapReduce+YARN:分布式离线数据计算- Hive:通过SQL进行分布式计算- 将SQL语句转换为MapReduce程序,提交给YARN运行(四)HBASE诞生 随着大数据的发展,大数据原创 2021-03-22 17:50:47 · 273 阅读 · 0 评论 -
Hbase的Java(DML)
import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.hbase.*;import org.apache.hadoop.hbase.client.*;import org.apache.hadoop.hbase.filter.*;import org.apache.hadoop.hbase.util.Bytes;import java.io.IOException;public class HbaseClie原创 2021-03-22 16:48:33 · 151 阅读 · 0 评论 -
Hbase的DML命令
DML命令——put插入/更新数据【某一行的某一列】(如果不存在,就插入,如果存在就更新)put NS名称:表的名称,'Rowkey','列族:列','值'功能及优点==功能==:插入 / 更新数据【某一行的某一列】- SQL - insert:用于插入一条新的数据 - update:用于更新一条数据 - replace:插入更新命令,如果不存在就插入,如果存在就更新 - 原理:先做判断,如果不存在,就直接插入,如果存在,就删除再插入- Hbase:put原创 2021-03-17 21:25:51 · 653 阅读 · 0 评论 -
Hbase的DDL命令
HBASE启动前置工作1.启动hdfs集群(start-dfs.sh)2.启动ZooKeeper集群(conf下zkserver.sh)3.启动HBASE集群(start-hbase.sh)命令进入HBASE命令(hbase shell)查看所有表(list)查看名字空间(类似于mysql的数据库名)(list_namespace)例举出一个名字空间下的所有表(list_namespace_tables ‘namespace名字’)创建名字空间(create_namespace原创 2021-03-17 20:44:48 · 673 阅读 · 0 评论 -
HUE安装部署
Hue 的安装(在子节点配置的)#1. HUE安装包下载地址: http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.14.0.tar.gz2.解压安装包cd /export/servers/ tar -zxvf hue-3.9.0-cdh5.14.0.tar.gz3.联网安装各种必须的依赖包yum install -y asciidoc cyrus-sasl-devel cyrus-sasl-gssapi cyrus-sasl-pla原创 2020-12-04 09:12:01 · 632 阅读 · 0 评论 -
Hive内部流程和架构图
hive可以理解为将HQL语句转换成MapReduce的原创 2020-12-04 08:32:55 · 382 阅读 · 0 评论 -
Hive的使用2
Hive常识Hive中没有定义专门的数据格式不需要从用户数据格式到 Hive 定义的数据格式的转换不会对数据本身进行任何修改,甚至不会对数据进行扫描不会对数据中的某些 Key 建立索引Hive 不适合在线数据查询Hive数据库、表在HDFS上存储的路径/user/hive/wearhouseHive 的数据库、数据表、分区 在HDFS上的存在形式是什么文件夹Hive和传统数据库的区别Hive延迟较高的原因Hive内部解析、编译等流程需要时间。提交任务后,提交到Yarn,Yar原创 2020-12-02 21:29:55 · 214 阅读 · 0 评论 -
Hive的交互及初步使用
Hive JDBC服务前提:假如有三台虚拟机,131,132,133假设在132节点启动hivecd /export/servers/hive-1.1.0-cdh5.14.0bin/hive --service hiveserver2(前台启动)cd /export/servers/hive-1.1.0-cdh5.14.0nohup bin/hive --service hiveserver2 &(后台启动)注意:前台和后台区别是 前台的可视化窗口关闭(例如:IDEA)原创 2020-11-16 22:58:47 · 223 阅读 · 0 评论 -
Hive的意义及其安装部署
