







 本文探讨了平滑性假设在机器学习中的关键作用,包括手写数字识别、图像分类、文件分类及聚类任务。通过构建图结构,利用点间相似度衡量并传递属性,实现对未标记数据的有效利用。
本文探讨了平滑性假设在机器学习中的关键作用,包括手写数字识别、图像分类、文件分类及聚类任务。通过构建图结构,利用点间相似度衡量并传递属性,实现对未标记数据的有效利用。
Smoothness Assumption
smoothness用于定义数据的相似度:如果 x 1 x^1 x1和 x 2 x^2 x2在一个high density region上很接近的话,那么 y ^ 1 \hat y^1 y^1和 y ^ 2 \hat y^2 y^2就是相同的,也就是这两个点可以在样本点高密度集中分布的区域块中有一条可连接的路径(connected by a high density path)。
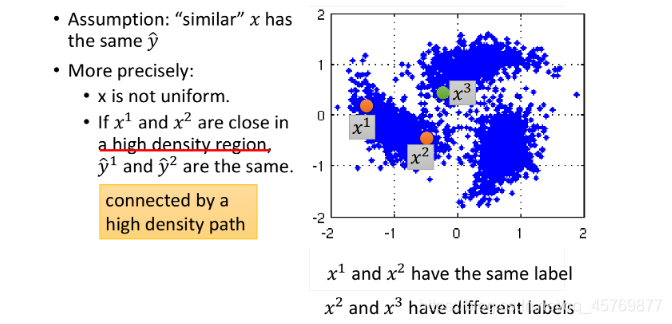
以上图data的分布为例,
x
1
,
x
2
,
x
3
x^1,x^2,x^3
x1,x2,x3是其中的三个样本点,虽然
x
2
x^2
x2和
x
3
x^3
x3距离更接近一些,以smoothness assumption的角度,
x
1
x^1
x1和
x
2
x^2
x2直接有一条high density path,意味着它们处于同一块区域的;而
x
2
x^2
x2与
x
3
x^3
x3之间则是断开的,因此
x
1
x^1
x1和
x
2
x^2
x2应该有相同的label。
digits detection
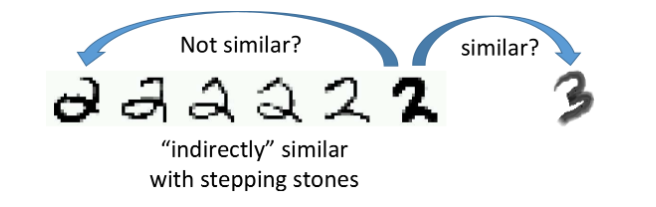 手写数字过渡 手写数字过渡
|
 人脸过渡 人脸过渡
|
以手写数字识别为例,对于最右侧的2和3以及最左侧的2,显然最右侧的2和3在pixel上相似度更高一些;但如果考虑所有连续变化的2都放进来,就会产生一种“不直接相连的相似”,根据Smoothness Assumption的理论,由于2之间有连续过渡的形态,因此第一个2和最后一个2是比较像的,而最右侧2和3之间由于没有过渡的data,因此它们是比较不像的。
file classification
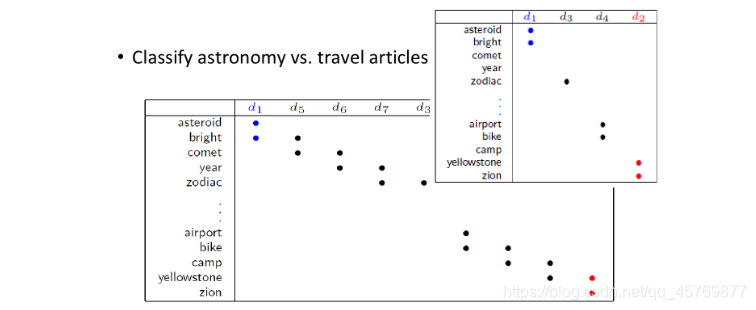
Smoothness Assumption在文件分类上是非常有用的,假设对天文学(astronomy)和旅行(travel)的文章进行分类,它们各自有专属的词汇,此时如果unlabeled data与label data的词汇是相同或重合(overlap)的,那么就很容易分类;但在真实的情况下,unlabeled data和labeled data之间可能没有任何重复的words,sparse的分布很难会使overlap发生,但如果unlabeled data足够多,就会以一种相似传递的形式,建立起文档之间相似的桥梁。
cluster
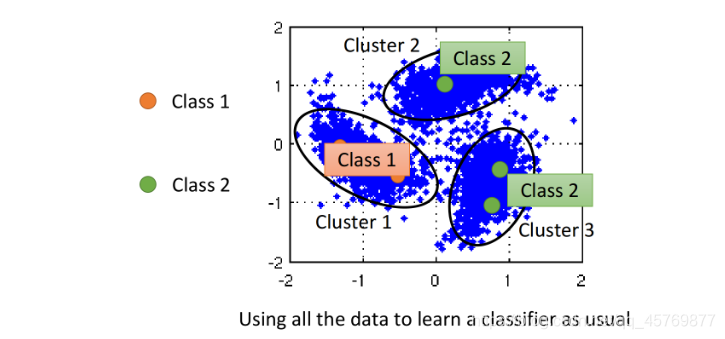
Smoothness Assumption也可用于做聚类,对图像分类来说,如果单纯用pixel的相似度来划分cluster得到的结果一般很差,先对image提取特征后(Autoencoder),cluster才会有效果。
Graph-based Approach
Graph Structure可以直观描述Smoothness这件事,即connected by a high density path。
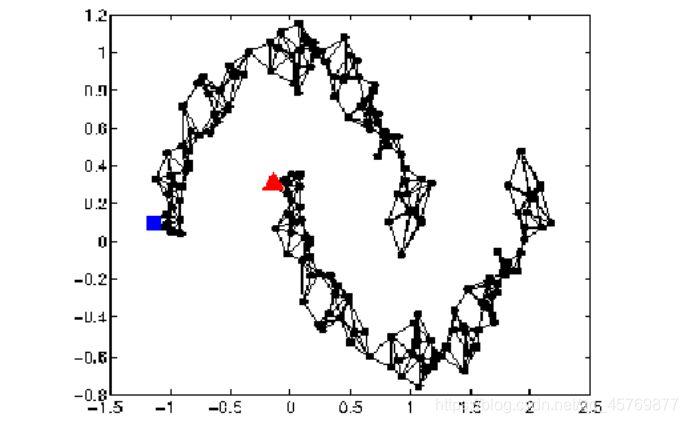
我们把所有的data points构建成一个graph,并建立点与点之间的关系,比如网页之间的链接关系、论文之间的引用关系,graph的好坏对结果起着至关重要的影响,但build graph这件事需要凭着经验和直觉来做。
build graph
- 计算不同point x i , x j x^i,x^j xi,xj之间的相似度 s ( x i , x j ) s(x^i, x^j) s(xi,xj)
- 定义neighbor并建立edge:(两种方法)
- k nearest neighbor:每个point与相似度最接近的k个点建立edge
- e-neighborhood:每个point与相似度超过threshold e的点建立edge
- 对每条edge,附上权值——与对应相似度 s ( x i , x j ) s(x^i,x^j) s(xi,xj)成正比
RBM function确定相似度
s
(
x
i
,
x
j
)
=
e
−
γ
∣
∣
x
i
−
x
j
∣
∣
2
s(x^i,x^j)=e^{-\gamma||x^i-x^j||^2 }
s(xi,xj)=e−γ∣∣xi−xj∣∣2
- 计算 x i , x j x^i,x^j xi,xj的欧几里得距离并加上参数后再去exponential。
exponential通常是可以帮助提升performance的,在这里只有当 x i , x j x^i,x^j xi,xj非常接近的时候,singularity才会大;只要距离稍微远一点,singularity就会下降得很快,变得很小。使用exponential的RBM function可以做到只有非常近的两个点才能相连,稍微远一点就无法相连的效果,避免跨区域相连的情况。
Graph-based Approach的基本精神
在原有graph上已经有一些labeled data,那么跟它们相连的point,属于同一类的概率就会上升,每一笔data都会去影响它的邻居,而graph带来的最重要的好处是,这个影响是会随着edges传递出去的,即使有些点并没有真的跟labeled data相连,也可以被传递到相应的属性。
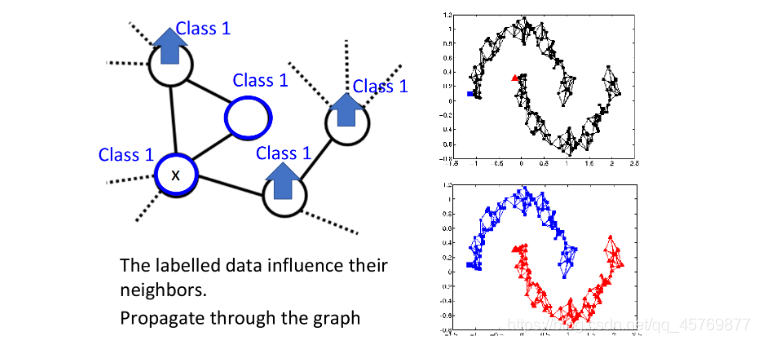
如果graph建的足够好,那么两个被分别label为蓝色和红色的点就可以传递出两个high density path;但如果想要让这种方法生效,收集到的data一定要足够多,能够让information的传递。