1.Hive介绍1.1什么是HiveHive相当于是站在hdfs和MapReduce的肩膀上的工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能(HQL),其本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据的存储,hive可以理解为一个将SQL转换为MapReduce的任务的工具。1.2为什么使用Hive面临的问题: 人员学习成本太高 项目周期要求太短 MapReduce实现复杂查询逻辑开发难度太大 为什么要使用Hive 操作接原创 2020-11-16 22:27:15 · 448 阅读 · 0 评论 -
MapReduce之自定义输出
1.Drive驱动类package RecodReader;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.BytesWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.原创 2020-11-16 17:26:12 · 322 阅读 · 0 评论 -
MapReduce之自定义输入
1.驱动类 Drive代码package RecordWrite;import org.apache.hadoop.conf.Configuration;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.NullWritable;import org.apache.hadoop.io.Text;import org.apache.hadoop.mapreduce.Job;import org.apache.hadoop.原创 2020-11-16 17:18:04 · 302 阅读 · 0 评论 -
MapReduce之map的join算法实现
Mapimport org.apache.hadoop.filecache.DistributedCache;import org.apache.hadoop.fs.FSDataInputStream;import org.apache.hadoop.fs.FileSystem;import org.apache.hadoop.fs.Path;import org.apache.hadoop.io.LongWritable;import org.apache.hadoop.io.Text;i.原创 2020-11-04 20:59:05 · 192 阅读 · 0 评论 -
MapReduce之Reduce的Join算法实现
需求JavaBean类package Join.reduceJoin.Demo2;import org.apache.hadoop.io.Writable;import java.io.DataInput;import java.io.DataOutput;import java.io.IOException;public class JavaBean implements Writable { private String id; private String dat原创 2020-11-04 20:56:56 · 180 阅读 · 0 评论 -
MapReduce——本地跑MapReduce遇到的问题
Could not locate excutable…原因:JDK是32位的 卸载jdk安装64位的jdk即可安装步骤卸载JDK1.用控制面板搜索java然后点击卸载检查并彻底卸载:2.打开安装jdk安装目录检查是否还有残余文件3.按Windows键+R 输入"regedit"打开注册表编辑器 找到HKEY_LOCAL_MACHINE/SOFTWARE/JavaSoft 右键点击删除4.在C盘中Windows\System32和Windows\SysWOW64文件夹下找到j.原创 2020-10-30 20:40:15 · 245 阅读 · 0 评论 -
MapReduce——ClassCastException报错如何解决
前言今天用JavaBean封装数据的时候 发现 接口为Writable时 如果Map类中 输出的是JAVABean 会导致ClassCastException解决方法1.第一种书写JavaBean中的ToString方法 使用JavaBean的形式 无非就是使用了tostring方法 而不是在大量数据中进行数据拼接根据这样的思路 我将JavaBean在Map中就转成Text类型 输出给Reduce 这样 从Map输出开始 数据就以Text形式 而不是JAvabean形式2.第二种.原创 2020-10-30 20:30:43 · 652 阅读 · 0 评论 -
本人亲自尝试 ------数据块丢失该如何操作
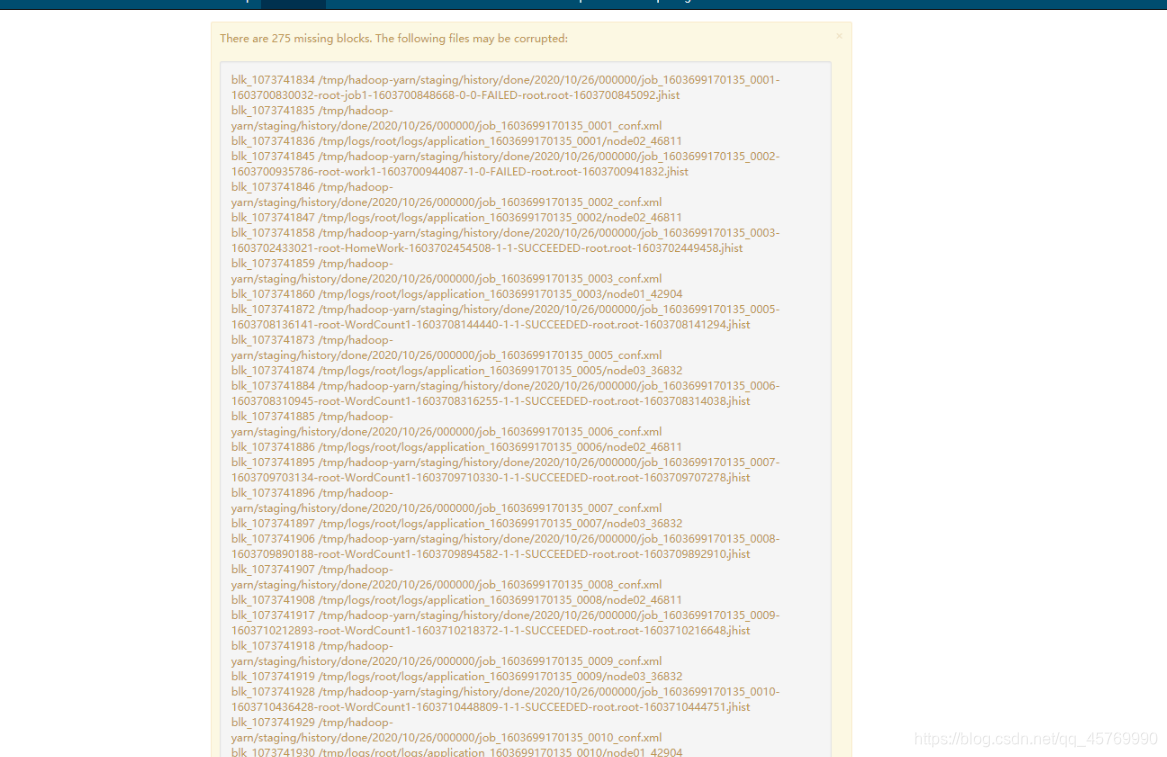数据块丢失显示在哪?IP地址:50070——>Overview方法原创 2020-10-30 20:19:39 · 275 阅读 · 0 评论 -
HDFS-HA集群搭建(搭建的时候,请仔细仔细再仔细!!!)