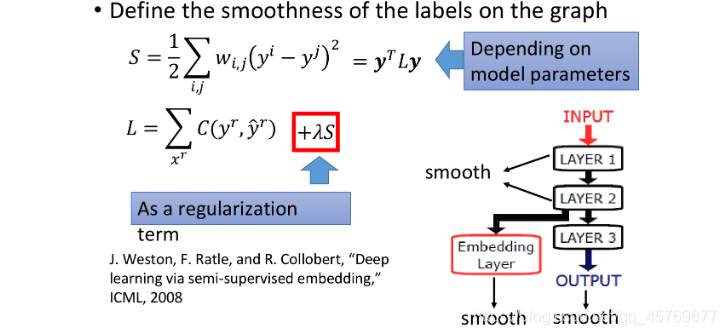
high density path smoothness定量计算
S
=
1
2
∑
i
,
j
w
i
,
j
(
y
i
−
y
j
)
2
S=\frac{1}{2}\sum\limits_{i,j} w_{i,j}(y^i-y^j)^2
S=21i,j∑wi,j(yi−yj)2
- y i y^i yi y j y^j yj:相邻两点的label
- w i , j w_{i,j} wi,j:相邻两点的边权值,即相似度

smoothness的矩阵方式计算
graph smoothness可以改写为:
S
=
1
2
∑
i
,
j
w
i
,
j
(
y
i
−
y
j
)
2
=
y
T
L
y
S=\frac{1}{2}\sum\limits_{i,j} w_{i,j}(y^i-y^j)^2=y^TLy
S=21i,j∑wi,j(yi−yj)2=yTLy
-
y
y
y label vector:所有data(labeled data
+
+
+unlabeled data)的label组成(R+U)-dim vector
形式: y = [ . . . y i . . . y j . . . ] T y=\left [\begin{matrix} ...y^i...y^j... \end{matrix} \right ]^T y=[...yi...yj...]T -
L
L
L Graph Laplacian:是(R+U)×(R+U) matrix,, 定义为
L
=
D
−
W
L=D-W
L=D−W
- W:把data point两两之间weight的关系建成matrix,代表了 x i x^i xi与 x j x^j xj之间的weight值
- D:把W的每一个row上的值加起来放在该行对应的diagonal上即可,比如5=2+3,3=2+1,…

loss function
使用neural network训练,loss funcation:
L
=
∑
x
r
C
(
y
r
,
y
^
r
)
+
λ
S
L=\sum\limits_{x^r}C(y^r,\hat y^r) + \lambda S
L=xr∑C(yr,y^r)+λS
- ∑ x r C ( y r , y ^ r ) \sum\limits_{x^r}C(y^r,\hat y^r) xr∑C(yr,y^r):labeled data的cross entropy越小越好
- λ S \lambda S λS:smoothness S越小越好
具体训练的时候,不一定只局限于neural network的output要smooth,可以对中间任意一个hidden layer加上smooth的限制。同时对于图像建议使用autoencoder提取出来的feature来计算相似度,而不是基于pixel的相似度。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