HA集群的搭建注意事项:1.修改Linux主机名2.修改IP3.修改主机名和IP的映射关系 /etc/hosts4.关闭防火墙5.ssh免登陆6.安装JDK,配置环境变量等7.注意集群时间要同步安装步骤:1.安装配置zooekeeper集群link2.安装配置hadoop集群link3.修改core-site.xml<configuration><!-- 集群名称在这里指定!该值来自于hdfs-site.xml中的配置 --><property原创 2020-10-26 16:10:18 · 282 阅读 · 0 评论 -
大数据ZooKeeper知识点
Apache ZooKeeper1.Zookeeper基本知识1.1.ZooKeeper概述Zookeeper是一个分布式协调服务的开源框架。主要用来解决分布式集群中应用系统的一致性问题。ZooKeeper本质上是一个分布式的小文件存储系统。提供基于类似于文件系统的目录树方式的数据存储,并且可以对树中的节点进行有效管理。从而用来维护和监控你存储的数据的状态变化。通过监控这些数据状态的变化,从而可以达到基于数据的集群管理。1.2.ZooKeeper特性1.全局数据一致:集群中每个服务器保存一份相原创 2020-10-20 18:04:41 · 195 阅读 · 0 评论 -
ZooKeeper集群搭建
1.安装jdk1、软件包的上传大到/export/soft2、加压安装包到/export/servers tar -zxvf jdk-8u65-linux-x64.tar.gz -C /export/servers/3、修改系统配置创建vi /etc/profile.d/java.sh文件,添加一下内容,保存并退出 export JAVA_HOME=/export/servers/jdk1.8.0_65export PATH=$PATH:$JAVA_HOME/bin4、使配原创 2020-10-19 18:03:10 · 172 阅读 · 0 评论 -
HDFS其他功能介绍
集群之间的数据拷贝distcpbin/Hadoop distcp hdfs://node01:8020/jdk-8u141-linux-x64.tar.gz hdfs://主机IP:8020/hdfs快照snapShot管理1、开启指定目录的快照功能hdfs dfsadmin -allowSnapshot 路径 2、禁用指定目录的快照功能(默认就是禁用状态)hdfs dfsadmin -disallowSnapshot 路径3、给某个路径创建快照snapshothdfs df原创 2020-10-18 16:46:26 · 205 阅读 · 0 评论 -
HDFS-web界面介绍
HDFS-Web界面介绍目标:掌握如何使用HDFS的Web浏览器了解集群登录HDFSWeb浏览器打开浏览器输入 http://node01:50070 (node01是NameNode所在的节点,或IP)Overview:集群概述Datanode::数据节点datanode-volume-failures: 数据节点卷故障snapshot: 快照startup-progress: 启动进度Started:启动Version:版本Compiled:已编译Cluster ID:原创 2020-10-18 16:41:08 · 2457 阅读 · 0 评论 -
HDFS的javaAPI操作
创建maven工程并导入jar包 <repositories> <repository> <id>cloudera</id> <url>https://repository.cloudera.com/artifactory/cloudera-repos/</url> </repository> </repositories> <dependenc原创 2020-10-18 16:33:57 · 113 阅读 · 0 评论 -
HDFS新增节点和退役节点
前言: 服役新数据节点目标:掌握HDFS新添加节点到集群的步骤需求基础: 随着公司业务的增长,数据量越来越大,原有的数据节点的容量已经不能满足存储数据的需求,需 要在原有集群基础上动态添加新的数据节点。、准备新的节点第一步:创建一台新的虚拟机出来第二步:IP地址第三步:关闭防火墙,关闭selinux service iptables stop第四步:更改主机名 vim /etc/sysconfig/network第五步:四台机器更改主机名与IP地址映射第六步:原创 2020-10-18 16:14:50 · 197 阅读 · 0 评论 -
HDFS系列讲解之Fsimage,Edits详解
HDFS高级使用命令数量限额hdfs dfs -mkdir -p /user/root/lisi #创建hdfs文件夹hdfs dfsadmin -setQuota 2 lisi # 给该文件夹下面设置最多上传两个文件,上传文件,发现只能上传一个文件hdfs dfsadmin -clrQuota /user/root/lisi # 清除文件数量限制空间大小限额hdfs dfsadmin -setSpaceQuota 4k /user/root/lisi # 限制空间原创 2020-10-18 15:50:53 · 1021 阅读 · 0 评论 -
hdfs的安全模式
安全模式是HDFS所处的一种特殊状态,在这种状态下,文件系统只接受读数据请求,而不接受删除、修改等变更请求。在NameNode主节点启动时,HDFS首先进入安全模式,DataNode在启动的时候会向namenode汇报可用的block等状态,当整个系统达到安全标准时,HDFS自动离开安全模式。 如果HDFS处于安全模式下,则文件block不能进行任何的副本复制操作,因此达到最小的副本数量要求是基于datanode启动时的状态来判定的,启动时不会再做任何复制(从而达到最小副本数量要求),hd..原创 2020-10-12 18:06:02 · 368 阅读 · 0 评论 -
hdfs的高级使用命令
HDFS文件限额配置hdfs文件的限额配置允许我们以文件大小或者文件个数来限制某个目录下上传的文件数量或者文件内容总量,以便达到我、们类似百度网盘网盘等限制每个用户允许上传的最大的文件的量1、文件夹内文件数量限制HDFS高级命令a)设置数量:hdfs dfsadmin -setQuota 2 /aab)取消设置:hdfs dfsadmin -clrQuota /aa2、文件夹内存储空间大小限制a)设置大小:hdfs dfsadmin -setSpaceQu原创 2020-10-12 18:03:46 · 256 阅读 · 0 评论 -
HDFS的特性
HDFS优点1、海量数据存储: HDFS可横向扩展,其存储的文件可以支持PB级别或更高级别的数据存储。2、高容错性:数据保存多个副本,副本丢失后自动恢复。可构建在廉价的机器上,实现线性扩展。当集群增加新节 点之后,namenode也可以感知,进行负载均衡,将数据分发和备份数据均衡到新的节点上。3、商用硬件:Hadoop并不需要运行在昂贵且高可靠的硬件上。它是设计运行在商用硬件(廉价商业硬件)的集群上的。4、大文件存储:HDFS采用数据块的方式存储数据,将数据物理切分成多个小的数据块。所以再大的数原创 2020-10-12 17:57:40 · 646 阅读 · 0 评论 -
HDFS的shell命令操作
常用命令实操1)查看hdfs某个文件夹的信息 hdfs dfs -ls +目录名2)在hdfs上创建目录hdfs dfs -mkdir -p + 路径3)从本地剪切粘贴到hdfshdfs dfs -moveFromLocal 本地文件夹路径 hdfs目标文件夹位置4)追加一个文件到已经存在的文件末尾hdfs dfs -appendToFile 原文件 hdfs中目标文件5)显示文件内容hdfs dfs -cat hdfs的文件6)显示文件的末尾hdfs df原创 2020-10-12 17:41:44 · 307 阅读 · 0 评论 -
DataNode的目录结构
和namenode不同的是,datanode的存储目录是初始阶段自动创建的,不需要额外格式化。在/export/servers/hadoop-2.6.0-cdh5.14.0/hadoopDatas/datanodeDatas/current这个目录下查看版本号[root@node01 current]# cat VERSION #Thu Mar 14 07:58:46 CST 2019storageID=DS-47bcc6d5-c9b7-4c88-9cc8-6154b8a2bf39cluste原创 2020-10-12 17:09:40 · 233 阅读 · 0 评论